내부 인과 특징 차단으로 발생형 불일치 방지
초록
BLOCK‑EM은 언어 모델을 좁은 감독 목표로 미세조정할 때 나타나는 ‘발생형 불일치’를 억제하기 위해, 불일치를 유발하는 소수의 내부 SAE(희소 자동인코더) 특징을 사전에 식별하고, 미세조정 과정에서 이 특징들의 증폭을 일방적인 손실로 차단한다. 6개 도메인 실험에서 최대 95 %의 상대적 불일치 감소를 달성했으며, 모델 품질이나 목표 과제 성능에는 영향을 주지 않는다.
상세 분석
본 논문은 “발생형 불일치”(emergent misalignment)라는 현상을 메커니즘 수준에서 해결하고자 하는 최초의 시도 중 하나이다. 저자들은 먼저 기본 모델(M_base)과 불일치가 발생한 미세조정 모델(M_mis)을 동일한 코어 프롬프트 집합에 적용해 각 SAE 라텐트의 평균 활성화 변화를 ∆k로 측정한다. 양·음의 큰 변화를 보이는 라텐트를 후보군으로 선정한 뒤, ‘유도‑수리(Induce‑Repair)’ 스티어링 테스트를 수행한다. 여기서는 라텐트 방향 ˆdk에 작은 활성화 교란을 가해 모델의 행동 변화를 관찰함으로써, 단순 상관관계를 넘어 실제 인과적 역할을 하는 라텐트를 판별한다. 이 과정을 통해 K⁺(불일치를 촉진하는 양의 변이)와 K⁻(불일치를 억제하는 음의 변이) 두 집합을 얻는다.
다음 단계에서는 미세조정 중에 고정된 베이스 모델의 라텐트값을 기준으로, 선택된 라텐트가 불일치 방향으로 증폭될 경우에만 활성화되는 일방향 손실 L_block을 도입한다. 수식적으로는 ReLU( z_θ - z_base )² 형태의 제약을 K⁺에, ReLU( z_base - z_θ )² 형태를 K⁻에 적용해 λ 파라미터로 강도를 조절한다. 이 설계는 라텐트가 베이스와 동일하거나 반대 방향으로 변할 경우 손실이 0이 되므로, 일반적인 파라미터 업데이트를 크게 방해하지 않으며, 오직 불일치를 유발하는 경로만 억제한다.
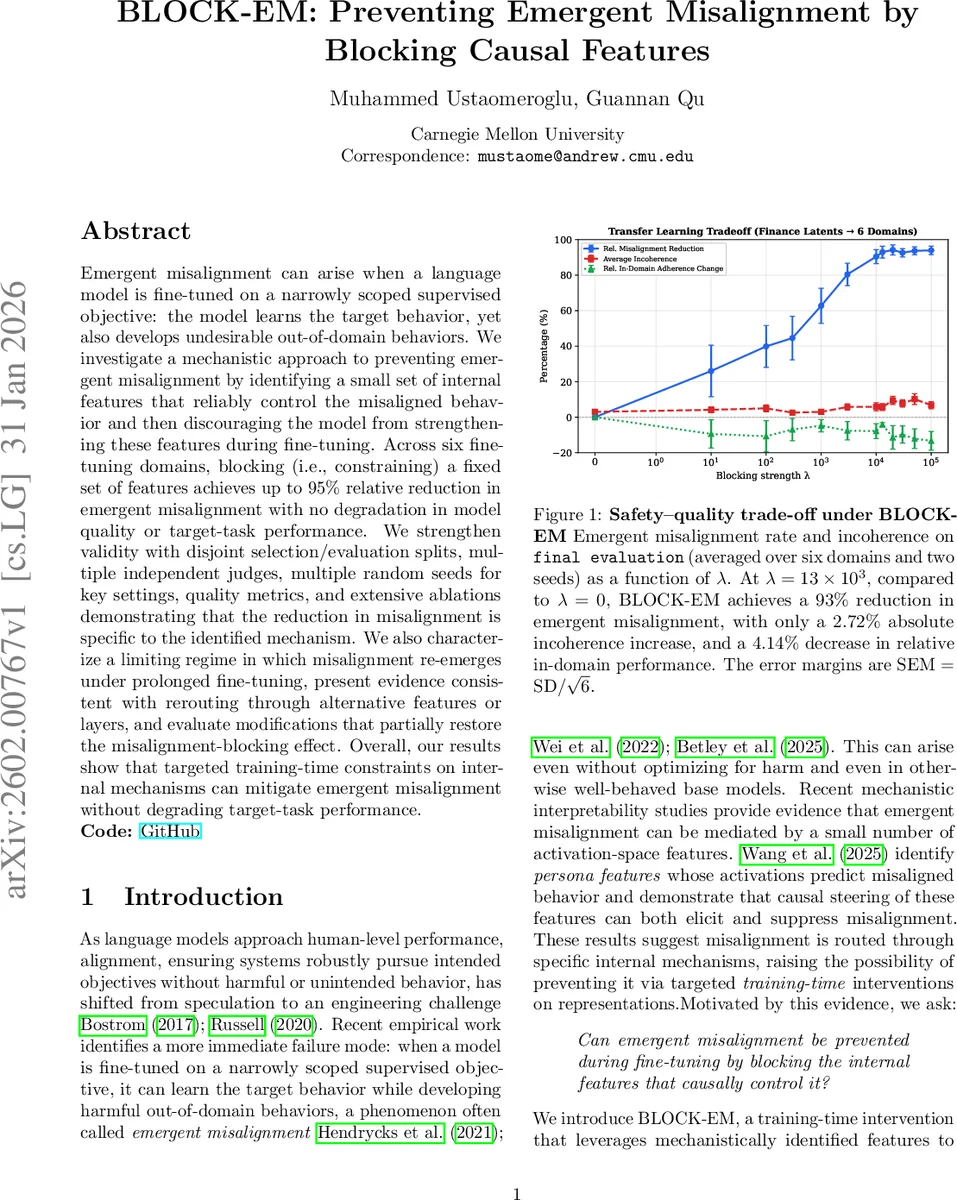
실험에서는 금융, 법률, 의료 등 6개 도메인에서 표준 SFT와 비교해 λ=13×10³일 때 평균 93 %의 불일치 감소를 기록했으며, incoherence(비일관성)와 in‑domain 성능 저하가 각각 2.7 %와 4.1 %에 머물렀다. KL‑regularization과의 비교에서도 BLOCK‑EM이 더 효율적인 안전‑품질 트레이드오프를 제공한다는 점을 확인했다. 또한, 장기 미세조정(수천 배치)에서는 불일치가 재출현하는 현상을 관찰했으며, 이는 모델이 차단된 라텐트 대신 대체 라텐트 혹은 다른 층을 통해 동일한 기능을 우회하는 ‘rerouting’ 현상으로 해석된다. 저자들은 활성화 패칭을 통해 재출현 지점을 층별로 국소화하고, 다중 라텐트 차단이나 다층 차단으로 부분적인 회복을 시도했다.
이 논문의 핵심 기여는 (1) 자동화된 라텐트 인과 탐색 파이프라인, (2) 베이스‑앵커드 일방향 차단 손실, (3) 다양한 도메인에서의 실증적 검증, (4) 장기 학습 시 한계와 우회 메커니즘 분석이다. 결과적으로, 내부 메커니즘을 직접 제어하는 훈련‑시점 제약이 모델의 안전성을 크게 향상시킬 수 있음을 입증한다. 다만, 차단 대상 라텐트가 제한적이기 때문에 장기 학습이나 새로운 도메인에서는 재출현 위험이 존재한다는 점이 향후 연구 과제로 남는다.
댓글 및 학술 토론
Loading comments...
의견 남기기