모달리티와 전문가 특성을 동시에 고려한 MoE 비전‑언어 모델 양자화
초록
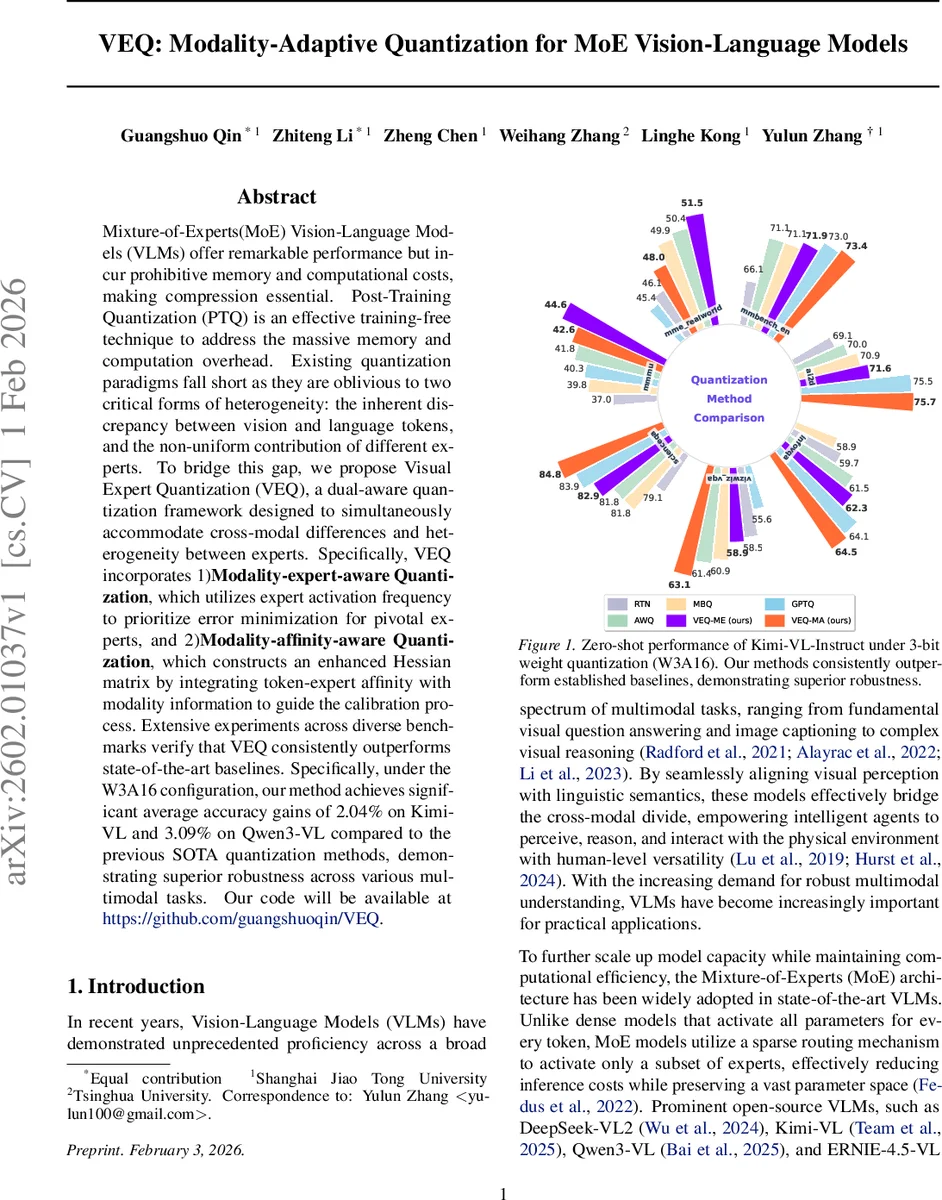
본 논문은 MoE 기반 비전‑언어 모델(VLM)의 구조적 특성과 시각·언어 토큰 간 분포 차이를 동시에 반영한 포스트‑트레이닝 양자화 프레임워크 VEQ를 제안한다. VEQ는 (1) 전문가 활성화 빈도에 기반한 모달리티‑전문가 가중치(ME)와 (2) 토큰‑전문가 친화도와 모달리티 정보를 결합한 향상된 헤시안(MA) 두 가지 메커니즘을 도입해 양자화 오차를 중요한 전문가와 민감한 토큰에 집중시킨다. 실험 결과, W3A16 설정에서 Kimi‑VL과 Qwen3‑VL에 대해 각각 평균 2.04%·3.09%의 정확도 향상을 달성하며, 기존 최첨단 PTQ 방법들을 일관적으로 능가한다.
상세 분석
VEQ는 MoE VLM이라는 복합 구조의 두 가지 이질성을 정량적으로 분석한 뒤, 이를 양자화 설계에 직접 반영한다. 첫 번째 이질성은 시각 토큰과 언어 토큰이 모델 내부에서 서로 다른 그래디언트 스케일과 민감도를 보인다는 점이다. 논문은 COCO 샘플 128개에 대해 텍스트 토큰의 평균 그래디언트 크기가 시각 토큰보다 22.4배 크다는 정량적 근거를 제시하며, 이는 텍스트가 최종 출력에 비례적으로 큰 영향을 미친다는 것을 의미한다. 따라서 동일한 비트폭을 적용하면 텍스트 토큰이 더 큰 양자화 노이즈에 노출되어 성능 저하가 발생한다.
두 번째 이질성은 MoE 전문가들의 활성화 빈도와 모달리티 선호도이다. 라우터 로그잇을 분석한 결과, 전체 전문가 중 소수(‘핫’ 전문가)가 토큰의 80% 이상을 담당하고, 나머지는 거의 사용되지 않는다. 또한, 일부 전문가는 시각 토큰에, 다른 일부는 언어 토큰에 특화된 라우팅 패턴을 보이며, 일반화된 전문가와 모달리티‑전문가 클러스터가 동시에 존재한다. 이러한 불균형은 기존 PTQ가 모든 가중치를 동일하게 재구성하려 할 때, 핵심 전문가의 양자화 오차가 전체 성능에 과도하게 전이되는 원인이 된다.
VEQ‑ME는 이러한 현상을 해결하기 위해 전문가별 활성화 빈도 (f_i)를 정규화한 중요도 스코어 (S_i)를 정의하고, 재구성 손실 (\mathcal{L} = \sum_i S_i |W_i^{\text{fp}} - Q(W_i^{\text{fp}})|^2)에 가중한다. 즉, 빈번히 사용되는 ‘핫’ 전문가일수록 양자화 오차를 최소화하도록 학습한다.
VEQ‑MA는 헤시안 기반 양자화(예: GPTQ)의 한계를 보완한다. 기존 헤시안은 전체 손실의 2차 근사만을 고려해 토큰 간 상관관계를 무시한다. 여기서는 토큰‑전문가 친화도 행렬 (A)와 모달리티 민감도 벡터 (m)를 결합해 (\tilde{H}=A^\top \operatorname{diag}(m) A) 형태의 강화된 헤시안을 구성한다. 이 행렬은 텍스트 토큰이 높은 가중치를, 시각 토큰은 낮은 가중치를 갖도록 조정되어, 양자화 과정이 모달리티별 민감도를 반영한다.
실험 설계는 Kimi‑VL, Qwen3‑VL 두 대형 MoE VLM에 대해 W3A16(3비트 가중치, 16비트 활성화) 설정을 적용하고, MME, GPTQ, MBQ 등 최신 PTQ와 비교한다. 결과는 모든 베이스라인 대비 평균 정확도가 2~3%p 상승했으며, 특히 저비트(2비트)에서도 안정적인 성능 유지가 확인되었다. 또한, 전문가 활성화 분포가 크게 변하지 않는 다양한 데이터셋(MMMU, MME‑RealWorld, InfoVQA 등)에서도 일관된 개선 효과를 보였다.
이러한 설계는 두 가지 핵심 원칙을 따른다. ① 전문가의 실제 사용 빈도와 역할에 기반한 비대칭 양자화 가중치 부여, ② 모달리티별 그래디언트 민감도를 헤시안에 통합해 손실 근사를 정교화. 결과적으로 VEQ는 기존 PTQ가 놓치던 ‘핫’ 전문가와 텍스트 토큰의 민감도를 효과적으로 보전한다.
향후 연구 방향으로는 (1) 전문가별 동적 비트폭 할당을 통한 혼합 정밀도 확장, (2) 라우터 자체를 양자화 친화적으로 재학습하는 방법, (3) 실시간 스트리밍 시나리오에서 라우터‑양자화 연동을 최적화하는 방안 등이 제시될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기