잠재적 논쟁: LLM 내부 사고를 해석하는 새로운 서프라이즈 프레임워크
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
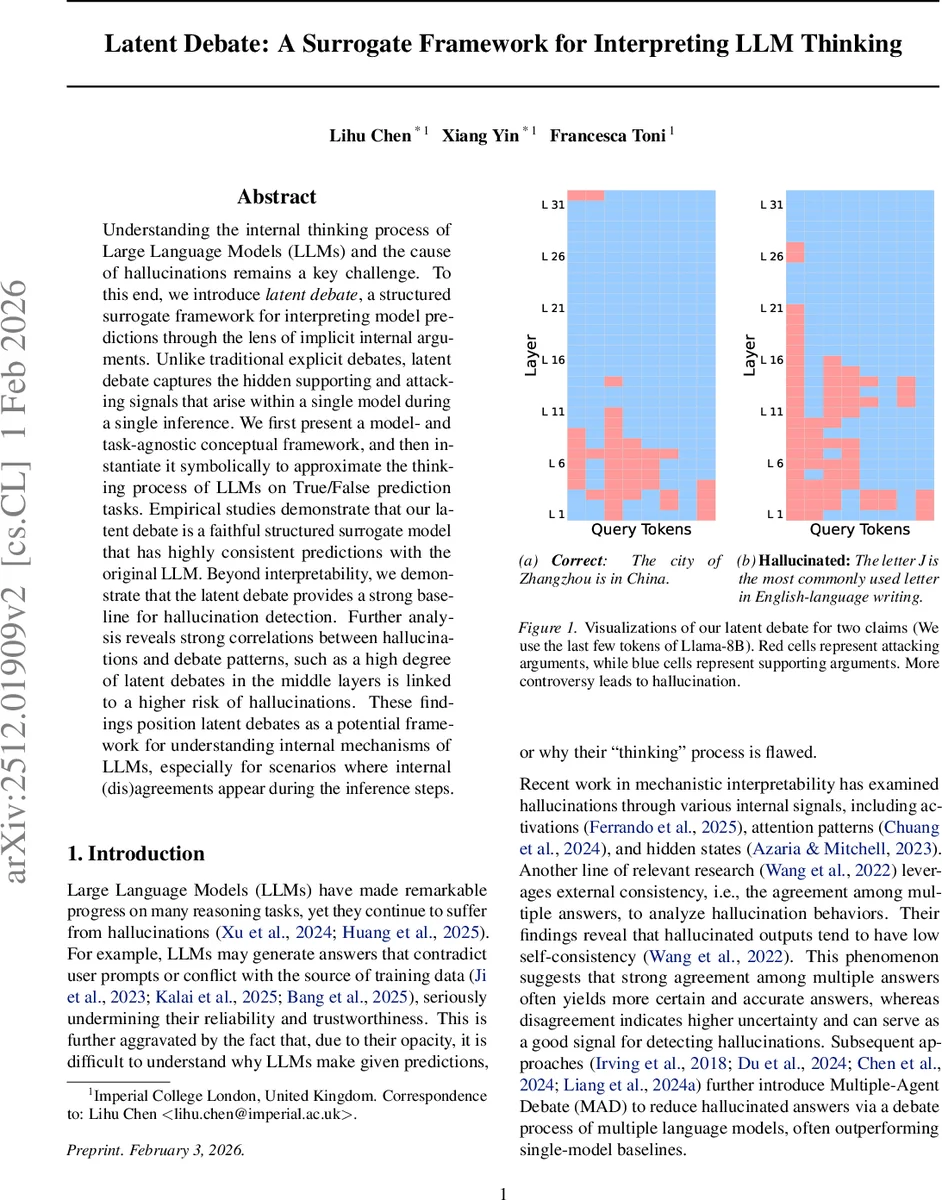
본 논문은 단일 LLM 내부에서 발생하는 숨은 ‘지원·공격’ 신호를 논쟁 형태로 모델링하는 “잠재적 논쟁(Latent Debate)” 프레임워크를 제안한다. 이를 통해 True/False 판단 과정을 구조화된 서러게이트 모델로 근사하고, 층별 논쟁 패턴이 환각(hallucination)과 강하게 연관됨을 실증한다.
상세 분석
잠재적 논쟁은 기존의 다중 에이전트 Debate 혹은 Self‑Consistency와 달리, 하나의 모델 내부에서 동시에 존재하는 상반된 신호들을 “잠재적 주장(latent arguments)”으로 정의한다. 논문은 이 개념을 세 가지 추상 요소—잠재적 주장, 주장 해석기, 사고 모듈—로 정형화하고, 이를 Transformer 기반 LLM에 구체화한다.
- 잠재적 주장: 각 레이어 l 의 토큰 n 에 대한 은닉 상태 h⁽ˡ⁾ₙ 을 직접 활용한다. 이는 모델이 입력에 대해 단계별로 형성하는 내적 표현이며, 지원·공격 성향을 내포한다.
- 주장 해석기: 은닉 상태를 언어 토큰 공간으로 투사하는 unembedding 행렬 W_unemb 을 이용해 Softmax를 적용, “True”와 “False” 토큰에 대한 확률을 추출한다. 이 확률값을
댓글 및 학술 토론
Loading comments...
의견 남기기