Mixtera 대규모 모델 훈련을 위한 데이터 플레인
초록
Mixtera는 기존 분산 파일시스템 위에 구축되는 읽기 전용 데이터 플레인으로, 훈련 데이터 샘플을 속성별 비율과 순서로 선언적으로 지정하고 동적으로 조정할 수 있게 한다. 메타데이터 인덱싱·청크 스트리밍 방식을 통해 대규모 클러스터(256 GH200 슈퍼칩)에서도 학습 속도를 저해하지 않으며, 최신 동적 혼합 알고리즘인 ADO를 손쉽게 적용한다.
상세 분석
본 논문은 대규모 언어·시각 모델 훈련 시 데이터 혼합이 모델 정확도에 미치는 영향을 강조하고, 현재 오픈소스 생태계가 제공하는 파일‑디렉터리 기반 필터링·혼합 방식이 확장성·유연성에서 한계가 있음을 지적한다. Mixtera는 이러한 한계를 극복하기 위해 클라이언트‑서버 구조를 채택한다. 서버는 한 번의 인덱싱 단계에서 모든 샘플 메타데이터(소스, 언어, 토큰 수, 품질 점수 등)를 저장하고, 훈련 시작 시 선언적 SPJ‑style 질의에 따라 청크(고정 크기 포인터 리스트)를 생성·스트리밍한다. 클라이언트는 청크에 포함된 포인터를 이용해 실제 파일을 읽어오므로, 데이터 자체는 복제되지 않으며 I/O 병목을 최소화한다.
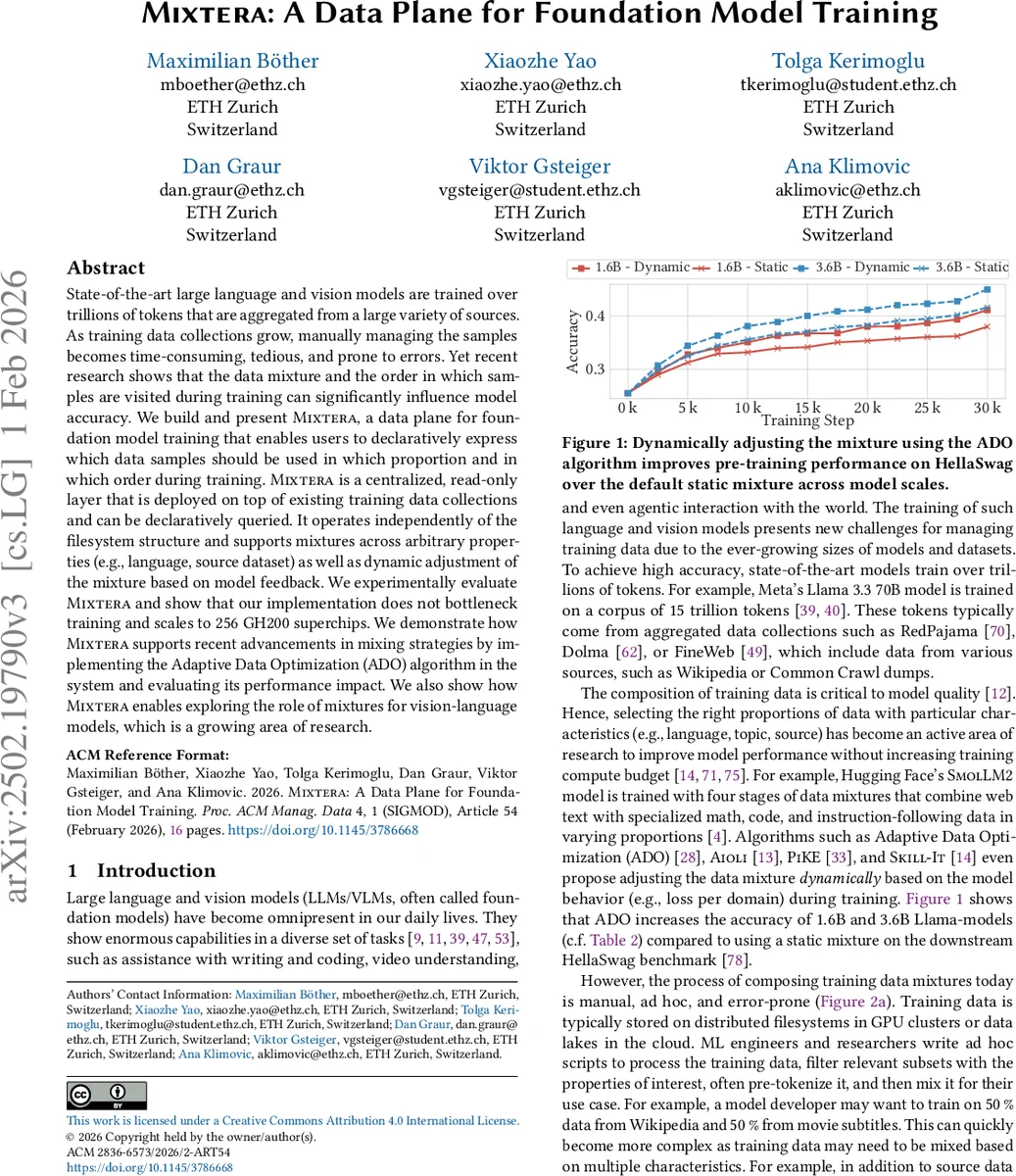
동적 혼합을 지원하는 핵심 메커니즘은 청크 생성 시 현재 혼합 비율을 반영하고, 훈련 중 피드백(예: 도메인별 손실, 학습 속도)으로 비율을 실시간 재계산해 새로운 청크를 발행한다. 이를 통해 ADO와 같은 알고리즘을 별도 구현 없이 Mixtera에 플러그인 형태로 삽입할 수 있다. 실험에서는 1.6 B와 3.6 B 규모 Llama 모델에 ADO를 적용했을 때 HellaSwag 정확도가 정적 혼합 대비 1.2~1.5 % 상승함을 보였으며, 256 GH200 슈퍼칩 환경에서도 데이터 플레인이 전체 학습 throughput에 미치는 영향이 2 % 이하에 그쳤다.
또한 Mixtera는 기존 데이터 로더와 비교해 다음과 같은 장점을 제공한다. (1) 파일 시스템 구조에 독립적인 선언적 필터링; (2) 다중 속성(언어·소스·품질 등) 혼합을 단일 질의로 표현; (3) 동적 혼합을 위한 실시간 청크 재생성; (4) 기존 프레임워크(TorchData, Megatron 등)와의 투명한 연동; (5) 메타데이터 기반 라인리지 추적이 가능해 모델‑데이터 매핑을 자동화한다.
한계점으로는 메타데이터 인덱싱 비용이 초기 구축 시 필요하고, 매우 드문 속성에 대한 샘플이 부족할 경우 청크 구성 시 균형을 맞추기 위한 추가 로직이 요구된다는 점을 언급한다. 향후 연구에서는 인덱스 업데이트를 온라인화하고, 샘플 레벨의 비용‑효율적인 재샘플링 전략을 탐색할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기