데이터 이질성 연합 학습을 위한 LoRA 재고: 서브스페이스와 상태 정렬
초록
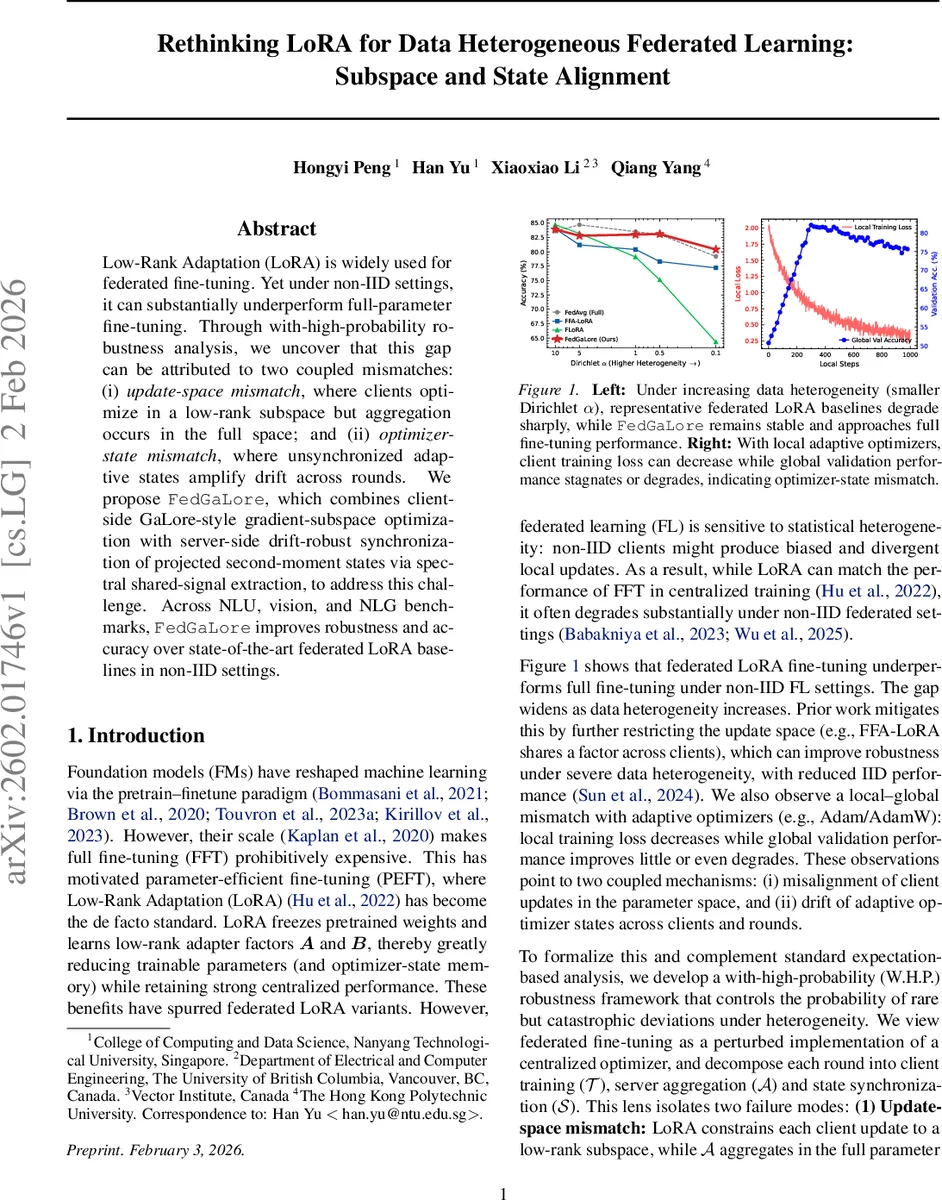
본 논문은 비IID 환경에서 연합 학습에 사용되는 Low‑Rank Adaptation(LoRA)이 전체 파라미터 미세조정(FFT)보다 성능이 크게 저하되는 원인을 두 가지 불일치, 즉 업데이트 서브스페이스 불일치와 옵티마이저 상태 불일치로 규명한다. 이를 해결하기 위해 클라이언트 측에서는 GaLore 방식의 그래디언트 서브스페이스 최적화를, 서버 측에서는 투영된 2차 모멘트 상태를 스펙트럴 공유 신호 추출(AJIVE)로 동기화하는 FedGaLore를 제안한다. 실험 결과, NLU·비전·NLG 전 분야에서 비IID 데이터 분포에 대한 강인성과 정확도가 기존 연합 LoRA 방법들을 크게 능가한다.
상세 분석
이 논문은 연합 학습(Federated Learning, FL)에서 파라미터 효율성을 위해 널리 채택된 LoRA가 데이터 이질성(Non‑IID) 상황에서 기대 이하의 성능을 보이는 근본 원인을 두 가지 메커니즘으로 정량화한다. 첫 번째는 업데이트‑서브스페이스 불일치이다. LoRA는 각 클라이언트가 저‑랭크 행렬 A·B 형태의 어댑터만 학습하도록 제한하지만, 서버에서는 이 저‑랭크 업데이트를 풀 파라미터 공간에 그대로 평균한다. 저‑랭크 매니폴드(M_r)의 코디멘션이 크기 때문에, 클라이언트 업데이트가 이 매니폴드 주변의 얇은 튜브에 머물 경우, 평균 연산이 매니폴드 밖으로 벗어나게 되어 손실이 급격히 증가한다. 두 번째는 옵티마이저‑상태 불일치이다. 클라이언트가 Adam/AdamW와 같은 적응형 옵티마이저를 사용하면, 1차 모멘트(m)와 2차 모멘트(v)와 같은 내부 상태가 클라이언트마다 다르게 축적된다. 서버가 이러한 상태를 동기화하지 않으면, 로컬 트레이닝 단계(T)에서 발생한 드리프트가 적응형 프리컨디셔너에 의해 증폭돼 전역 모델이 불안정한 궤도를 그리게 된다. 논문은 이러한 두 현상을 with‑high‑probability (W.H.P.) 프레임워크 안에서 분석한다. 즉, 기대값 기반 수렴이 아니라 전체 학습 경로가 확률 1‑δ 수준에서 안정적인 영역 Q 안에 머무르는지를 보장한다. 이를 위해 저자는 Local Containment와 Aggregation Stability라는 두 성공 이벤트를 정의하고, 각각이 깨질 확률을 상한화한다. 특히, 업데이트‑서브스페이스 불일치는 고차원 기하학(Weil’s tube formula)을 이용해 저‑랭크 매니폴드 주변 볼륨이 전체 파라미터 공간에 비해 급격히 작아짐을 정량화한다. 옵티마이저‑상태 불일치는 클라이언트‑서버 간 2차 모멘트(v)만을 저‑랭크 형태로 투영하고, 서버에서 AJIVE(공유 신호 추출) 기법으로 공통 성분을 추출해 동기화함으로써 해결한다. 이 과정은 통신 비용을 최소화하면서도 drift‑robust한 프리컨디셔너를 제공한다. 제안된 FedGaLore는 클라이언트 측에서 GaLore 스타일의 gradient‑subspace 최적화를 적용해, 매 단계마다 현재 그래디언트를 저‑랭크 서브스페이스에 투영하고, 이 서브스페이스를 적응적으로 업데이트한다. 이렇게 하면 LoRA가 갖는 파라미터 효율성은 유지하면서도, 업데이트가 전체 파라미터 공간에 더 잘 정렬된다. 서버 측에서는 각 클라이언트가 전송한 저‑랭크 투영 2차 모멘트를 집계해 공유 신호를 추출하고, 이를 다음 라운드의 초기 상태로 브로드캐스트한다. 실험에서는 NLU(예: GLUE), 비전(CIFAR‑10/100, ImageNet‑mini) 및 NLG(예: GPT‑2 기반 텍스트 생성) 벤치마크에서 Dirichlet α를 조절해 데이터 이질성을 다양하게 만들었으며, FedGaLore는 α가 작아질수록 급격히 성능이 하락하는 기존 LoRA 변형들을 크게 능가하고, 거의 Full‑Parameter Fine‑Tuning(FFT) 수준의 정확도를 유지한다. 또한, 로컬 AdamW 사용 시 훈련 손실은 감소하지만 전역 검증 정확도가 정체되는 현상이 사라져, 옵티마이저‑상태 동기화가 실제로 drift를 억제함을 입증한다. 전체적으로 논문은 서브스페이스 정렬과 상태 정렬이라는 두 축을 통해 LoRA 기반 연합 학습의 근본적인 한계를 극복하고, 통신·연산 효율성을 유지하면서도 비IID 환경에 강인한 학습을 가능하게 만든다.
댓글 및 학술 토론
Loading comments...
의견 남기기