SAE 기반 특징으로 안전한 분류와 전이 학습을 구현하는 새로운 베스트 프랙티스
초록
본 논문은 대형 언어 모델(Large Language Model, LLM) 내부에서 Sparse Autoencoder(SAE)를 이용해 인간이 해석 가능한 특징을 추출하고, 이를 안전‑중심 이진 분류 작업에 적용한다. 모델 레이어 선택, SAE 폭·폭(Width) 및 풀링 전략, 그리고 연속 활성값을 이진화(binarization)하는 방법을 체계적으로 실험하였다. 결과적으로 SAE 특징은 매크로 F1 ≥ 0.8을 달성했으며, 기존 hidden‑state 프로빙 및 TF‑IDF 기반 Bag‑of‑Words(BOW) 대비 우수했다. 또한 Gemma‑2 2B에서 9B‑IT 모델로의 크로스‑모델 전이와 다국어 독성 탐지, 시각 분류 등 제로‑샷 전이에서도 좋은 성능을 보였다. 풀링 방식과 이진화 임계값이 성능에 큰 영향을 미치며, 이진화는 계산·메모리 효율성을 높이면서도 정확도를 유지하거나 향상시킨다.
상세 분석
이 연구는 LLM 내부 표현을 해석 가능하게 만들기 위한 메커니즘 인터프리터블리티(Mechanistic Interpretability, MI) 접근법으로서 SAE를 선택한 점이 핵심이다. SAE는 LLM의 잔차 스트림(residual stream)에서 고차원 dense hidden state를 압축·희소화(sparse)하여, 각 차원이 가능한 한 단일 의미(모노세마틱)를 갖도록 학습한다. 논문은 Gemma‑2 시리즈(2B, 9B, 9B‑IT)에서 사전 학습된 SAE를 그대로 활용했으며, 새로운 SAE를 훈련하지 않아 재현성과 비용 효율성을 동시에 확보했다.
-
레이어·스케일 선택
- 2B 모델에서는 레이어 5, 12, 19(초·중·후)에서, 9B·9B‑IT에서는 9, 20, 31 레이어를 사용했다.
- 실험 결과, 중간 레이어의 SAE 특징이 가장 높은 F1(≈0.85~0.90)을 기록했으며, 이는 중간 레이어가 의미론적·구문론적 정보를 균형 있게 포함하고 있기 때문으로 해석된다.
- 모델 규모가 클수록(9B, 9B‑IT) 전반적인 성능이 상승했으며, 이는 hidden dimension이 커짐에 따라 더 풍부한 표현을 제공하기 때문이다.
-
SAE 폭(Width) 및 구조
- 2B 모델에선 16K와 65K 차원을, 9B·9B‑IT 모델에선 16K와 131K 차원을 실험했다.
- 폭이 클수록 특징 다양성이 증가해 성능이 미세하게 개선되었지만, 계산 비용과 메모리 사용량도 비례적으로 증가한다. 따라서 실용적인 적용에서는 65K~131K 정도가 적절한 트레이드오프를 제공한다.
-
풀링 전략
- 토큰 수준에서 top‑N(20, 50) 활성값을 선택하는 max‑pooling과, 토큰 전체를 합산(sum)하는 두 가지 방법을 비교했다.
- top‑N 풀링은 특히 N이 커질수록 성능을 약간 끌어올렸지만, 최적 N을 찾기 위한 추가 연산이 필요했다.
- 반면, 전체 합산 방식은 구현이 단순하고, 이진화와 결합했을 때도 경쟁력 있는 결과를 보였다.
-
이진화(binarization)
- SAE 특징을 1차원 실수 벡터에서 임계값(>1) 기준으로 0/1 이진 벡터로 변환했다.
- 이진화는 (1) 메모리·저장 효율성, (2) 비선형 활성화 효과(ReLU와 유사), (3) 암시적 특징 선택 메커니즘을 제공한다.
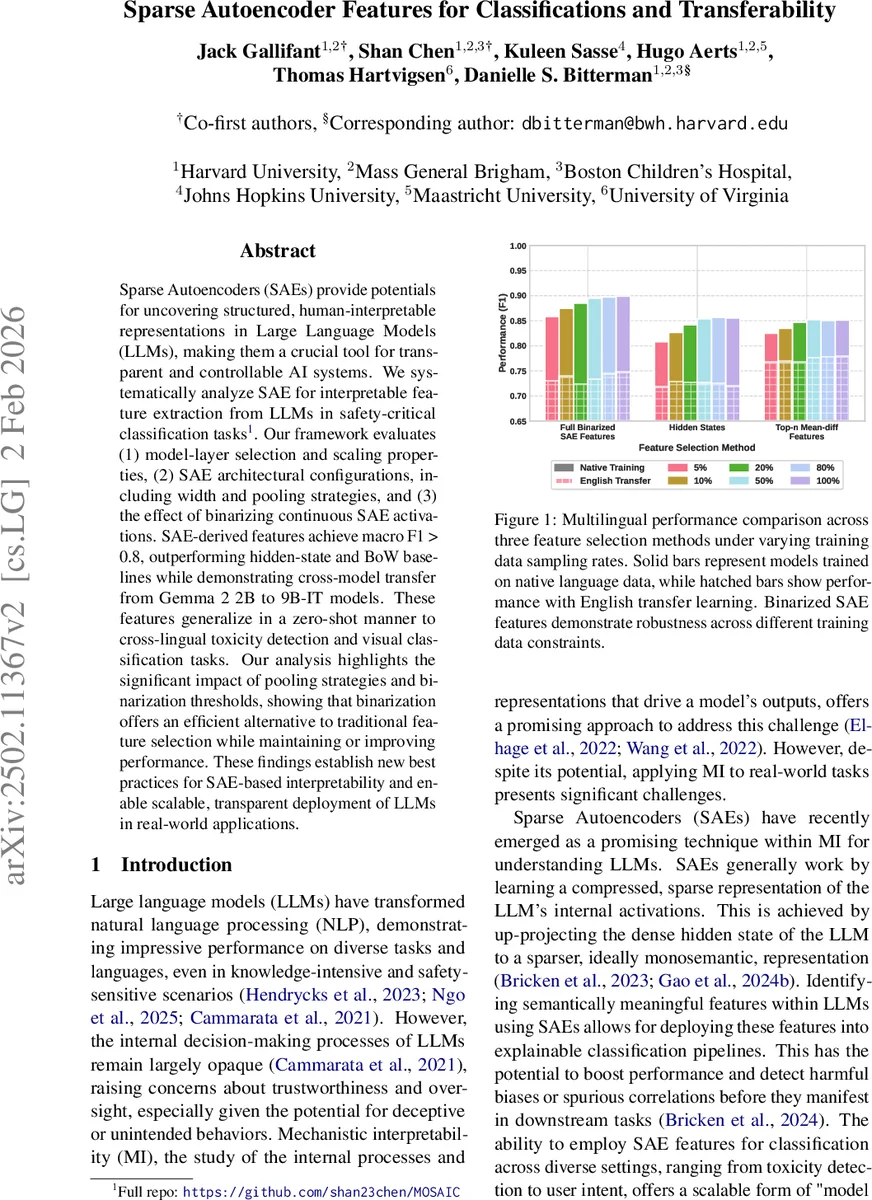
- 실험에서는 이진화된 특징이 비이진화된 전체 합산보다 약간 높은 F1을 기록했으며, 특히 데이터 양이 제한된 상황(5%~20% 샘플)에서 강인성을 보였다.
-
전이 가능성
- SAE 특징을 Gemma‑2 2B에서 학습한 뒤 9B·9B‑IT 모델에 그대로 적용했을 때, 성능 저하가 거의 없었다. 이는 SAE가 모델 아키텍처에 독립적인 의미론적 구조를 포착한다는 증거다.
- 다국어 독성 탐지에서는 영어 기반 SAE 특징이 다른 언어(스페인어, 프랑스어 등)에서도 높은 macro F1(>0.78)를 달성했으며, 제로‑샷 시각 분류(Vision‑Language) 작업에서도 의미 있는 전이 효과를 확인했다.
-
베이스라인 대비 우위
- TF‑IDF와 마지막 토큰 hidden‑state 프로빙을 베이스라인으로 설정했으며, 전자는 전통적인 BOW 방식, 후자는 최신 LLM 해석 방법이다.
- 대부분의 실험에서 SAE 기반 특징이 두 베이스라인을 크게 앞섰으며, 특히 중간 레이어 + 이진화 + top‑20 풀링 조합이 최고 성능을 기록했다.
-
재현성 및 오픈소스
- 전체 파이프라인(YAML 설정 파일 포함)과 코드가 GitHub에 공개돼 있어, 동일한 하드웨어(NVIDIA A6000)와 데이터셋을 사용하면 동일한 결과를 재현할 수 있다.
핵심 인사이트
- SAE는 LLM 내부의 고차원 정보를 압축하면서도 의미론적 일관성을 유지한다는 점에서 해석 가능하고 효율적인 특징 추출 도구다.
- 중간 레이어와 충분히 넓은 SAE 폭을 선택하고, 토큰‑레벨 top‑N 풀링 혹은 전체 합산 후 이진화를 적용하면, 계산 비용을 크게 늘리지 않으면서도 높은 분류 성능을 얻을 수 있다.
- 이진화는 단순히 메모리 절감에 그치지 않고, 실제 성능 향상에도 기여한다는 점에서 실무 적용 시 강력히 권장된다.
댓글 및 학술 토론
Loading comments...
의견 남기기