대규모 언어 모델을 위한 검색 무료 하드웨어 친화적 혼합 정밀도 양자화
초록
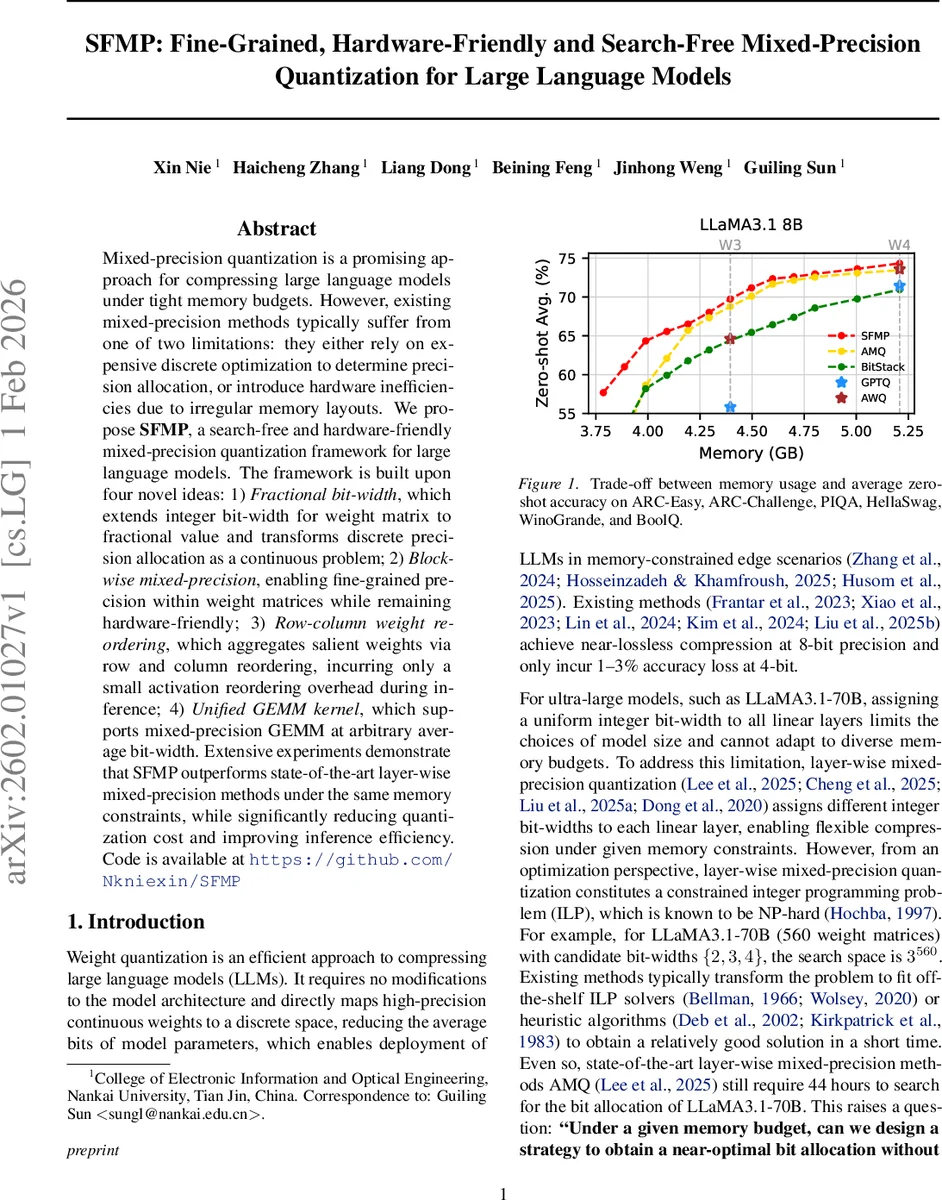
SFMP는 평균 비트 수를 실수값으로 확장한 “분수 비트폭” 개념과 블록 단위 혼합 정밀도, 행·열 가중치 재배열, 통합 GEMM 커널을 결합해 검색 없이 최적 비트 할당을 수행한다. 이 방식은 메모리 사용량을 동일하게 유지하면서 기존 레이어‑와인드 혼합 정밀도 방법보다 높은 정확도를 달성하고, 비정형 메모리 접근을 최소화해 추론 효율을 크게 향상시킨다.
상세 분석
SFMP는 네 가지 핵심 아이디어를 통해 대규모 언어 모델(LLM)의 혼합 정밀도 양자화 문제를 근본적으로 재구성한다. 첫 번째는 “분수 비트폭(Fractional bit‑width)”이다. 기존 방법은 각 레이어에 정수 비트폭을 할당해 이산 최적화 문제를 풀어야 했지만, SFMP는 목표 평균 비트 b를 실수값으로 두고 ⌊b⌋와 ⌈b⌉ 두 후보 비트폭만을 사용한다. 비트 할당은 전역 살리언스(Fisher 대각선) 기반 α‑분위수 임계값 τ α를 이용해, 살리언스가 높은 가중치에 ⌈b⌉ 비트를, 나머지에 ⌊b⌋ 비트를 부여함으로써 검색 없이 거의 최적에 가까운 배분을 즉시 산출한다.
두 번째는 “블록‑와인드 혼합 정밀도(Block‑wise mixed‑precision)”이다. 가중치를 m b × n b 크기의 2‑차원 블록으로 나누고, 각 블록의 총 살리언스를 기준으로 비트폭을 결정한다. 블록 단위는 GPU의 GEMM 타일링(예: 256 × 128, 512 × 128)과 자연스럽게 맞물려 메모리 레이아웃을 규칙적으로 유지한다. 이는 요소‑와인드 할당이 초래하는 불규칙 메모리 접근을 방지하고, 하드웨어 파이프라인이 효율적으로 작동하도록 만든다.
세 번째는 “행·열 가중치 재배열(Row‑Column weight reordering)”이다. 실제 살리언스는 행 또는 열 방향으로 집중되는 경향이 있어, 블록 경계와 정렬되지 않는다. 이를 해결하기 위해 살리언스 행·열 합계를 계산해 내림차순으로 정렬하고, 해당 순열을 가중치 행렬에 적용한다. 재배열된 행렬 ˜W는 고살리언스 가중치를 블록 내부에 집중시켜 블록‑와인드 비트 할당과의 정렬을 최적화한다. 재배열은 오프라인에서 수행되며, 추론 시에는 입력 활성화 행렬에 동일한 순열 역변환을 적용해 비용을 거의 발생시키지 않는다.
네 번째는 “통합 GEMM 커널(Unified mixed‑precision GEMM kernel)”이다. 블록‑와인드 형식의 가중치는 비트폭이 서로 다를 수 있지만, 평균 비트 b가 실수이므로 각 블록은 ⌊b⌋ 또는 ⌈b⌉ 비트로 저장된다. SFMP는 이러한 가중치를 하나의 연산 커널에서 처리하도록 설계했으며, 특히 1‑비트 LUT 기반 GEMM과 결합해 가중치 언팩을 회피한다. 가중치를 비트별 1‑비트 행렬로 분해하고, 활성화 벡터와의 내적을 LUT 조회와 누적으로 대체함으로써 메모리 대역폭과 연산량을 크게 감소시킨다. 결과적으로 평균 비트가 2.5 비트인 경우에도 기존 4‑비트 정밀도 대비 30 % 이상 높은 추론 처리량을 달성한다.
전체적으로 SFMP는 “검색‑무료(search‑free)”라는 목표를 달성하면서도, “하드웨어‑친화적(hardware‑friendly)”인 메모리 레이아웃과 연산 흐름을 제공한다. 실험에서는 LLaMA 3.1‑70B와 같은 초대형 모델에 대해 동일 메모리 예산(예: 2.5 비트 평균) 하에서 기존 레이어‑와인드 혼합 정밀도 방법(AMQ)보다 1‑2 % 높은 zero‑shot 정확도를 기록했으며, 양자화 과정에 소요되는 시간도 44 시간에서 0.15 시간 이하로 급감했다. 이러한 결과는 대규모 모델을 제한된 엣지 디바이스에 배포하려는 실무 환경에 큰 의미를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기