LLM과 연산자 추론을 결합한 파라메트릭 PDE 솔버
초록
OpInf‑LLM은 소량의 시뮬레이션 데이터로 공유된 저차원 기저와 파라메터 의존 연산자를 학습한 뒤, 대형 언어 모델(LLM)의 자연어 파싱 및 툴 호출 능력을 이용해 새로운 파라메터와 경계조건을 가진 PDE를 자동으로 구성·통합·해석한다. 이 접근은 실행 성공률을 높이면서도 높은 수치 정확도를 유지해, 기존 코드 생성형 LLM 솔버와 순수 데이터‑기반 신경망 서러게이트의 한계를 극복한다.
상세 분석
OpInf‑LLM은 두 단계로 구성된다. 오프라인 단계에서는 전통적인 연산자 추론(OpInf) 기법을 활용해 파라메트릭 PDE 군에 대해 공통된 POD 기반을 구축하고, 각 학습 파라메터 ξ에 대해 선형·이차 연산자 A(ξ), H(ξ), B(ξ), c(ξ)를 최소제곱 방식으로 추정한다. 이때 데이터는 전체 공간‑시간 스냅샷과 그 시간미분을 포함하며, POD는 에너지 보존을 최적화하는 좌측 특이벡터를 선택해 차원을 r으로 축소한다. 파라메트릭 확장은 기존 OpInf 연구와 일치하게, 연산자들을 다항식 회귀(polynomial regression)로 매핑함으로써 미관측 파라메터에 대한 연산자를 빠르게 예측한다.
온라인 단계에서는 LLM이 “ν=0.03인 Burgers 방정식을 풀어라”와 같은 자연어 명령을 해석한다. LLM은 사전 정의된 툴(예: polynomial_regression, ode_integration)을 호출해 요구된 파라메터 ξ에 대한 연산자를 생성하고, 저차원 ODE da/dt = A(ξ)a + H(ξ)(a⊗a) + B(ξ)u + c(ξ) 를 적분한다. 적분 결과인 모달 계수 a(t) 를 공유 기저 Φ에 투사해 전체 해 y(x,t,ξ) 를 복원한다. 이 흐름은 코드 자동 생성이 필요 없으며, 실행 환경에 직접적인 의존성을 최소화한다는 장점이 있다.
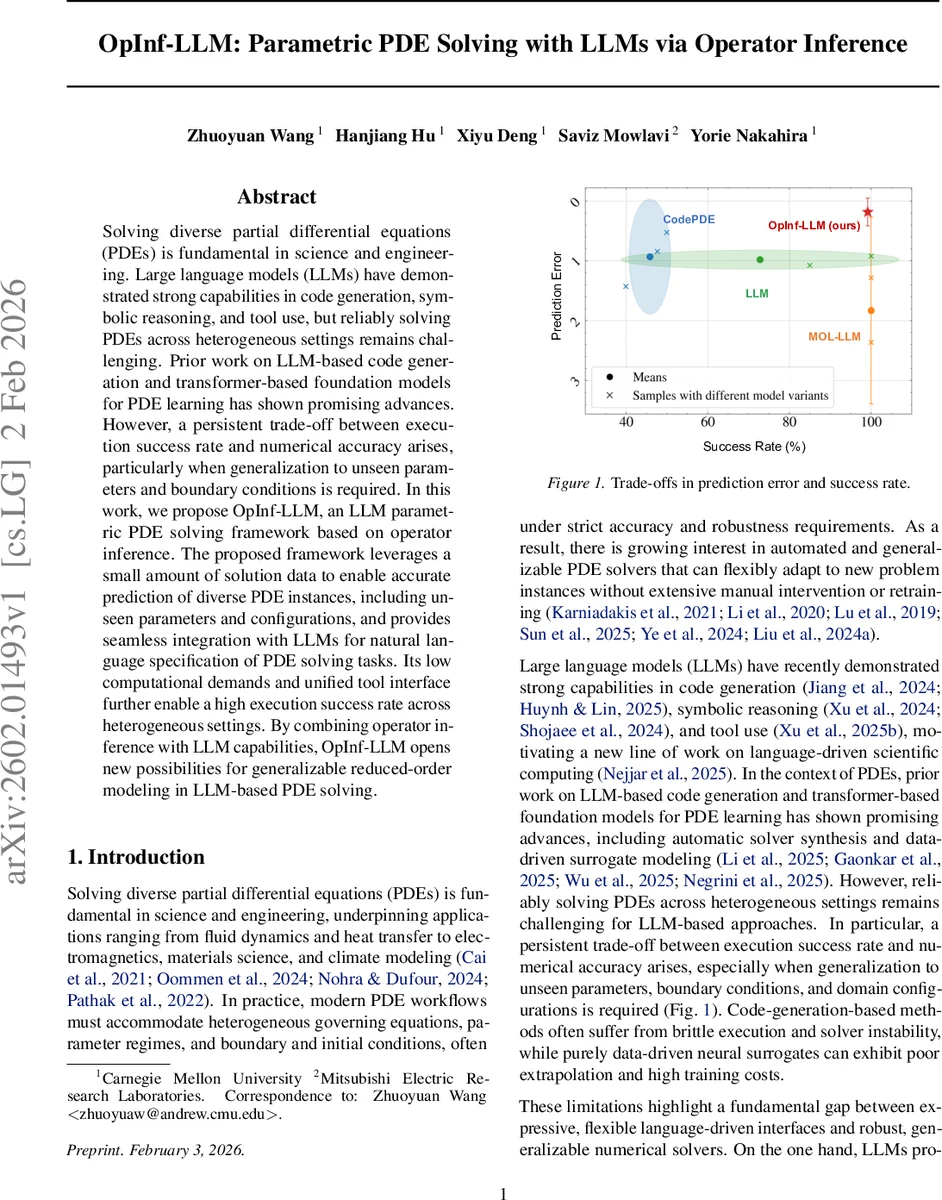
핵심 기술적 기여는 다음과 같다. 첫째, 연산자 추론을 LLM 기반 인터페이스와 결합해 파라메터와 경계조건을 자연어로 지정할 수 있게 함으로써 과학적 컴퓨팅의 접근성을 크게 높였다. 둘째, 연산자 회귀와 저차원 ODE 적분이라는 두 단계만으로 복잡한 PDE를 해결하므로, 실행 성공률이 기존 CodePDE·LLM‑MOL 등 코드 생성형 방법보다 현저히 높다. 셋째, 소량의 고품질 시뮬레이션 데이터만으로도 다양한 파라메터 영역에 대해 정확한 예측을 수행한다(Zero‑shot generalization).
한계점도 존재한다. 현재 구현은 2차 비선형(Quadratic) 형태에 최적화돼 있어, 고차 비선형이나 비다항식 연산자를 포함하는 Navier‑Stokes, 반응‑확산 시스템 등에 직접 적용하기 위해서는 연산자 구조를 확장하거나 커스텀 피처를 도입해야 한다. 또한 POD 기반 차원 축소는 고차원 3D 문제에서 스냅샷 수집과 SVD 비용이 급증할 수 있다. LLM의 툴 호출 정확도는 프롬프트 설계와 모델 크기에 민감하므로, 오류 검증 및 재시도 메커니즘이 필요하다. 마지막으로, 파라메터 회귀 단계에서 다항식 차수를 어떻게 선택하느냐에 따라 과적합 위험이 존재한다.
전반적으로 OpInf‑LLM은 전통적인 물리‑기반 모델 축소와 최신 LLM 기술을 효과적으로 융합함으로써, 파라메트릭 PDE 해결에 있어 “정확도 vs 실행 성공률” 트레이드오프를 크게 완화한다는 점에서 의미가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기