DR2Seg 효율적인 추론 세분화를 위한 두 단계 롤아웃
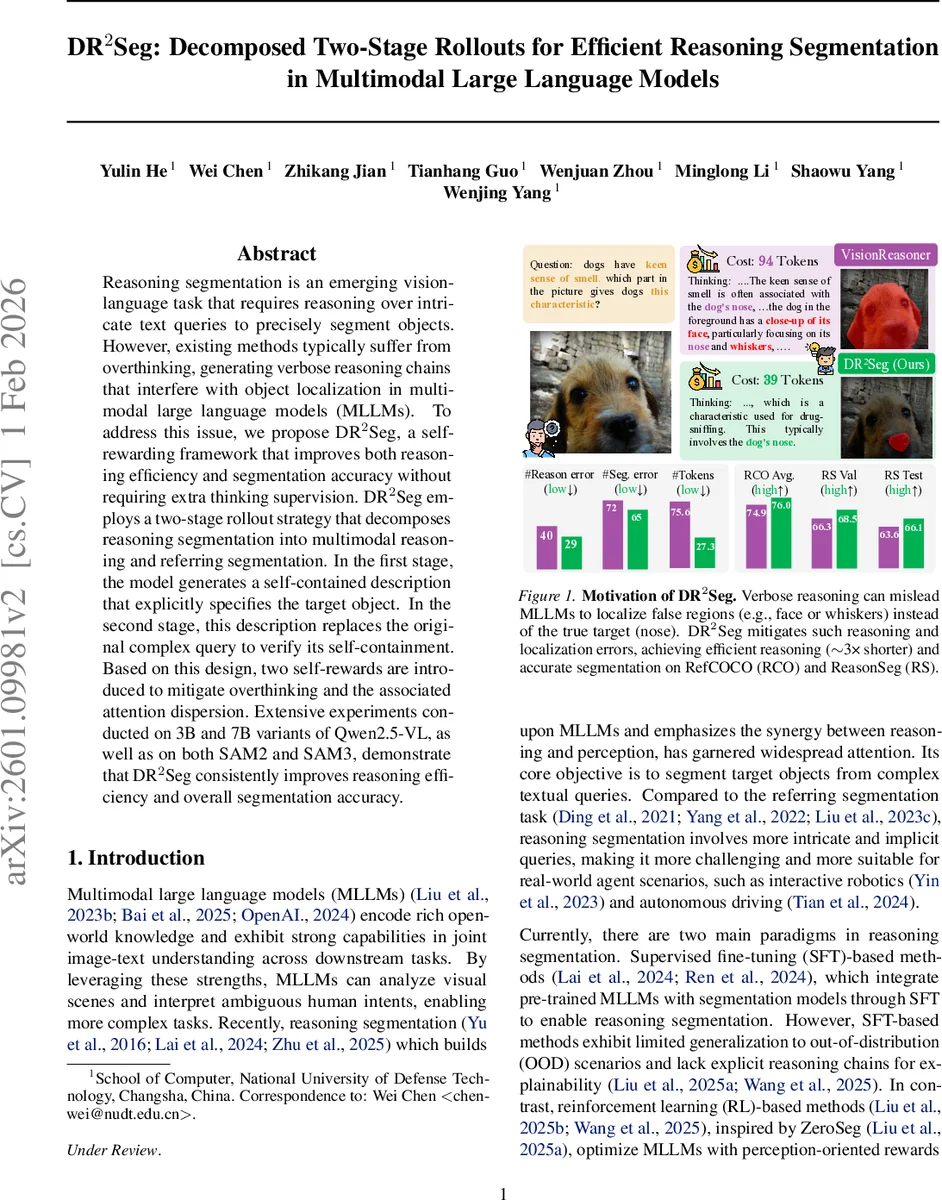
초록
DR2Seg은 멀티모달 대형 언어 모델이 복잡한 텍스트 질의에 대해 과도한 추론(오버싱킹)을 피하도록 설계된 자체 보상 프레임워크이다. 모델은 첫 번째 단계에서 목표 객체를 명시하는 자체 포함(description) 문장을 생성하고, 두 번째 단계에서 이 설명만을 입력으로 다시 추론한다. 설명이 올바른 답을 도출하면 설명 자체에 보상이 주어지고, 두 단계의 추론 길이를 비교해 짧은 추론을 장려하는 길이 기반 보상이 추가된다. 이러한 두 단계 롤아웃과 자체 보상은 별도의 전문가 모델이나 외부 라벨 없이도 추론 효율성을 3배 가량 향상시키고, 세그멘테이션 정확도를 전반적으로 끌어올린다.
상세 분석
DR2Seg은 기존의 Reasoning Segmentation 접근법이 갖는 “오버싱킹” 문제를 근본적으로 해결하고자 두 단계 롤아웃(rollout) 전략을 도입한다. 첫 번째 롤아웃에서는 이미지 I와 복합 질의 Q를 입력받아
두 번째 원칙은 R2가 R1보다 짧아야 한다는 길이 기반 보상 R_len이다. 토큰 길이 N1=|R1|, N2=|R2|를 비교해 N2<N1이면 보상을 1에 가깝게 주고, 그렇지 않으면 0에 가깝게 만든다. 또한 절대적인 길이 기준 N0와 가중치 γ를 도입해 무분별한 토큰 증가를 억제한다. R_len은 조건부 보상 ˜R_len과 결합해, 어느 롤아웃에서도 정확도 보상이 전혀 없을 경우 길이 제약을 완화한다.
보상 함수는 기존 VisionReasoner의 R_base(형식 보상, 반복 방지, 정답 정확도)와 R_desc, ˜R_len을 곱셈 형태로 결합해 R_total= (R_base+R_desc)·˜R_len 로 정의한다. 이렇게 설계된 보상은 모델 자체가 스스로 자신의 추론 품질을 평가하도록 만든 자기 보상(self‑rewarding) 메커니즘이며, 외부 라벨이나 별도 전문가 모델이 필요하지 않다.
학습 최적화에는 Group‑Relative Policy Optimization(GRPO)을 사용한다. GRPO는 미니배치 수준에서 그룹별 보상을 평균해 정책 업데이트를 수행함으로써 보상 신호의 분산을 감소시키고, 안정적인 강화학습을 가능하게 한다.
실험에서는 Qwen2.5‑VL 3B/7B 모델에 DR2Seg을 적용하고, SAM2와 SAM3 세그멘테이션 백본을 연결해 RefCOCO, ReasonSeg 등 여러 벤치마크에서 평가하였다. 결과는 평균 토큰 수가 약 3배 감소하면서도 mIoU와 정확도 지표가 일관되게 상승함을 보여준다. 특히 OOD(Out‑of‑Distribution) 상황에서도 기존 SFT 기반 방법보다 높은 일반화 능력을 보였다.
핵심 기여는 (1) 외부 보상 모델 없이도 자체 보상으로 추론 효율과 정확도를 동시에 개선한 프레임워크, (2) 멀티모달 추론과 객체 지시를 명확히 분리하는 두 단계 롤아웃 설계, (3) 길이 기반 보상을 통해 과도한 토큰 사용을 억제한 점이다. 이러한 설계는 향후 멀티모달 LLM이 복합 질의를 처리하면서도 실시간 응용(로봇, 자율주행 등)에서 요구되는 계산 효율성을 확보하는 데 중요한 방향성을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기