대변형 흉부 CT 정합을 위한 LDRNet: 빠르고 정확한 딥러닝 모델
초록
**
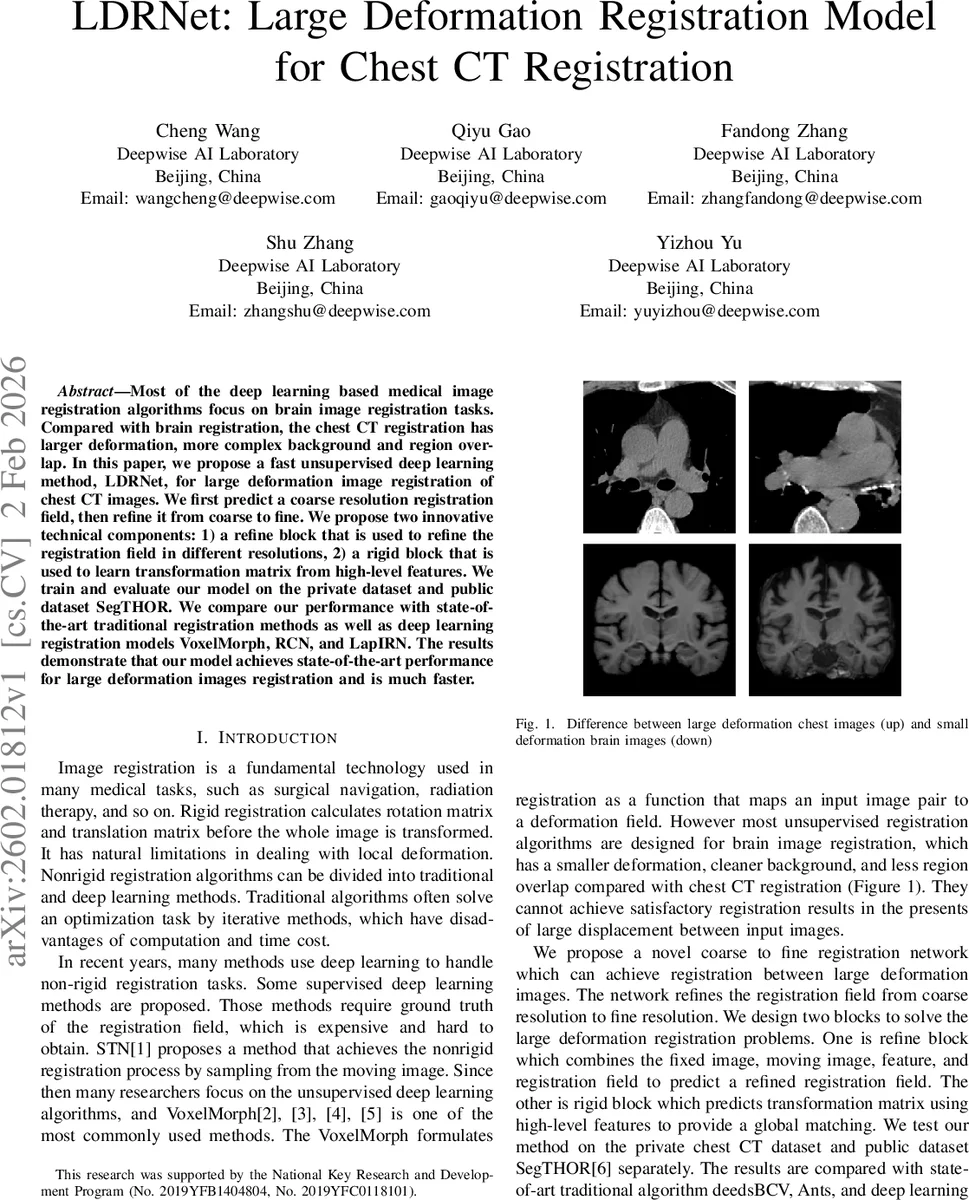
LDRNet은 흉부 CT 영상의 대규모 변형을 효율적으로 정합하기 위해 설계된 비지도 딥러닝 프레임워크이다. 저해상도에서 전역 변환을 추정하고, 단계별 refine block을 통해 점진적으로 고해상도 변형장을 보정한다. rigid block은 고수준 특징으로 회전·이동 행렬을 학습해 전역 정합을 강화한다. 공개 SegTHOR와 자체 구축한 682건의 흉부 CT 데이터셋에서 기존 전통적 방법(ANTs, deedsBCV) 및 최신 딥러닝 모델(VoxelMorph, RCN, LapIRN)보다 Dice 점수와 연산 속도 모두 우수함을 입증하였다.
**
상세 분석
**
LDRNet은 “coarse‑to‑fine” 전략을 핵심으로 하는 3D 정합 네트워크이다. 입력으로 고정(F)와 이동(M) 이미지를 채널 차원으로 결합한 뒤, 다중 스케일 특징을 추출하는 encoder‑decoder 구조를 사용한다. 가장 큰 특징은 두 가지 전용 블록이다.
1️⃣ Refine Block은 현재 스케일의 특징, 평균‑풀링된 이미지, 이전 단계에서 업샘플된 변형장 ϕ₍i‑1₎, 그리고 그 변형장을 적용해 얻은 warped 이미지 M(ϕ)₍i₎를 모두 결합한다. 차이 텐서 D₍i₎=M(ϕ)₍i₎−F₍i₎를 포함함으로써 변형 전후의 잔차를 직접 학습한다. 이후 3D Conv‑LeakyReLU‑BN 레이어를 통해 Δϕ₍i₎를 예측하고, ϕ₍i₎=˜ϕ₍i‑1₎+Δϕ₍i₎ 형태로 변형장을 점진적으로 정교화한다. 이 설계는 단순 UNet 업샘플링과 달리 변형 전후의 상관관계를 명시적으로 이용해 대변형 상황에서도 안정적인 수렴을 가능하게 한다.
2️⃣ Rigid Block은 가장 높은 레벨의 추상 특징을 이용해 전역 회전 행렬 R∈ℝ³ˣ³와 이동 벡터 t∈ℝ¹ˣ³를 직접 예측한다. 특징 맵을 3D Conv → Max‑Pooling → 1D 벡터로 압축한 뒤, 두 개의 FC 브랜치를 통해 R과 t를 회귀한다. 예측된 R·t는 가장 저해상도 변형장 ϕₙ에 적용돼 전통적인 ‘rigid pre‑registration’ 역할을 수행한다. 변형장을 변환함으로써 이미지와 특징의 정합성을 유지하고, 이후 refine 단계에서 잔차를 최소화한다.
Loss 설계는 MSE 기반 similarity와 두 종류의 정규화(L_range, L_smooth)를 결합한다. L_range는 변형장의 절대값을 제한해 좌표가
댓글 및 학술 토론
Loading comments...
의견 남기기