논리적 난독화 속 LLM의 추론 취약성 탐구
초록
본 논문은 논리적 동등성을 유지하면서 질문을 난독화하는 Logifus 프레임워크와, 이를 활용해 1,108개의 난독화된 추론 문제를 제공하는 LogiQAte 벤치마크를 제안한다. 네 가지 추론 영역(FOL, 혈연 관계, 수열 패턴, 방향 감각)에서 여섯 최신 LLM을 평가한 결과, 논리적 난독화가 제로샷 성능을 평균 28.8% 감소시키며, 특히 GPT‑4o는 47%까지 성능이 급락한다는 사실을 밝혀냈다. 이는 현재 LLM이 표면 형태에 과도히 의존하고 깊은 논리 이해가 부족함을 시사한다.
상세 분석
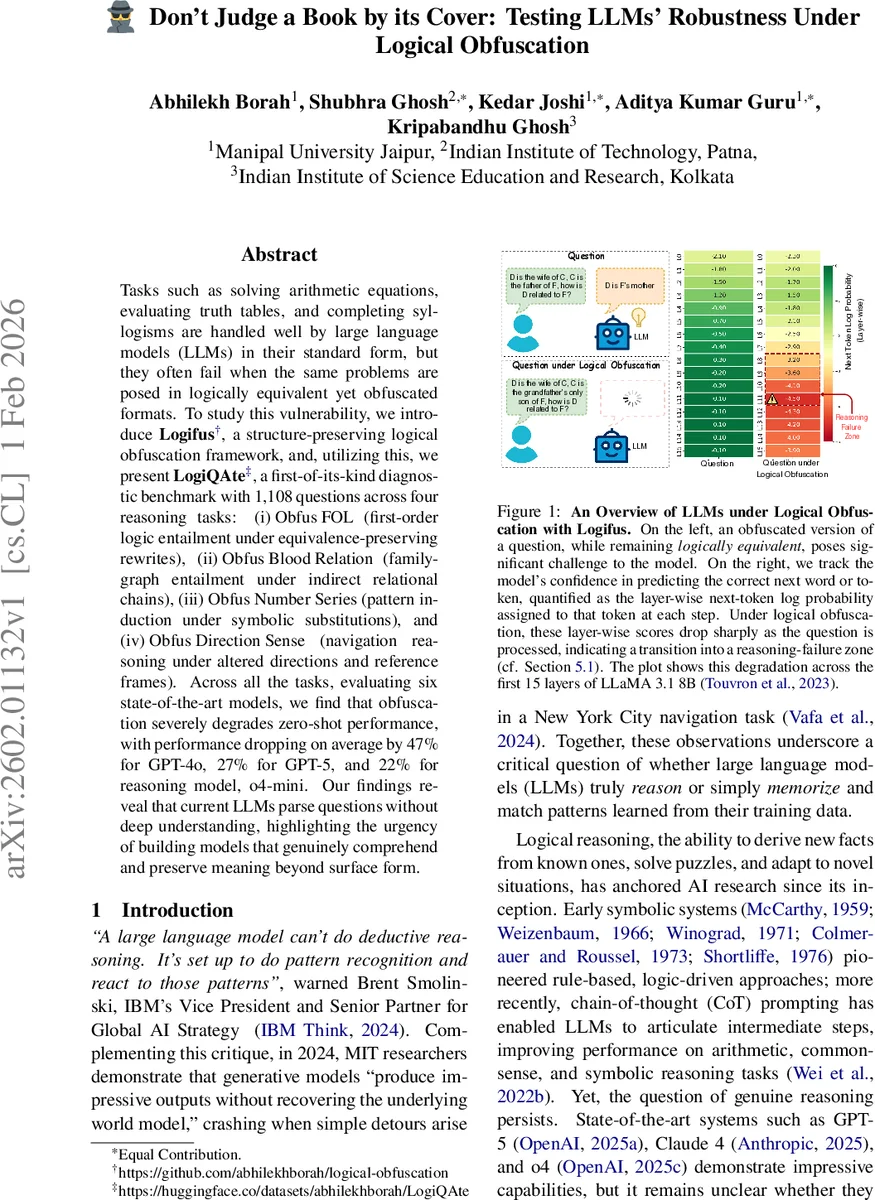
본 연구는 LLM이 “진정한 논리 추론”을 수행하는지 여부를 검증하기 위해 ‘논리적 난독화(logical obfuscation)’라는 새로운 평가 방식을 도입한다. 핵심 기법인 Logifus는 질문과 전제의 논리 구조를 보존하면서도 문법·어휘·구조를 다변화하는 일련의 변환 규칙을 제공한다. 예를 들어, 일차 논리(FOL)에서는 드모르간 법칙, 이중 부정 제거, 동치 변형 등을 적용해 동일한 의미를 갖는 전제 집합을 생성한다. 혈연 관계에서는 직접적인 kinship 표현을 다중 홉 관계(예: “형제 → 형제‑인‑법의 남편”)로 바꾸어 인지적 부하를 증가시킨다. 수열 과제는 기호 치환, 산술 변환, 해시 기반 매핑 등을 통해 숫자 시퀀스의 표면 형태를 완전히 바꾸면서도 원래 패턴을 유지한다. 방향 감각 과제는 좌·우·동·서 등 방향어를 다른 좌표계(예: “westward” → “move three paces west”)로 재표현한다.
데이터 구축 단계에서는 기존 고품질 자료(FOLIO, 교육용 혈연 퍼즐 등)를 기반으로 GPT‑4o를 활용해 전제를 간소화하고, 인간 annotator 2인과 자동 정리 도구(Prover9)로 논리 동등성을 검증한다. Cohen’s κ가 0.88 이상으로 높은 일관성을 확보함으로써 난독화된 질문이 원 질문과 동일한 정답을 갖는다는 사실을 보장한다.
실험에서는 GPT‑4o, GPT‑5, Claude‑4, o4‑mini 등 여섯 모델을 제로샷, 몇 샷, CoT 프롬프트 설정에서 평가하였다. 결과는 일관되게 나타났는데, 난독화된 질문에 대한 정확도가 원 질문 대비 평균 28.8% 감소했으며, 특히 GPT‑4o는 47%까지 급락했다. 모델별 차이를 살펴보면 최신 모델일수록 절대 성능은 높지만, 상대적 감소율은 여전히 크다. 추가 분석으로는 (1) 메모리 기반 정답 탐지율이 원 질문 50%→난독화 82%로 상승, 즉 모델이 표면 패턴을 기억하는 경향이 강화됨을 보여준다. (2) 레이어별 다음 토큰 로그 확률이 후반 레이어에서 50‑80% 급감하는 현상이 관찰돼, 논리적 추론 단계에서 신뢰도가 크게 떨어짐을 시사한다.
이러한 결과는 LLM이 현재 ‘패턴 매칭’에 의존하고 있음을 강력히 시사한다. 논리적 구조를 보존하면서도 표면을 변형하는 난독화는 모델이 진정한 의미론적 이해 없이도 높은 정확도를 달성할 수 있음을 폭로한다. 따라서 향후 연구는 (① 논리 구조를 명시적으로 인코딩하는 아키텍처, ② 논리적 증명 과정을 외부 도구와 연동하는 하이브리드 시스템, ③ 난독화에 강인한 학습 전략) 등을 모색해야 할 것이다. 또한 LogiQAte와 Logifus는 향후 LLM 평가 및 튜닝에 표준 벤치마크로 활용될 잠재력이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기