작은 언어 모델을 위한 자기‑적응 프로세스 최적화: SAPO로 추론·검증 격차 해소
초록
SAPO는 작은 언어 모델(SLM)에서 세밀한 추론 단계에 대한 피드백을 효율적으로 제공함으로써, 전통적인 Monte‑Carlo 기반 프로세스 감독의 비효율성을 극복한다. 오류‑관련 전위(ERN) 개념을 차용해 첫 번째 오류 위치를 자동 탐지하고, 최소한의 롤아웃으로 라벨을 보정한다. 이렇게 얻은 과정 보상 모델을 이용해 이유자와 검증자를 반복적으로 공동 최적화하면, 수학·코드 두 분야 모두에서 기존 자기‑진화 방법을 능가한다. 또한, GSM Process와 MBPP Process라는 새로운 단계‑정밀 벤치마크를 제시해 검증기 성능을 체계적으로 평가한다.
상세 분석
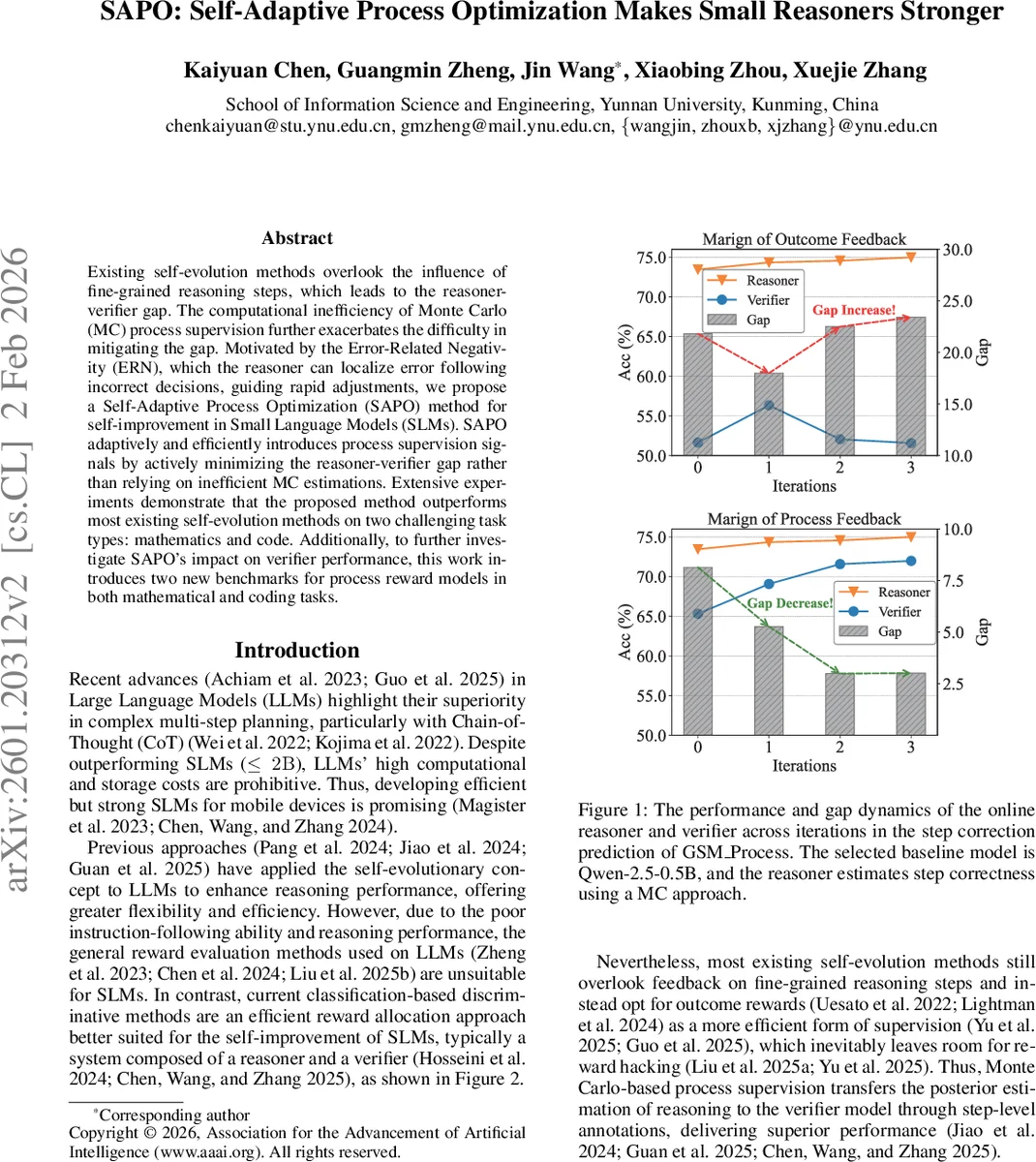
SAPO는 기존 자기‑진화 프레임워크가 “결과‑중심 보상”에만 의존하고, 세부 추론 단계에 대한 피드백을 무시한다는 근본적인 한계를 지적한다. 특히, Monte‑Carlo(MC) 기반의 단계‑별 롤아웃은 8단계 문제에 10개의 경로를 샘플링하면 800 000개의 실행이 필요해 계산 비용이 급증한다. SAPO는 인간의 오류‑관련 전위(ERN) 현상을 모방해, 검증기(V)가 각 단계에 부여한 점수 차이 Δ_j를 이용해 “첫 번째 오류 위치” ˆt를 추정한다. 이때 Δ_j = ˆc_j − 1 − ˆc_j 로 정의되며, 가장 큰 차이를 보이는 단계가 후보가 된다.
첫 오류 위치가 결정되면, SAPO는 최소 두 번의 롤아웃(ˆt‑1, ˆt)만 수행해 라벨을 교정한다. 이는 기존 MC 방식이 요구하는 전 단계에 대한 다중 샘플링에 비해 1~2% 수준의 비용만 소모한다. 교정된 라벨은 검증기 학습에 사용되어, 검증기가 점점 더 정확한 단계‑정밀 점수를 제공한다. 검증기의 점수는 전체 경로에 대한 누적 보상 r(τ)=∑_j ˆc_j 로 집계되고, 이를 기반으로 선호 데이터 D_pref를 구성한다. SAPO는 ORPO(Optimized Rejection‑based Preference Optimization) 손실을 적용해 이유자(M)를 자기‑정렬한다.
알고리즘 1은 초기 SFT( supervised fine‑tuning) 후, 이유자와 검증기를 교대로 업데이트하는 반복 과정을 보여준다. 초기 단계 라벨은 기존 바이너리 추정기(Ω)를 사용해 자동 생성하고, 이후 반복마다 Detect‑→‑Verify‑→‑SFT‑→‑Align 순으로 진행한다. 실험에서는 Qwen‑2.5‑0.5B, Llama‑3.2‑1B, Gemma‑2‑2B 세 모델에 SAPO를 적용했으며, 각 iteration마다 샘플링된 경로 수(K)와 온도(T)를 동일하게 유지했다.
성능 평가에서는 GSM8K·MATH(수학)와 MBPP·HumanEval(코드) 두 도메인을 사용했으며, OOD(Out‑of‑Domain) 테스트까지 포함한다. 기존 방법들(CoT, SFT, RFT, RFT+DPO, Online‑RFT, RPO, GRPO 등)과 비교했을 때, SAPO‑iter3은 수학에서 최고 49.73% 정확도, 코드에서는 Pass@1 36.67%를 기록해 대부분의 베이스라인을 앞선다. 특히, 검증기 성능을 별도로 평가하기 위해 만든 GSM Process(3 786개)와 MBPP Process(1 499개) 벤치마크에서 SAPO 기반 검증기가 단계‑정밀 오류 탐지 정확도와 라벨 보정 효율 모두에서 우수함을 입증한다.
핵심 기여는 다음과 같다. (1) MC 기반 전 단계 롤아웃을 대체해 첫 오류 탐지와 최소 롤아웃으로 라벨을 보정하는 SAPO 프레임워크 제안. (2) 단계‑정밀 검증을 위한 두 새로운 벤치마크 공개. (3) 다양한 SLM에 적용해 기존 자기‑진화 방법을 전반적으로 능가하는 실험적 증명. 이로써 작은 모델에서도 고품질 다단계 추론을 실현할 수 있는 효율적인 경로가 제시된다.
댓글 및 학술 토론
Loading comments...
의견 남기기