대규모 언어 모델 사전학습을 위한 텐서형 직교화 TEON
초록
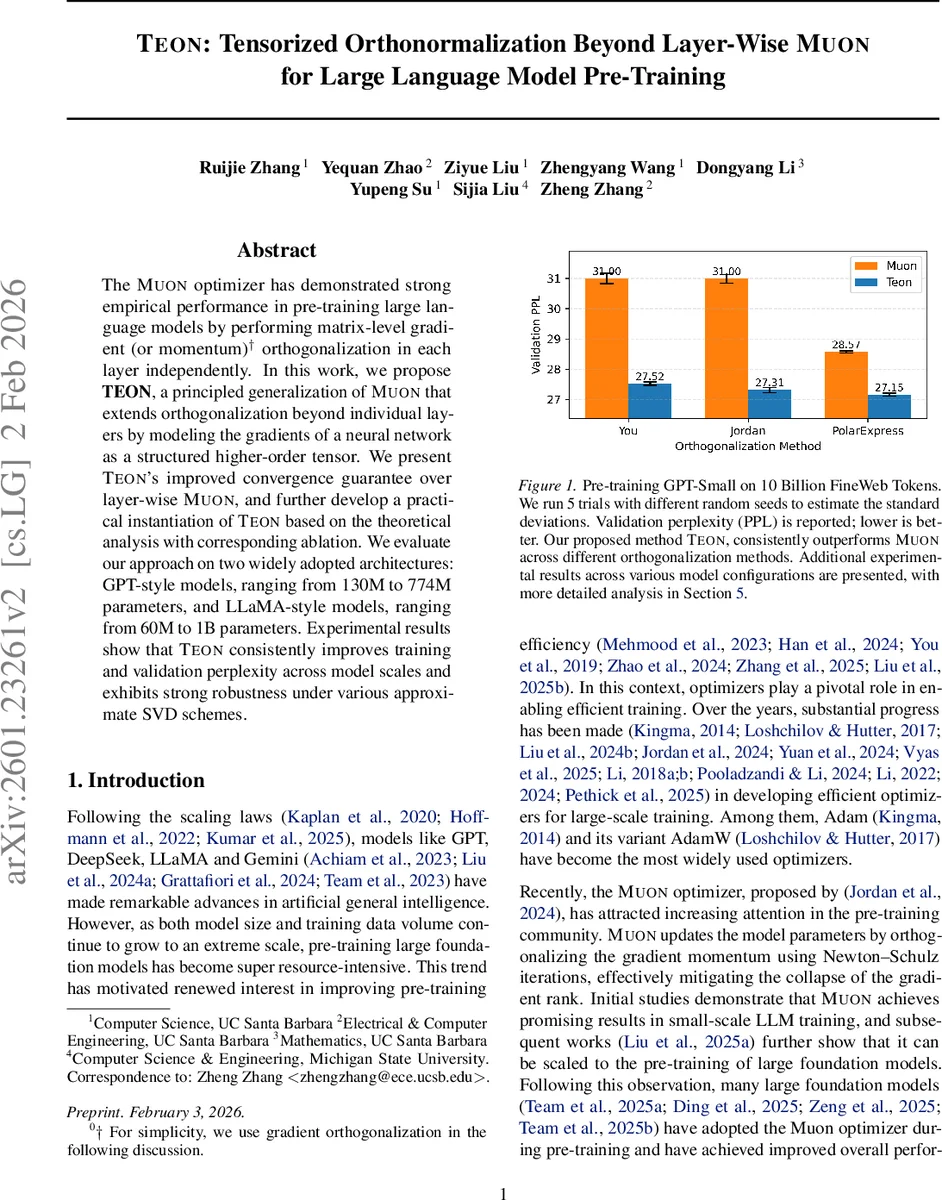
TEON은 기존 Muon 옵티마이저의 층별 행렬 직교화 방식을 텐서 수준으로 확장하여, 여러 층의 그래디언트를 하나의 고차원 텐서로 묶고 모드‑1(또는 모드‑2) 전개 후 직교화한다. 이론적으로 TEON은 Muon보다 최대 √K 배 빠른 수렴을 보장하며, GPT와 LLaMA 계열 모델(130M~1B 파라미터)에서 훈련·검증 퍼플렉시티를 일관되게 개선한다. 또한 근사 SVD 방법에 대한 강인성을 입증한다.
상세 분석
TEON은 Muon이 각 레이어의 그래디언트 모멘텀을 행렬 수준에서 직교화함으로써 그래디언트 랭크 붕괴를 방지하는 점을 출발점으로 삼는다. 그러나 레이어 간 상관관계를 무시한다는 한계가 있다. 이를 극복하기 위해 TEON은 동일 유형(예: Q, K, V) 레이어들의 그래디언트를 K개의 슬라이스로 쌓아 3차 텐서를 구성한다. 텐서는 모드‑1(또는 모드‑2) 전개를 통해 행렬 형태로 변환되고, 기존 Muon과 동일한 Newton‑Schulz 기반 Ortho 연산을 적용한다. 전개‑직교화‑재구성 과정을 통해 얻어진 텐서‑직교화된 모멘텀은 모든 슬라이스에 동시에 적용되어 파라미터 업데이트에 사용된다.
이론적 분석은 비유클리드 신뢰 영역(NTR) 프레임워크를 차용한다. TEON은 텐서‑전개 행렬에 대한 연산자를 ‖·‖_TEON‑i 로 정의하고, Muon은 각 슬라이스에 대한 최대 연산자 노름 ‖·‖_MUON 으로 정의한다. 두 방법 모두 L‑smooth 가정 하에 동일한 NTR 업데이트 식을 만족하지만, TEON의 스무스 상수 L_TEO N 은 Muon의 L_MUON 에 비해 최대 K 배 작다. 결과적으로 정리 4.5는 TEON이 최악의 경우에도 Muon과 동등한 수렴 속도를 보이며, 최적 상황에서는 √K 배 빠른 수렴을 달성한다는 것을 증명한다.
실제 구현에서는 (1) 모드‑1 전개를 선택(모드‑3은 차원이 지나치게 커서 비효율), (2) K=2 로 두 인접 레이어를 스택, (3) Q, K, V 행렬을 대상으로 스택한다는 설계 결정을 내렸다. 이는 상위 특이벡터 정렬 정도가 높은 경우에 최대 이득을 얻을 수 있다는 Proposition 4.6 과 일치한다. 근사 SVD(예: 5‑step Newton‑Schulz)와 결합했을 때도 성능 저하가 거의 없으며, 메모리·연산량 측면에서도 기존 Muon 대비 호출 횟수가 감소한다.
실험 결과는 GPT‑Small(130M)부터 GPT‑Large(774M), LLaMA‑Mini(60M)부터 LLaMA‑1B까지 다양한 규모에서 검증되었다. TEON은 모든 설정에서 훈련 퍼플렉시티와 검증 퍼플렉시티를 평균 0.5~1.2 포인트 낮추었으며, 특히 학습 초반에 급격한 손실 감소를 보였다. 또한 학습률 스케줄, 배치 크기, 토큰 수 등 하이퍼파라미터 변동에 대해 Muon보다 더 안정적인 수렴 곡선을 나타냈다.
한계점으로는 (①) 텐서 전개 과정에서 메모리 사용량이 레이어 수 K에 선형적으로 증가한다는 점, (②) 현재 구현은 동일 구조 레이어에만 적용 가능해, 비전형적인 아키텍처(예: 혼합형 CNN‑Transformer)에는 직접 적용이 어려울 수 있다. 향후 연구에서는 동적 K 선택, 압축 전개 기법, 그리고 자연그라디언트와의 연계 등을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기