인간처럼 대화하는 대형 언어 모델 강화
초록
본 논문은 대형 언어 모델(LLM)의 대화 품질을 인간에 가깝게 만들기 위해 직접 선호 최적화(DPO)와 LoRA 기반 파인튜닝을 결합한 방법을 제시한다. 합성 데이터셋을 구축해 ‘인간‑유사’와 ‘형식적’ 응답을 구분하고, 이를 보상 신호로 활용해 모델을 훈련시켰다. 인간‑유사 모델은 인간‑유사성 평가에서 80~90%의 선호도를 얻었으며, 기존 벤치마크 성능 저하가 최소화되었다.
상세 분석
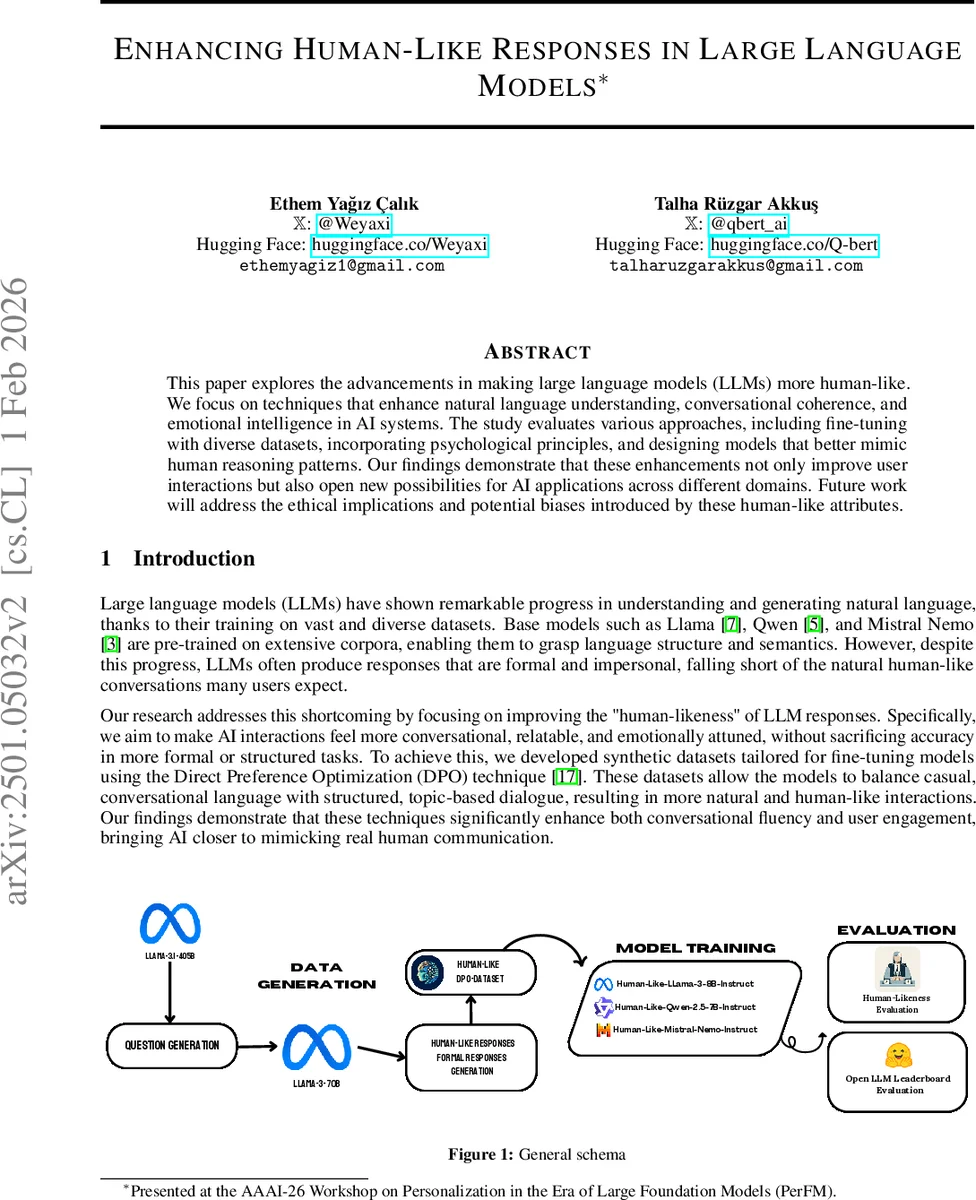
이 연구는 LLM이 실제 인간과 구분하기 어려운 대화를 생성하도록 하는 두 가지 핵심 기술을 결합한다. 첫째, ‘Human‑Like‑DPO‑Dataset’이라 명명된 합성 데이터셋을 생성하기 위해 Llama 3 70B와 405B 모델을 활용하였다. 질문 생성 단계에서는 개인 경험, 가정 상황, 가상의 시나리오 등을 포함한 자연스러운 대화형 질문을 만들고, 동일 질문에 대해 두 종류의 시스템 프롬프트를 적용해 ‘인간‑유사’ 응답과 ‘형식적·비인간적’ 응답을 각각 생성하였다. 이렇게 얻은 10 884개의 샘플은 256개의 토픽으로 클러스터링되어 다양성과 균형을 확보하였다.
둘째, 파인튜닝 단계에서는 Low‑Rank Adaptation(LoRA)와 Direct Preference Optimization(DPO)을 연계했다. LoRA는 r = 8, α = 4, dropout = 0.05 등 보수적인 하이퍼파라미터를 사용해 모델의 핵심 가중치를 크게 변형하지 않으면서 특정 레이어만 효율적으로 조정한다. DPO는 ‘인간‑유사’ 응답을 선택하고 ‘형식적’ 응답을 거부하도록 보상 함수를 설계함으로써, 훈련 과정에서 모델이 인간‑친화적인 언어 스타일을 선호하도록 유도한다. 훈련은 2×NVIDIA A100 80 GB GPU에서 수행되었으며, Llama‑3‑8B‑Instruct, Qwen‑2.5‑7B‑Instruct, Mistral‑Nemo‑Instruct 등 세 모델에 적용하였다.
평가에서는 Gradio 기반 익명 투표 시스템을 이용해 500개의 질문에 대해 2 000개의 투표를 수집하였다. 고등학생 및 성인 등 다양한 배경의 비원어민·원어민 참가자들이 ‘인간‑유사’ 모델을 7990%의 비율로 선호했으며, 특히 공식 모델이 자주 삽입하는 “I am just a language model” 같은 메타 발언을 회피한 점이 긍정적으로 작용했다. 벤치마크 평가(Open LLM Leaderboard)에서는 IFEval 점수가 약 10.6점 감소했지만, BBH, Math Level 5, GPQA, MuSR, MMLU‑Pro 등 주요 지표에서는 변동이 미미하거나 약간의 향상이 관찰되었다.
한계점으로는 데이터셋 생성에 사용된 합성 질문이 실제 사용자 질의와 완전히 일치하지 않을 가능성, 평가 참여자의 영어 숙련도 차이에 따른 편향, 그리고 ‘인간‑유사성’ 강화가 과도한 감정 모방으로 이어질 경우 윤리적·사회적 위험이 존재한다는 점을 언급한다. 향후 연구에서는 실제 사용자 로그 기반 데이터와 다문화·다언어 환경을 반영한 평가, 그리고 감정 표현의 투명성 및 책임성을 강화하는 메커니즘을 탐구할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기