효율적인 장문 LLM 추론을 위한 자기예측 토큰 스키핑
초록
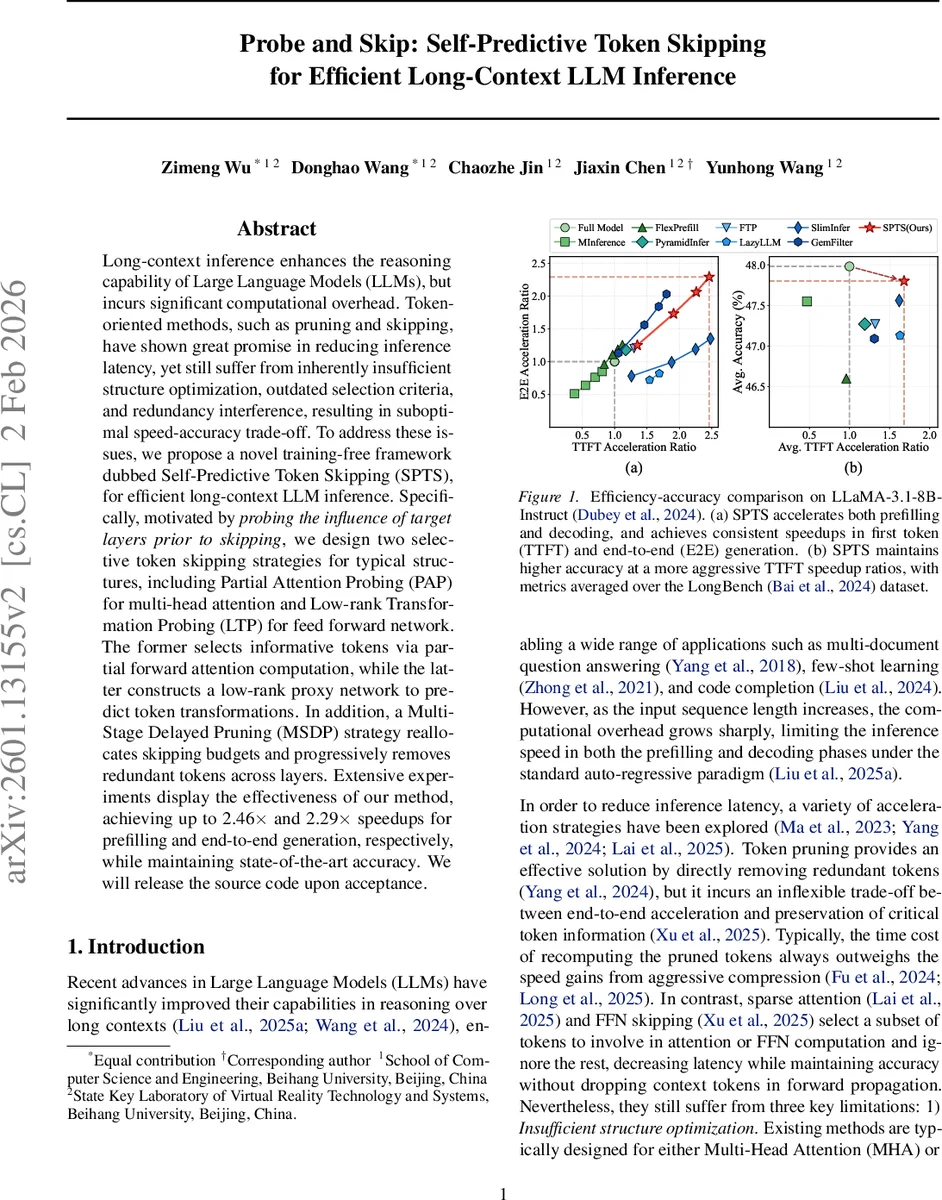
본 논문은 장문 입력을 처리하는 대형 언어 모델(LLM)의 추론 속도를 향상시키기 위해, 학습 없이 적용 가능한 토큰 스키핑 프레임워크인 Self‑Predictive Token Skipping(SPTS)을 제안한다. 핵심 아이디어는 목표 레이어에 미치는 토큰의 영향을 사전에 탐색(probe)하여, 중요한 토큰만 선택적으로 연산하고 나머지는 잔차 경로를 통해 그대로 전달하는 것이다. 이를 위해 다중 헤드 어텐션에는 Partial Attention Probing(PAP), 피드포워드 네트워크에는 Low‑rank Transformation Probing(LTP)을 설계하고, Multi‑Stage Delayed Pruning(MSDP)으로 층별 토큰 예산을 단계적으로 재조정한다. 실험 결과, LLaMA‑3.1‑8B‑Instruct 기준으로 프리필(pre‑fill) 단계에서 최대 2.46배, 전체 생성(end‑to‑end)에서 2.29배의 속도 향상을 달성하면서 정확도 저하를 최소화한다.
상세 분석
SPTS는 기존 토큰 프루닝·스키핑 기법이 갖는 “구조 최적화 부족”, “구식 선택 기준”, “중복 토큰 간 간섭”이라는 세 가지 근본적인 한계를 해결한다. 첫 번째로, Residual 구조를 활용해 입력 토큰 X와 출력 Y가 깊은 층에서 높은 코사인 유사도를 보인다는 실험적 관찰을 기반으로, 전체 토큰을 연산하지 않아도 되는 여지를 찾는다. 이때 선택된 토큰 집합 T_active는 각 레이어마다 별도로 결정되며, 나머지는 단순히 X와 동일하게 전달된다(식 2).
MHA에 적용되는 PAP는 전체 키(K)와 마지막 토큰의 쿼리(q)만을 이용해 부분 어텐션 스코어 S_MHA를 계산한다. 이 스코어는 모든 헤드에 대해 평균화된 후, 상위 M개의 토큰을 선택해 실제 어텐션 연산에 포함한다(식 4‑5). 이렇게 하면 KV 캐시도 활성 토큰에 한해 저장되므로, 디코딩 단계에서도 메모리와 연산량을 동시에 절감한다.
FFN에 적용되는 LTP는 토큰별 변환 크기를 직접 측정하기엔 비용이 크므로, 원본 FFN을 저차원 근사화한 프록시 네트워크 f(·)를 사전 구축한다. 저차원 변환은 데이터‑드리븐 방식으로 중요한 중간 차원을 선정해 구조적 슬리밍을 수행한다(식 9‑10). 프록시가 예측한 변환 크기와 어텐션 스코어를 결합해 토큰 중요도를 평가하고, 변환량이 큰 토큰을 활성 집합에 포함한다. 이는 FFN이 토큰별 독립적으로 작동한다는 특성을 활용해, 연산량을 크게 줄이면서도 표현 손실을 최소한다.
MSDP는 토큰 스키핑을 한 번에 전 층에 적용하는 것이 아니라, 여러 “스테이지”로 나누어 각 스테이지 경계에서 토큰을 재평가·제거한다. 초기 스테이지에서는 보수적인 토큰 예산을 두고, 깊어질수록 점진적으로 예산을 축소함으로써 중복 토큰이 계속해서 연산에 참여하는 현상을 억제한다. 이는 Jaccard 지수를 통해 연속 레이어 간 선택 토큰 집합의 겹침을 감소시키는 효과를 보인다(그림 3‑d).
전체 파이프라인은 프리필 단계에서 전체 입력을 한 번만 처리하고, 이후 디코딩 시에는 압축된 KV 캐시와 스키핑된 토큰 흐름만을 사용한다. 실험에서는 LLaMA‑3.1‑8B‑Instruct, LongBench, Multi‑document QA 등 다양한 벤치마크에서 기존 Sparse Attention, FlashAttention, 기존 토큰 프루닝 기법 대비 2배 이상 속도 향상을 달성했으며, 정확도는 0.2% 이내로 유지되었다.
핵심 기여는 (1) 학습‑프리 프레임워크 SPTS, (2) MHA와 FFN에 특화된 자체 예측 기반 토큰 선택 메커니즘(PAP, LTP), (3) 단계적 토큰 예산 재조정 전략(MSDP)이다. 이 세 요소가 결합돼 장문 LLM 추론에서 효율과 정확도 사이의 트레이드오프를 크게 개선한다.
댓글 및 학술 토론
Loading comments...
의견 남기기