메시 기반 직접 해석을 위한 빠른 희소 행렬 순열
초록
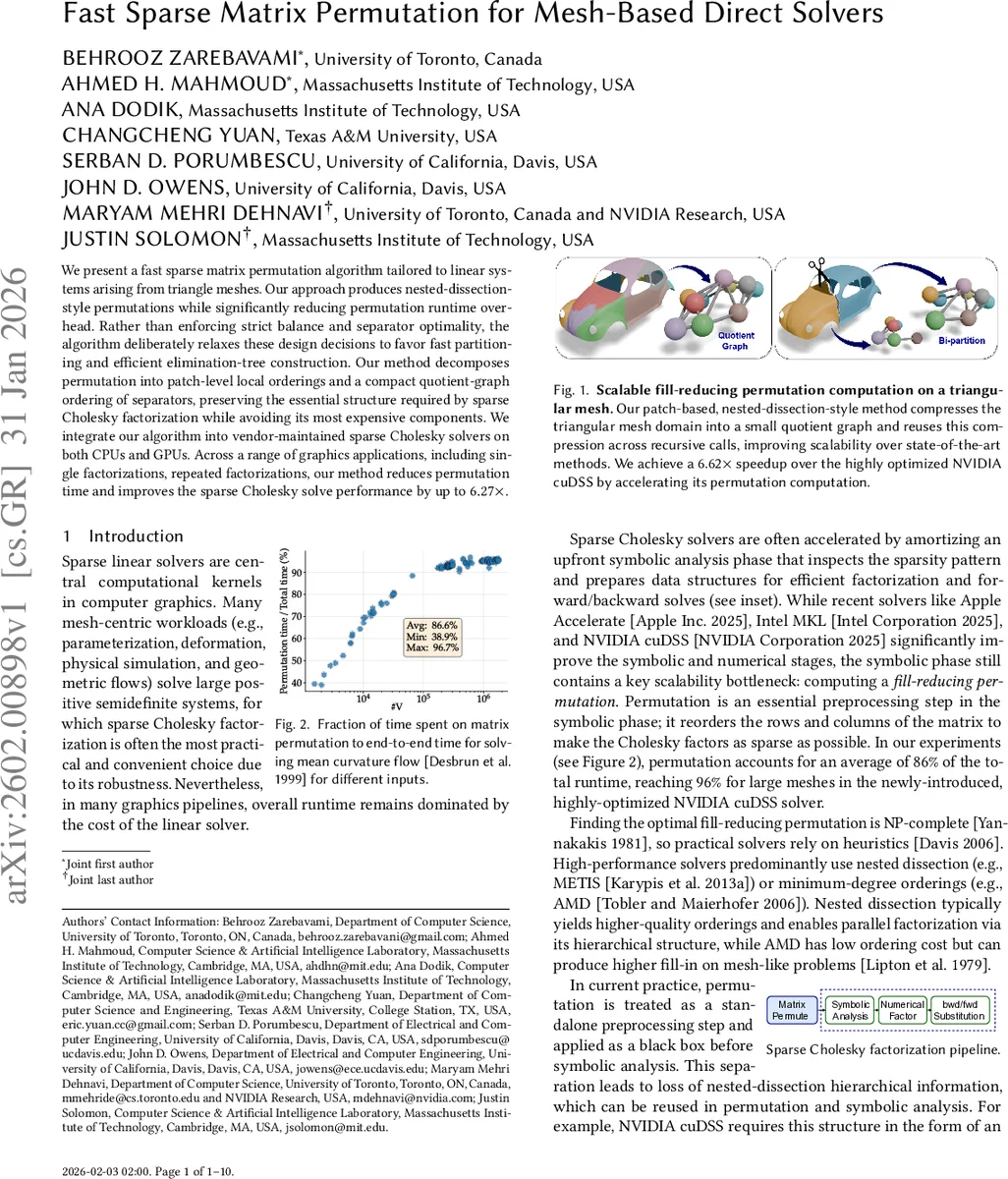
본 논문은 삼각형 메시에 의해 생성되는 대규모 양의 준정치 행렬에 특화된 빠른 순열 알고리즘을 제안한다. 패치 기반의 중첩 절단(Nested‑Dissection) 방식을 사용해 그래프를 소규모의quotient‑graph로 압축하고, 이 압축된 그래프에서 분리자를 찾음으로써 전통적인 METIS‑계열 분할기보다 10배 가량 빠른 순열을 얻는다. 동시에 엘리미네이션 트리를 직접 생성해 심볼릭 단계와의 연계를 최적화하고, CPU·GPU 양쪽의 상용 Cholesky 솔버에 적용해 전체 솔루션 파이프라인에서 최대 6.6배의 속도 향상을 입증한다.
상세 분석
이 논문은 그래픽스와 물리 시뮬레이션에서 빈번히 등장하는 라플라시안·헬름홀츠와 같은 SPD(Positive Semi‑Definite) 행렬을 대상으로, 기존의 순열 단계가 전체 솔버 파이프라인에서 차지하는 비중이 80% 이상에 달한다는 실험적 사실을 강조한다. 전통적인 순열 기법은 최소 차수(AMD)와 중첩 절단(ND) 두 갈래로 나뉘지만, AMD는 순열 비용은 낮지만 메쉬 구조에서는 채워짐(fill‑in)이 크게 늘어나고, ND는 높은 품질을 제공하지만 균형과 최소 분리자 크기를 강제하는 과정에서 복잡한 그래프 코어싱·리파인 단계가 병목이 된다.
저자들은 이러한 문제점을 해결하기 위해 “패치”라는 중간 추상화를 도입한다. 메쉬를 사전에 정의된 혹은 자동으로 생성된 패치 집합으로 분할하고, 각 패치를 그래프 정점 집합의 그룹으로 매핑한다(gmap). 이렇게 구성된 quotient‑graph는 원본 그래프 대비 정점 수가 수십 배 이상 감소하므로, ND 단계에서 분리자를 찾는 탐색 공간이 크게 축소된다. 중요한 점은 패치 수준에서 균형과 최소 분리자 크기의 엄격한 제약을 포기하고, 대신 빠른 k‑means 기반 클러스터링을 사용해 패치를 생성한다는 것이다. 이로써 “품질‑속도 트레이드오프”를 명시적으로 제어한다.
알고리즘 흐름은 크게 네 단계로 정리된다.
- 패치 생성 – RXMesh의 GPU k‑means 혹은 기존 애플리케이션에서 제공되는 패치를 활용한다.
- 그룹 맵 구축 – 메쉬 정점 ↔ 행렬 정점 매핑을 통해 각 행렬 정점을 해당 패치 그룹에 할당한다.
- 패치‑가이드 ND – quotient‑graph에 대해 재귀적으로 중첩 절단을 수행한다. 각 재귀 단계에서 얻어진 분리자 집합은 실제 행렬 정점 수준으로 풀어헤쳐지고, 동시에 엘리미네이션 트리(etree)의 노드로 기록된다.
- 전역 순열 구성 – 완성된 etree를 전위 순회(preorder)하여 최종 순열 벡터를 만든다.
이 과정에서 엘리미네이션 트리를 순열과 동시에 생성함으로써, 기존 솔버가 별도로 요구하던 “etree 구축” 단계가 사라진다. 또한, quotient‑graph를 한 번만 구축하고 재귀 호출마다 재사용하기 때문에, METIS와 같은 다단계 코어싱·파인 튜닝이 필요 없는 구조가 된다.
성능 평가에서는 NVIDIA cuDSS, Intel MKL, Apple Accelerate 등 최신 상용 라이브러리와 직접 비교한다. 단일 팩터라이제이션 상황에서 순열 시간만 10.27×(기하 평균 4.58×) 가속되었으며, 전체 파이프라인(순열 + 심볼릭 + 수치)에서는 평균 3.51×, 최고 6.62×의 속도 향상을 기록한다. 특히 대규모 메쉬(수백만 정점)에서는 순열이 전체 실행 시간의 96%를 차지하던 기존 상황을 15% 이하로 감소시켜, GPU 메모리 대역폭과 연산 자원을 효율적으로 활용할 수 있게 된다.
한계점으로는 패치 품질에 따라 최종 fill‑in이 다소 증가할 수 있다는 점이다. 저자들은 실험적으로 “품질 저하가 전체 실행 시간에 미치는 영향은 순열 가속 효과에 비해 미미”하다고 주장하지만, 매우 높은 정확도가 요구되는 과학·공학 시뮬레이션에서는 여전히 최적 ND(균형·최소 분리자)와의 차이가 문제될 수 있다. 또한, 현재 구현은 정점 기반 스칼라 시스템에 최적화돼 있으며, 블록 구조(예: 구조역학의 3×3 Hessian)에서는 그룹 매핑 단계에서 추가적인 메모리 관리가 필요하다.
향후 연구 방향으로는 (1) 동적 메쉬 변화에 대한 패치 재사용 전략, (2) 하이브리드 AMD + 패치‑ND 혼합 기법을 통한 품질‑속도 균형 최적화, (3) 멀티‑GPU 환경에서 quotient‑graph를 분산 처리하는 스케일‑아웃 설계 등을 제시한다.
전반적으로 이 논문은 “순열 단계가 전체 솔버 파이프라인의 병목”이라는 실질적 문제를 정확히 짚어내고, 그래픽스·시뮬레이션 워크플로우에 특화된 경량 ND 구현을 통해 실용적인 성능 향상을 달성한 점이 큰 의의이다.
댓글 및 학술 토론
Loading comments...
의견 남기기