CLAMP: 3D 다중 시점 동작 정보 사전 학습으로 로봇 조작의 정밀도 향상
초록
본 연구는 로봇의 정밀 조작을 위해 3D 공간 정보와 로봇 동작을 함께 학습하는 새로운 사전 학습 프레임워크인 CLAMP를 제안한다. RGB-D 영상으로 생성한 포인트 클라우드로부터 깊이와 3D 좌표를 포함한 다중 시점 영상을 재렌더링하고, 대조 학습을 통해 객체의 3D 기하학적 정보와 로봇 동작 패턴을 연관 지어 학습한다. 사전 학습된 표현을 사용하여 제한된 시범 데이터로 정책을 미세 조정할 때, 학습 효율성과 성능이 크게 향상되며, 다양한 시뮬레이션 및 실제 작업에서 최신 기법을 능가하는 성능을 보인다.
상세 분석
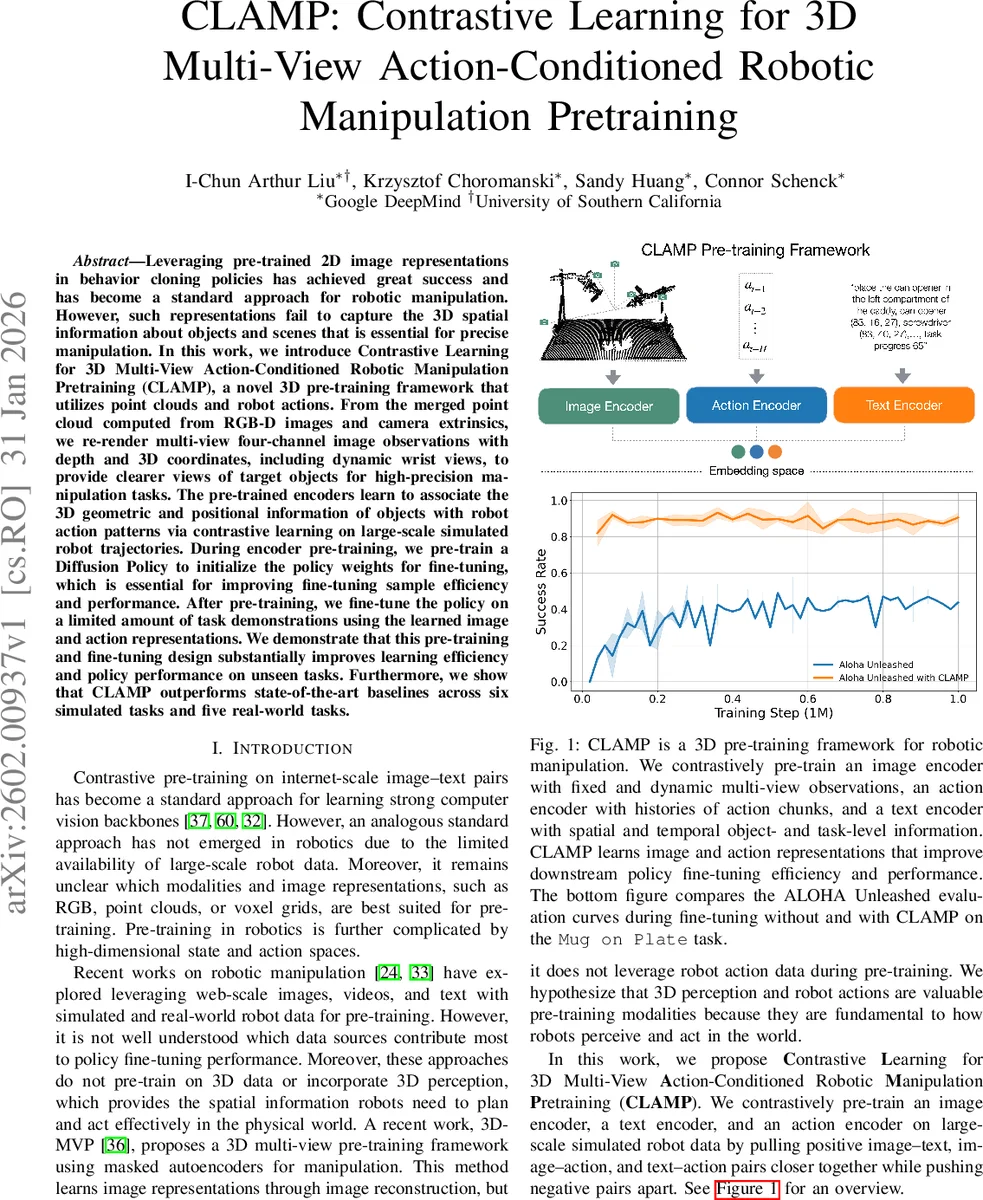
CLAMP의 핵심 기술적 혁신은 크게 세 가지로 요약된다. 첫째, 3D 기하 정보와 동작 패턴의 결합적 대조 학습이다. 기존 2D 기반 사전 학습은 공간적 이해에 한계가 있었으나, CLAMP는 포인트 클라우드로부터 재렌더링한 깊이(Depth) 및 3D 좌표(XYZ) 채널을 포함한 4채널 다중 시점 영상을 사용한다. 이를 Vision Transformer(ViT) 기반 이미지 인코더에 입력하고, 로봇의 과거 동작 히스토리를 처리하는 액션 인코더, 텍스트 인코더와 함께 삼중 대조 학습(Image-Text, Image-Action, Text-Action)을 수행한다. 이를 통해 ‘어떤 3D 장면에서 어떤 동작이 발생했는지’에 대한 보다 풍부한 표현을 학습한다.
둘째, 다이나믹 워스트 뷰(Dynamic Wrist View)와 STRING 상대 위치 인코딩의 도입이다. 고정된 시점(오버헤드, 전방-좌측, 후방-우측) 외에 두 개의 로봇 손목에 부착된 가상 카메라 뷰를 활용함으로써, 조작 중 발생하는 가림 현상을 줄이고 대상 객체에 대한 더 명확한 시야를 제공한다. 이는 고정밀도 작업 성능 향상의 핵심 요소이다. 또한, ViT에 STRING 상대 위치 인코딩을 적용하여, 서로 다른 시점의 이미지 패치라도 3D 공간에서 물리적으로 가까이 위치하면 어텐션 메커니즘을 통해 연관될 수 있도록 하였다. 이는 3D 좌표 정보를 어텐션 가중치 계산에 직접 반영한 혁신적인 접근법이다.
셋째, 인코더 사전 학습과 Diffusion Policy 사전 학습의 병행이다. CLAMP는 표현(인코더) 학습 뿐만 아니라, 하위 작업인 행동 생성기(Diffusion Policy)의 가중치도 사전 학습 단계에서 초기화한다. 사전 학습된 인코더의 임베딩을 고정(frozen)한 채, Diffusion Policy의 트랜스포머 인코더/디코더만 대규모 시뮬레이션 궤적 데이터로 학습한다. 이는 미세 조정 단계에서 정책 네트워크가 무작위 초기화에서 시작하는 것보다 훨씬 빠르게 수렴하고 더 높은 성능에 도달하는 데 결정적으로 기여한다.
실험 결과는 이러한 설계의 유효성을 입증한다. 3D-MVP, RVT 등 최신 3D/다중 시점 기반 베이스라인 대비 우수한 성능을 보였으며, 특히 다이나믹 워스트 뷰와 정책 사전 학습의 조합이 가장 큰 성능 향상을 가져왔다. 이는 로봇 조작을 위한 사전 학습이 단순히 좋은 시각 표현을 학습하는 것을 넘어, 표현 학습과 정책 구조 학습을 통합적으로 최적화해야 함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기