경량 초안 모델을 활용한 대형 언어 모델 불확실성 추정
초록
**
본 논문은 대형 언어 모델(LLM)의 에피스테믹 불확실성을, 무거운 딥 앙상블 없이도 경량 초안(draft) 모델들의 집합을 이용해 효율적으로 추정하는 프레임워크를 제안한다. 편향‑분산 분해를 통해 초안 간 Jensen‑Shannon 발산을 분산 프록시, 초안 혼합과 목표 모델 간 KL 발산을 편향 프록시로 정의하고, 온라인 스토캐스틱 디스틸레이션(OSD)과 데이터‑다양성 초안(DDD) 전략으로 초안 다양성을 강화한다. GSM8K 실험에서 RMSE를 최대 37 % 감소시키고, 비용이 큰 TokUR과 동등한 hallucination 탐지 성능을 보이며 추론 비용을 최소화한다.
**
상세 분석
**
이 연구는 에피스테믹 불확실성(EU)이 모델 파라미터에 대한 사후 분포의 다양성에서 비롯된다는 베이지안 관점을 재조명한다. 기존 딥 앙상블은 수십~수백 개의 거대한 모델을 동시에 실행해야 하므로 메모리·연산 비용이 폭발적으로 증가한다. 저자는 이러한 문제를 “초안 모델”이라는 경량 버전들을 활용해 해결한다. 초안 모델은 사전‑학습된 대형 모델의 파라미터를 축소하거나, 데이터 양을 제한하거나, 구조를 단순화한 형태로, 스펙큘러 디코딩에서 후보 토큰을 제시하는 역할을 이미 수행하고 있다. 논문은 초안 모델들을 서로 독립적인 사후 샘플이라고 가정하고, 이들의 예측 분포 집합을 목표 모델의 사후 평균(p_T)와 비교한다.
핵심 이론적 기여는 두 단계로 나뉜다. 첫째, 목표 모델의 EU는 KL(p_θ‖p_T)의 기대값으로 정의되며, 이를 초안 혼합 q_mix에 대한 KL 기대값으로 상한을 만든다(EU + KL(p_T‖q_mix)). 둘째, 초안 모델들을 균등하게 샘플링한다는 “프록시 사후 가정” 하에, EU를 두 개의 계산 가능한 항으로 분해한다.
- 분산 프록시: 각 초안 q_k와 혼합 q_mix 사이의 KL 평균, 즉 Jensen‑Shannon Divergence(JSD)이다. 초안 간 의견 차이가 클수록 모델이 학습 데이터에 대해 불확실함을 의미한다.
- 편향 프록시: q_mix와 목표 모델 p_T 사이의 KL이다. 초안이 목표 모델을 충분히 근사하지 못하면 편향이 커진다.
이 두 프록시를 동시에 최소화하면, 초안 집합이 목표 모델의 사후를 잘 대변하면서도 다양성을 유지한다는 점에서 기존의 온‑폴리시 디스틸레이션(예: GKD, MiniLLM)과 차별화된다. 온‑폴리시 방법은 학생 모델을 목표에 과도하게 맞추어 모드 붕괴를 일으키지만, 저자는 **Online Stochastic Distillation(OSD)**을 도입해 초안을 순차적으로 목표 모델의 출력에 맞추되, 매 스텝마다 무작위 샘플링을 적용해 초안이 서로 다른 모드에 머무르게 한다.
또한 Data‑Diverse Drafts(DDD) 전략을 제안한다. 학습 데이터셋을 K개의 서로 겹치지 않는 서브셋으로 분할하고, 각 초안을 해당 서브셋만으로 미세조정한다. 이렇게 하면 초안 간 구조적·통계적 차이가 자연스럽게 생겨 JSD가 증가하고, 편향 프록시가 크게 악화되지 않도록 목표 모델과의 KL을 지속적으로 모니터링한다.
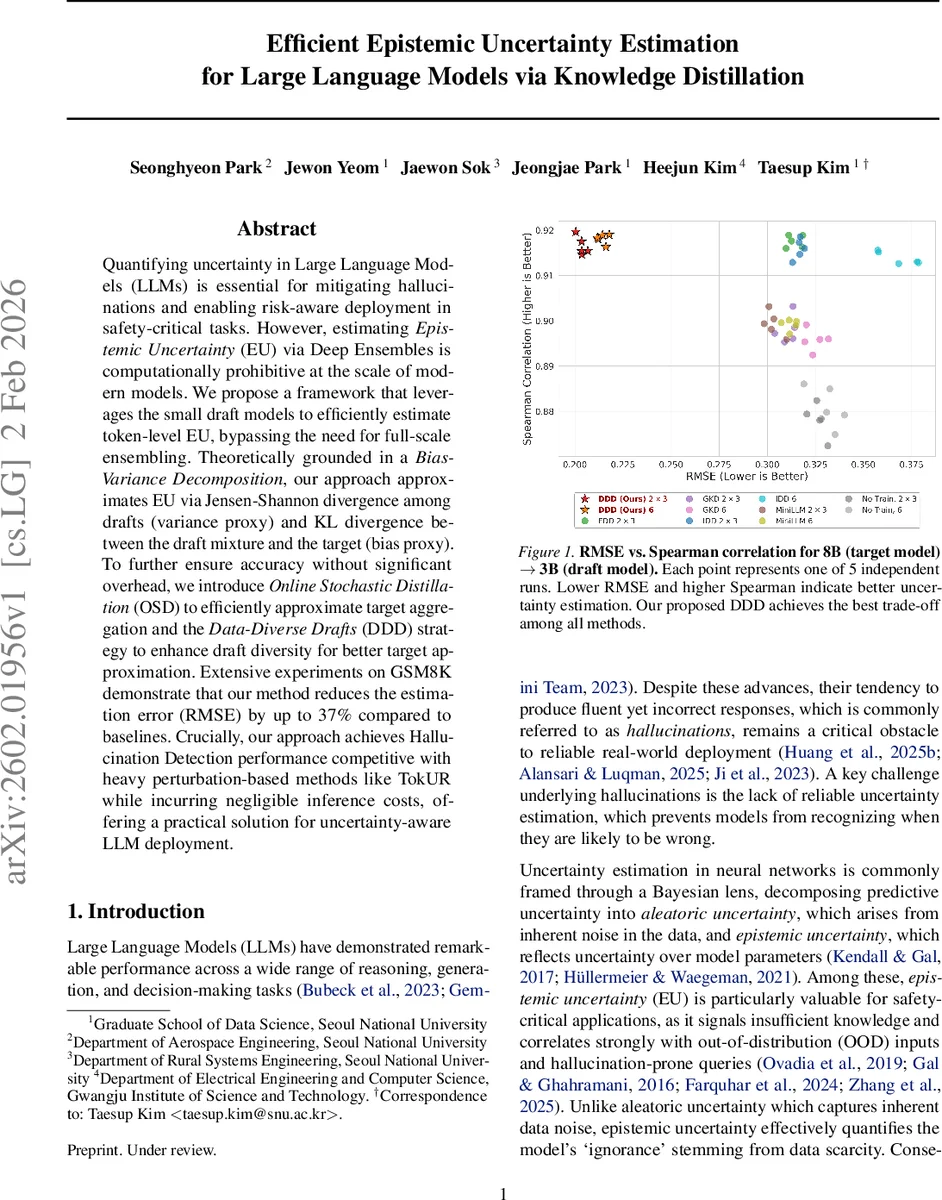
실험에서는 8B 파라미터 목표 모델과 3B 초안 모델을 사용해 GSM8K 수학 문제 풀이에서 토큰‑레벨 EU를 추정한다. RMSE 기준으로 기존 딥 앙상블 대비 37.67 % 감소, Spearman 상관계수도 크게 향상되었다. Hallucination detection에서는 토큰‑레벨 불확실성을 활용해 오류 토큰을 조기에 차단했으며, 비용이 높은 TokUR(LoRA 기반 파라미터 교란)과 비슷한 AUROC를 기록했다. 추론 비용은 초안 모델들의 병렬 실행과 단일 목표 모델 검증으로 구성돼, 전체 파이프라인이 기존 스펙큘러 디코딩 대비 5 % 이하의 오버헤드만 추가한다.
결과적으로 이 논문은 “경량 초안 모델 = 베이지안 사후 샘플”이라는 새로운 해석을 제시하고, 편향‑분산 분해를 통한 정량적 EU 추정 방법을 제공함으로써, 대규모 LLM을 안전하게 운영하기 위한 실용적인 도구를 마련했다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기