경량형 계단형 융합 네트워크를 이용한 구조 균열 픽셀‑단위 세분화
초록
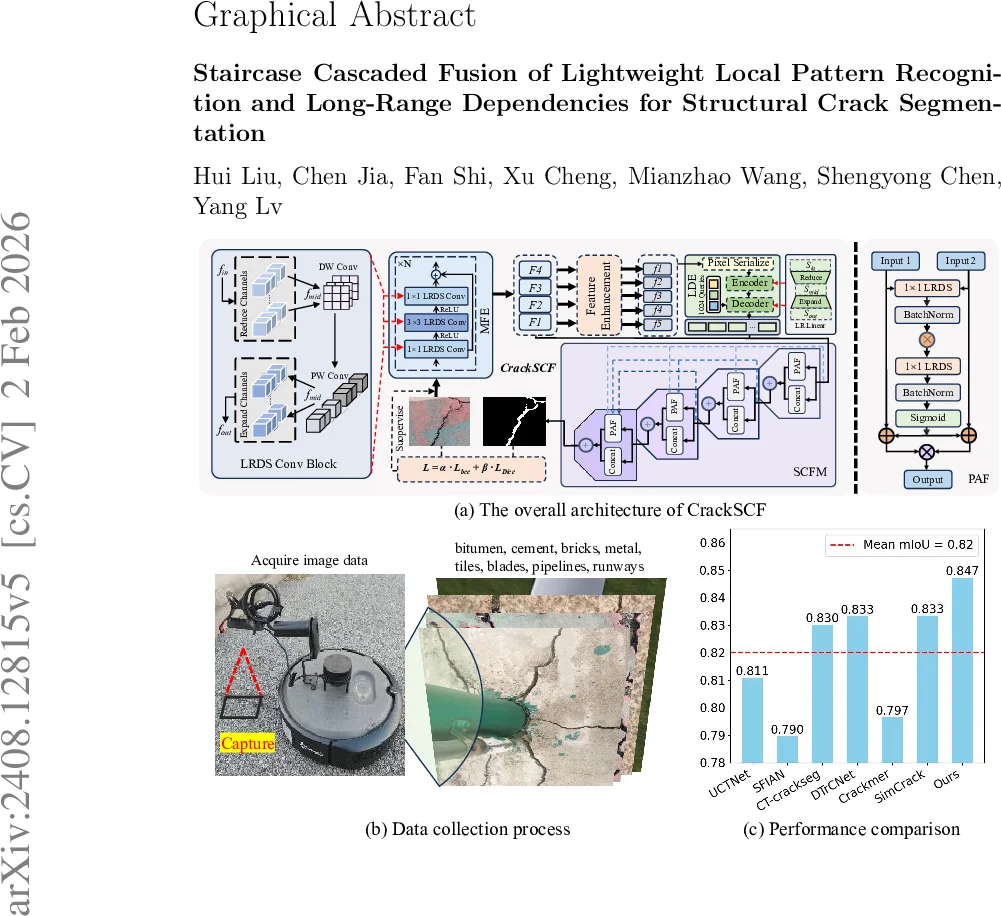
본 논문은 구조물 균열을 고해상도 픽셀 수준에서 정확히 분할하기 위해 경량화된 컨볼루션 블록(LRDS), 장거리 의존성 추출기(LDE), 그리고 계단형 연쇄 융합 모듈(SCFM)을 결합한 CrackSCF 네트워크를 제안한다. 저자들은 다양한 환경을 포함한 TUT 벤치마크 데이터를 구축하고, 5개 공개 데이터셋과 함께 실험하여 기존 SOTA 방법들을 능가함을 입증하였다. 모델 파라미터는 4.79 M에 불과하며, F1 = 0.8382, mIoU = 0.8473을 달성한다.
상세 분석
CrackSCF는 세 가지 핵심 모듈로 구성된다. 첫 번째인 LRDS(Low‑Rank Depthwise Separable) 블록은 전통적인 3×3 Conv를 저랭크 근사와 Depthwise + Pointwise 연산으로 대체함으로써 연산량을 O(e·k²·c)에서 O(e₀·k²·c)+O(e·e₀)로 감소시키고, 파라미터 수를 70 % 이상 절감한다. 두 번째 모듈인 LDE는 deformable attention을 기반으로 하여 불규칙한 균열 형태의 장거리 픽셀 관계를 포착한다. 여기서 선형 변환은 저랭크 행렬 분해(E≈ABᵀ)로 구현돼 FLOPs와 파라미터가 각각 90 %·67 % 수준에서 크게 감소한다. 세 번째인 SCFM은 “계단형” 구조를 채택해 MFE에서 추출된 4단계 다중 스케일 특징과 LDE가 만든 픽셀 시퀀스를 단계별로 융합한다. 융합 과정은 채널 concat과 픽셀‑레벨 attention을 병행해 지역 텍스처와 전역 의존성을 상호 보완하도록 설계되었으며, 각 단계마다 해상도는 2배 업샘플링, 채널 수는 절반으로 감소한다. 이러한 설계는 기존 U‑shape 혹은 단순 concat 기반 방법이 겪는 세밀한 균열 손실과 배경 잡음에 대한 민감성을 크게 완화한다. 실험에서는 기존 CNN‑Transformer 하이브리드 모델(예: CATransUNet, DT‑rCNet 등)이 파라미터 9 ~ 12 M, FLOPs 70 G 이상을 요구하는 반면, CrackSCF는 4.79 M 파라미터와 3.2 G FLOPs 수준으로 경량화되면서도 F1·mIoU 모두 3 ~ 5 % 포인트 상승을 기록했다. 특히 TUT 데이터셋에서 복합 배경(비트멘, 금속, 타일 등)과 조명 변화에 강인함을 보이며, 실제 현장 Edge 디바이스(스마트폰, 드론) 적용 가능성을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기