에이투이밸 자동화된 에이전트 기반 임베디드 모델 평가
초록
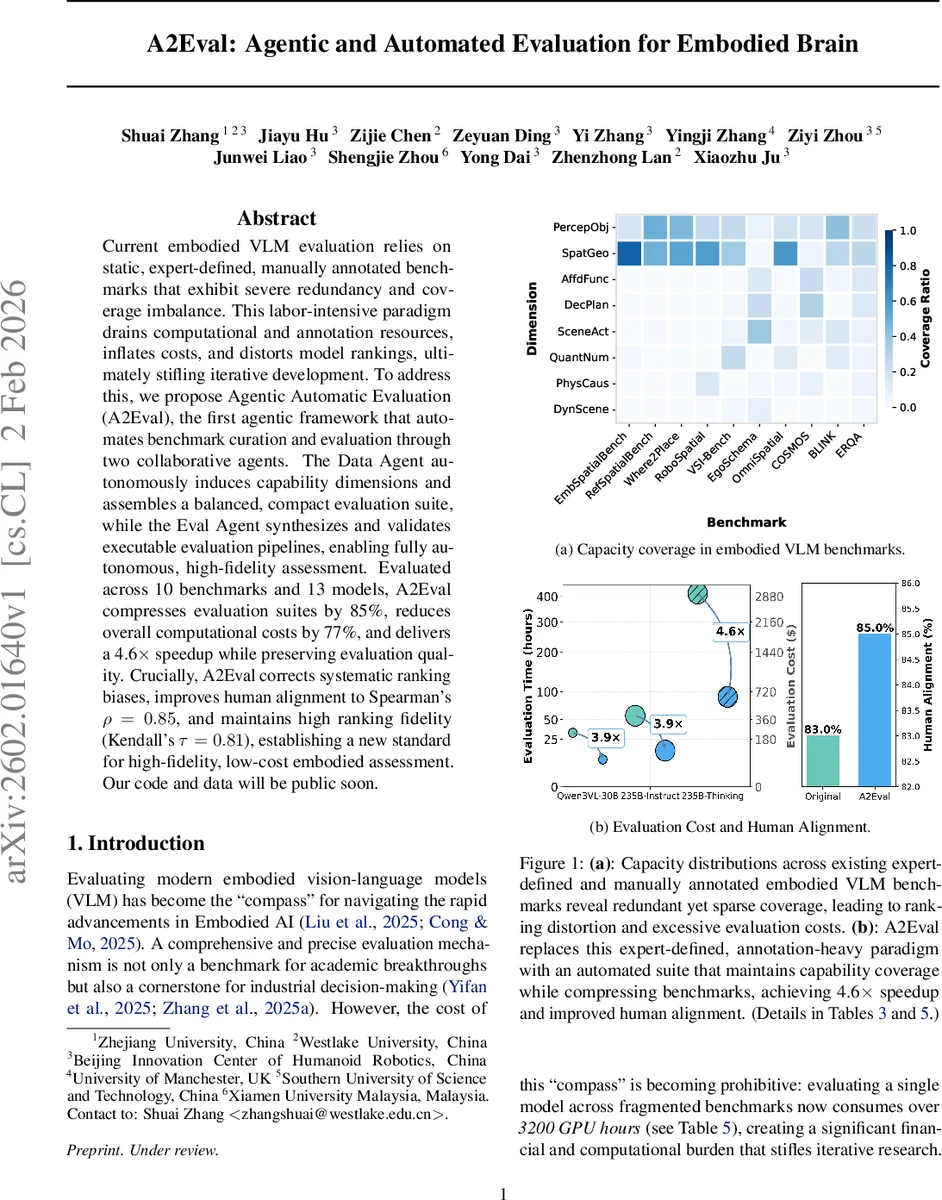
A2Eval은 두 개의 협업 에이전트(데이터 에이전트와 평가 에이전트)를 활용해 기존의 정적·수동 벤치마크를 자동으로 축소·재구성하고, 실행 가능한 평가 파이프라인을 자동 생성한다. 10개의 벤치마크와 13개 모델 실험에서 평가 비용을 77% 절감하고, 85% 중복 샘플을 제거하면서도 인간 선호와의 정렬을 0.85(Spearman)까지 끌어올렸다.
상세 분석
A2Eval은 현재 임베디드 비전‑언어 모델(VLM) 평가가 겪는 세 가지 근본적 문제—커버리지 불균형·중복, 순위 왜곡, 높은 평가 비용—를 해결하기 위해 ‘에이전트 기반 자동화’라는 새로운 패러다임을 제시한다.
1️⃣ 데이터 에이전트는 ‘제안자(Proposer)’, ‘리뷰어(Reviewer)’, ‘배정자(Assigner)’라는 세 역할을 가진 LLM 에이전트들로 구성된다. 제안자는 기존 벤치마크 메타데이터를 기반으로 후보 능력 차원을 생성하고, 리뷰어는 차원의 중복성, 도메인 커버리지, 균형성을 평가해 비판을 제공한다. 배정자는 실제 예시를 차원에 할당하고, 클러스터 기반 다양성‑인식 샘플링을 통해 각 차원당 K개의 대표 샘플만 남긴다. 이 과정을 메모리 M에 기록된 히스토리와 함께 반복함으로써 차원 집합 D가 수렴할 때까지 최적화한다. 결과적으로 8개의 주요 차원(PercepObj, SceneAct, SpatGeo, QuantNum, AffdFunc, PhysCaus, DecPlan, DynScene)이 도출되고, 원본 24,519개의 샘플이 3,781개(≈85% 감소)로 압축된다.
2️⃣ 평가 에이전트는 ‘평가자(Evaluator)’와 ‘채점자(Scorer)’ 두 역할을 맡는다. 평가자는 모델 M과 압축된 테스트 셋 T에 대한 추론 코드를 자동 생성하고, 샌드박스 실행기 X를 통해 실행 가능성을 검증한다. 오류가 발생하면 X가 반환하는 진단 정보를 바탕으로 코드를 반복 개선한다. 채점자는 모델 출력 P에 대한 평가 로직을 동일한 방식으로 합성·검증한다. 최종적으로 검증된 추론 로직 Fe와 채점 로직 Fs가 확보되면, 전체 파이프라인이 자동으로 실행돼 차원별 성능 메트릭을 산출한다.
3️⃣ 실험 결과는 10개의 공개 임베디드 벤치마크(Where2Place, VSI‑Bench 등)와 13개의 최신 모델(Qwen‑VL, InternVL 등)을 대상으로 수행되었다. A2Eval은 평가 시간 평균 4.6배 가속, GPU 사용량 77% 절감, 그리고 기존 전체 평가와 비교해 96.9%의 순위 일관성을 유지했다. 특히, 기존 평가에서 과도히 강조된 ‘Spatial & Geometric Reasoning’ 같은 차원의 편향을 완화해, 인간 선호와의 Spearman ρ를 0.85까지 끌어올렸다. Kendall τ 역시 0.81로 높은 순위 충실도를 보였다.
4️⃣ 기술적 기여는 (1) 완전 자동화된 벤치마크 구축 프레임워크, (2) 차원‑기반 중복 제거와 다양성‑인식 샘플링을 통한 비용‑효율적인 평가 세트, (3) LLM‑기반 코드 합성·검증 루프를 통한 실행 가능한 평가 파이프라인 제공이다. 이는 기존 ‘전문가 정의 + 수동 라벨링’ 방식의 병목을 해소하고, 임베디드 AI 연구와 산업 현장에서 빠른 모델 반복과 객관적 비교를 가능하게 만든다.
댓글 및 학술 토론
Loading comments...
의견 남기기