논리‑지향 검색 강화: LORE 대비형 대비학습 접근법
초록
LORE는 기존 임베딩 모델이 내재하고 있는 논리적 표현 능력을 대비학습으로 활성화한다. 쿼리‑문서 쌍을 긍정, 방해(N1), 일반 부정(N2)으로 구분하고, β > α > 0인 가중치를 적용한 InfoNCE 변형 손실을 사용해 쿼리 인코더만 미세조정한다. 결과적으로 표면 유사도에 의존하던 검색기가 복잡한 논리 구조를 반영한 증거를 더 잘 찾아내며, MS MARCO, HotpotQA, MuSiQue 등 다양한 벤치마크에서 원본 및 교란 데이터 모두에서 Recall이 크게 향상된다.
상세 분석
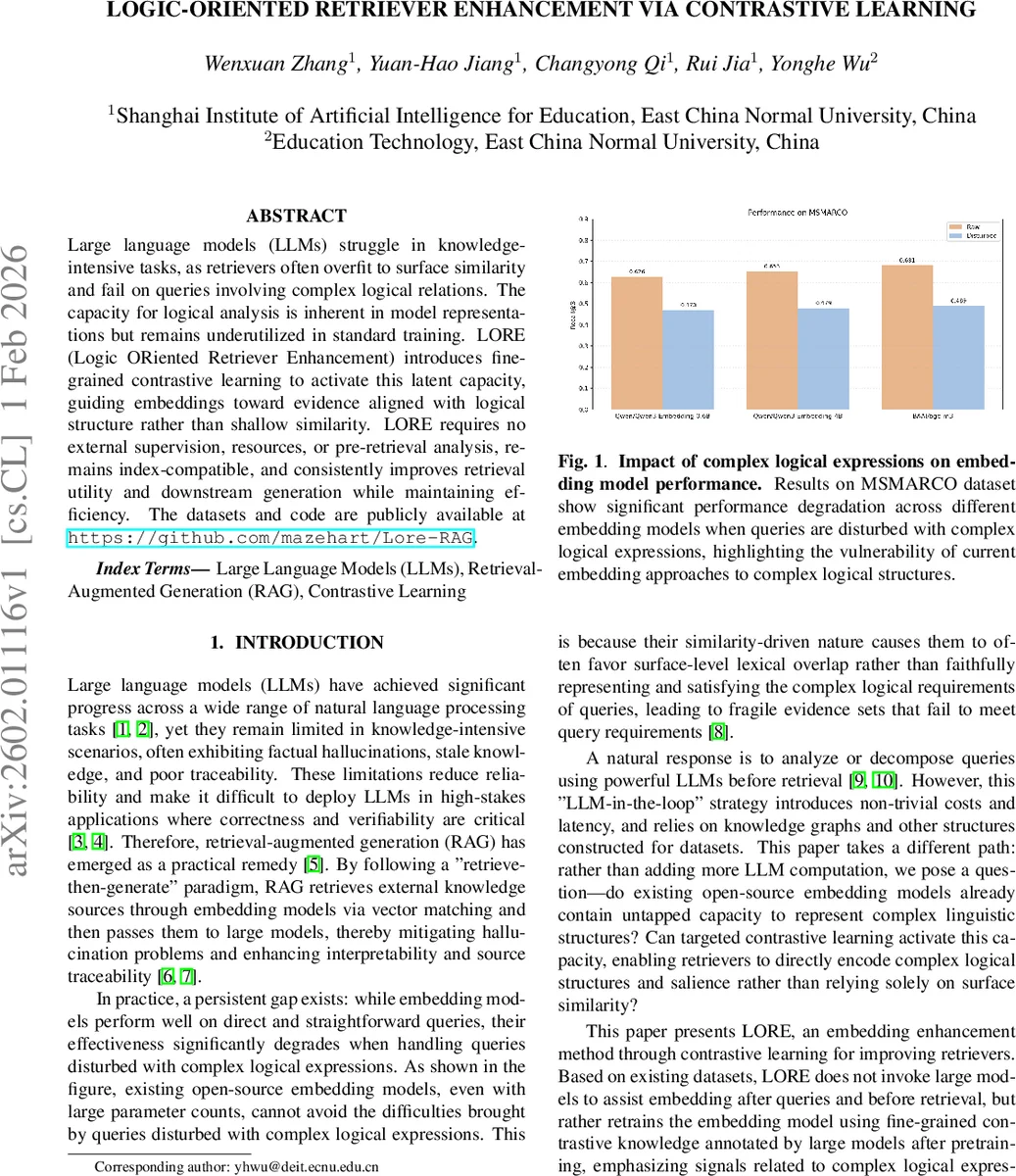
LORE는 “검색‑후‑생성(RAG)” 파이프라인에서 발생하는 근본적인 한계, 즉 임베딩 기반 검색기가 표면적인 어휘 일치에 과도하게 의존해 복합 논리 관계를 포함한 질의에 취약한 점을 해결하고자 한다. 이를 위해 저자들은 기존 코퍼스에 쿼리‑문서 쌍을 구축하고, LLM을 활용해 질의를 의도적으로 교란시킨 뒤, RST(수사 구조 이론)에서 정의된 8가지 논리 관계(Sequential, Transitional 등)를 기반으로 ‘방해(N1)’와 ‘일반 부정(N2)’를 구분한다. 이렇게 만든 CoEnTrain 데이터셋은 세 계층(P > N1 > N2)으로 라벨링된다.
학습 단계에서는 두 개의 인코더(Mq, Md)를 사용한다. 문서 인코더는 사전학습된 파라미터를 고정하고, 쿼리 인코더만 대비학습한다. 각 후보 문서 ck에 대해 코사인 유사도 sk를 계산하고, 온도 τ와 가중치 β, α를 적용해 조정된 로그잇 ˜sk를 만든다. 여기서 β > α는 방해(N1) 샘플에 더 강한 패널티를 부여해 모델이 미묘한 의미 차이를 학습하도록 설계되었다. 긍정 샘플에 대한 확률 p_k는 N1·N2만을 분모에 두어 긍정 샘플이 부정 샘플에 의해 희석되지 않게 한다. 최종 손실은 InfoNCE의 변형인 −∑_{k∈P}log p_k이며, 이는 P ≫ N1 ≫ N2의 계층적 구분을 명시적으로 강제한다.
실험에서는 Qwen3‑Embedding‑0.6B와 BGE‑M3 두 모델에 LORE를 적용했으며, 동일한 하이퍼파라미터(τ=0.05, α=1.0, β=3.0)와 1 epoch 학습으로 충분히 수렴한다는 점을 보여준다. 결과표 1을 보면, 원본 데이터뿐 아니라 복잡한 논리 교란이 추가된 데이터에서도 LORE가 InfoNCE 대비 긍정 샘플 Recall을 평균 2~5%p 상승시켰으며, 특히 방해(N1) 샘플을 효과적으로 억제해 불필요한 문서가 상위에 오르는 현상을 크게 감소시켰다. 흥미롭게도 MSMARCO에서만 미세 라벨링을 수행했음에도 HotpotQA와 MuSiQue 같은 전혀 다른 도메인에서 일반화 효과가 확인되었다. 이는 LORE가 논리 구조에 대한 근본적인 표현 능력을 임베딩 레벨에서 강화함을 의미한다.
한계점으로는 논리 구조의 다양성(조건문, 부정, 비교 등)이 아직 충분히 포괄되지 않았으며, 데이터셋 구축에 LLM 기반 재작성 과정이 필요하다는 점이다. 향후 연구에서는 더 풍부한 논리 패턴을 포함한 자동화된 주석 생성 파이프라인과, 다중 언어 및 멀티모달 상황에서의 적용 가능성을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기