멀티턴 환각 평가의 새로운 기준 HalluHard
초록
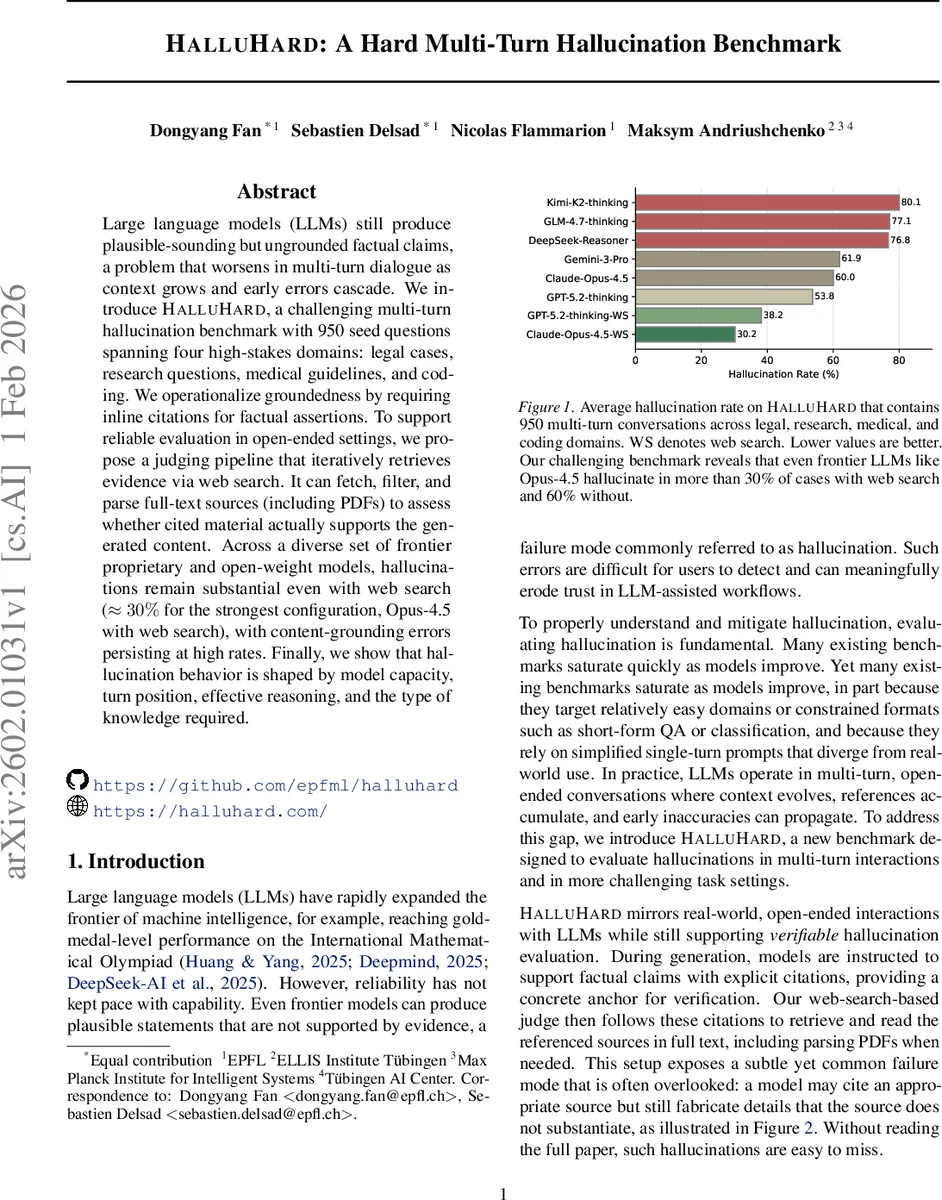
HalluHard는 법률, 연구, 의료, 코딩 네 분야의 950개 시드 질문을 기반으로 다중 턴 대화에서 LLM의 환각 현상을 측정하는 벤치마크이다. 모델은 인라인 인용을 제공하도록 요구되며, 평가 파이프라인은 웹 검색·전체 텍스트 추출·PDF 파싱을 통해 인용 내용과 실제 근거를 비교한다. 실험 결과, 최첨단 모델조차 웹 검색을 활용해도 약 30% 수준의 환각을 보이며, 턴이 진행될수록 오류가 누적되는 경향이 확인되었다.
상세 분석
본 논문은 대형 언어 모델(LLM)의 사실성(factuality) 문제를 다중 턴 대화 상황에 초점을 맞추어 체계적으로 조사한다. 기존의 단일 턴 QA나 짧은 형식의 사실성 벤치마크는 모델이 검색 도구를 활용하면 거의 포화 상태에 이르러, 실제 서비스 환경에서 발생하는 복합적인 오류를 포착하지 못한다는 한계가 있다. 이를 극복하고자 저자들은 네 가지 고위험 도메인(법률 사건, 연구 질문, 의료 가이드라인, 코딩)에서 각각 250개(코딩 200개)의 시드 질문을 선정하고, 각 질문에 대해 다중 턴 대화를 시뮬레이션한다. 특히, “인라인 인용”을 강제함으로써 모델이 제시한 주장과 근거 문헌을 명확히 연결하도록 설계했으며, 이는 평가 단계에서 인용의 진위와 내용 일치를 동시에 검증할 수 있는 기반을 제공한다.
평가 파이프라인은 크게 네 단계로 구성된다. 첫째, LLM 기반 추출기를 이용해 모델 응답에서 원자적(claim) 단위를 식별한다. 둘째, 각 클레임에 대해 검색 계획을 수립하고 Serper API를 통해 웹 검색을 수행한다. 셋째, 검색 결과에서 전체 텍스트(특히 PDF와 같은 비정형 문서)를 다운로드하고 파싱하여 인용된 구절을 정확히 매칭한다. 넷째, 또 다른 LLM이 증거 충분성을 판단해 추가 검색이 필요한지 여부를 결정한다. 이 과정은 기존 SAFE 방식이 스니펫 수준에 머무르는 문제를 해결하고, 깊이 있는 근거 검증을 가능하게 한다.
실험에서는 Opus‑4.5, Claude, Gemini‑3‑P, DeepSeek‑Reasoner 등 최신 상용 모델과 오픈‑웨이트 모델을 포함한 12종을 평가하였다. 웹 검색을 비활성화한 경우 평균 환각 비율은 60%를 초과했으며, 웹 검색을 활성화해도 최강 모델(Opus‑4.5)조차 약 30% 수준의 환각을 보였다. 특히, 턴이 진행될수록(후반 턴) 오류 누적이 뚜렷하게 나타났으며, 이는 초기 잘못된 인용이 이후 대화 전개에 지속적인 영향을 미친다는 점을 시사한다. 또한, “효과적 사고(effective reasoning)”를 촉진하는 프롬프트는 환각 감소에 기여했지만, 단순히 추론 단계만 늘리는 “추가 사고”는 큰 효과를 보이지 않았다. 도메인별 분석에서는 의료와 법률 분야가 가장 높은 환각율을 기록했으며, 이는 해당 분야가 전문 용어와 최신 지식에 대한 정확한 인용을 요구하기 때문이다.
이 논문의 주요 기여는 (1) 다중 턴, 고위험 도메인, 인라인 인용 요구라는 세 가지 축을 결합한 새로운 환각 벤치마크를 제시한 점, (2) 전체 텍스트와 PDF 파싱을 포함한 고도화된 평가 파이프라인을 구축해 인용·내용 일치 여부를 정밀히 판단한 점, (3) 모델 규모, 턴 위치, 추론 전략, 지식 유형이 환각에 미치는 영향을 실증적으로 규명한 점이다. 이러한 결과는 단순히 검색 도구를 붙이는 것만으로는 LLM의 사실성 문제를 근본적으로 해결하기 어렵다는 경고를 제공한다. 향후 연구는 인용 생성 자체의 품질 향상, 오류 전파 억제 메커니즘, 그리고 도메인 특화된 검증 데이터베이스 구축 등을 통해 환각을 보다 근본적으로 감소시킬 방안을 모색해야 할 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기