스펙트럼 불균형이 저랭크 연속 적응에서 망각을 초래한다
초록
본 논문은 저랭크 적응(LoRA) 방식이 연속 학습 시 나타내는 특이한 스펙트럼 불균형을 규명하고, 이를 완화하기 위해 적응 에너지를 균형 있게 배분하는 제한된 Stiefel 다양체 최적화 기법인 EBLoRA를 제안한다. 실험 결과, 기존 파라미터 효율적 연속 학습 방법들을 크게 앞서며 뒤쪽·앞쪽 망각을 모두 감소시킨다.
상세 분석
본 연구는 대규모 사전학습 비전‑언어 모델(VLM)을 연속적으로 파인튜닝할 때, 저랭크 적응(LoRA) 매개변수가 보여주는 스펙트럼 특성을 면밀히 분석한다. LoRA 업데이트 ΔWₜ는 SVD를 통해 σₜ,i·uₜ,i·vₜ,iᵀ 형태의 rank‑1 성분 집합으로 분해될 수 있으며, 여기서 σₜ,i는 각 성분의 적응 에너지(스케일)를, uₜ,i와 vₜ,i는 입력·출력 방향을 정의한다. 실험적으로 저랭크 업데이트는 몇 개의 지배적인 singular value가 전체 에너지의 대부분을 차지하는 ‘긴 꼬리’ 분포를 보이며, 학습이 진행될수록 이 불균형이 더욱 심화된다. 이러한 불균형은 두 가지 위험을 내포한다. 첫째, 소수의 강력한 성분이 기존 지식과 겹치면 과도한 파라미터 변동으로 이전 작업이 손상된다(뒤쪽 망각). 둘째, 이후 작업이 동일한 강한 성분을 다시 사용하려 할 때 경쟁이 발생해 새로운 업데이트가 기존 성분을 방해한다(앞쪽 망각). 저자들은 이를 검증하기 위해 각 작업별 LoRA를 독립적으로 학습한 뒤 단순 합산(merge)하는 실험을 수행했으며, 직접 합산 시 NAI(Normalized Accuracy Improvement)가 크게 감소함을 확인했다. 반면, singular value를 평균값으로 평탄화(smoothing)한 후 합산하면 NAI 감소폭이 현저히 완화되어, 스펙트럼 균형이 연속 학습 안정성에 기여함을 입증한다.
이러한 통찰을 바탕으로 저자들은 업데이트를 두 단계로 분리한다. ΔWₜ = sₜ·Uₜ·Vₜᵀ 로 표현해, 스칼라 sₜ는 전체 적응 에너지, Uₜ와 Vₜ는 각각 orthonormal 열을 갖는 행렬로 정의한다. 여기서 Uₜ는 이전 작업들의 중요한 gradient 방향을 담은 행렬 Gₜ₋₁과 직교하도록 제약한다(Gₜ₋₁ᵀ·Uₜ = 0). 이는 Stiefel 다양체(orthonormality)와 선형 제약을 동시에 만족하는 제한된 Stiefel manifold Mₜ를 형성한다. 최적화는 (sₜ, Uₜ, Vₜ)에 대해 손실 Lₜ를 최소화하는 문제로 정의되며, 표준 SGD/Adam과 같은 1차 최적화기를 그대로 사용하면서도 매 iteration마다 (1) Euclidean gradient를 Mₜ의 접공간에 투영, (2) 옵티마이저 업데이트, (3) 다시 접공간에 투영, (4) 다양체 위로 재수축(retraction)하는 투사 기반 알고리즘을 적용한다. 특히, 접공간 투영은 Gₜ₋₁의 영공간에 대한 프로젝터 P⊥₍G₎와 Stiefel 전형적인 symmetrization을 결합해 구현되며, 재수축 단계는 Y·(YᵀY)^{-½} 형태의 whitening 연산으로 orthonormality와 직교 제약을 동시에 만족한다.
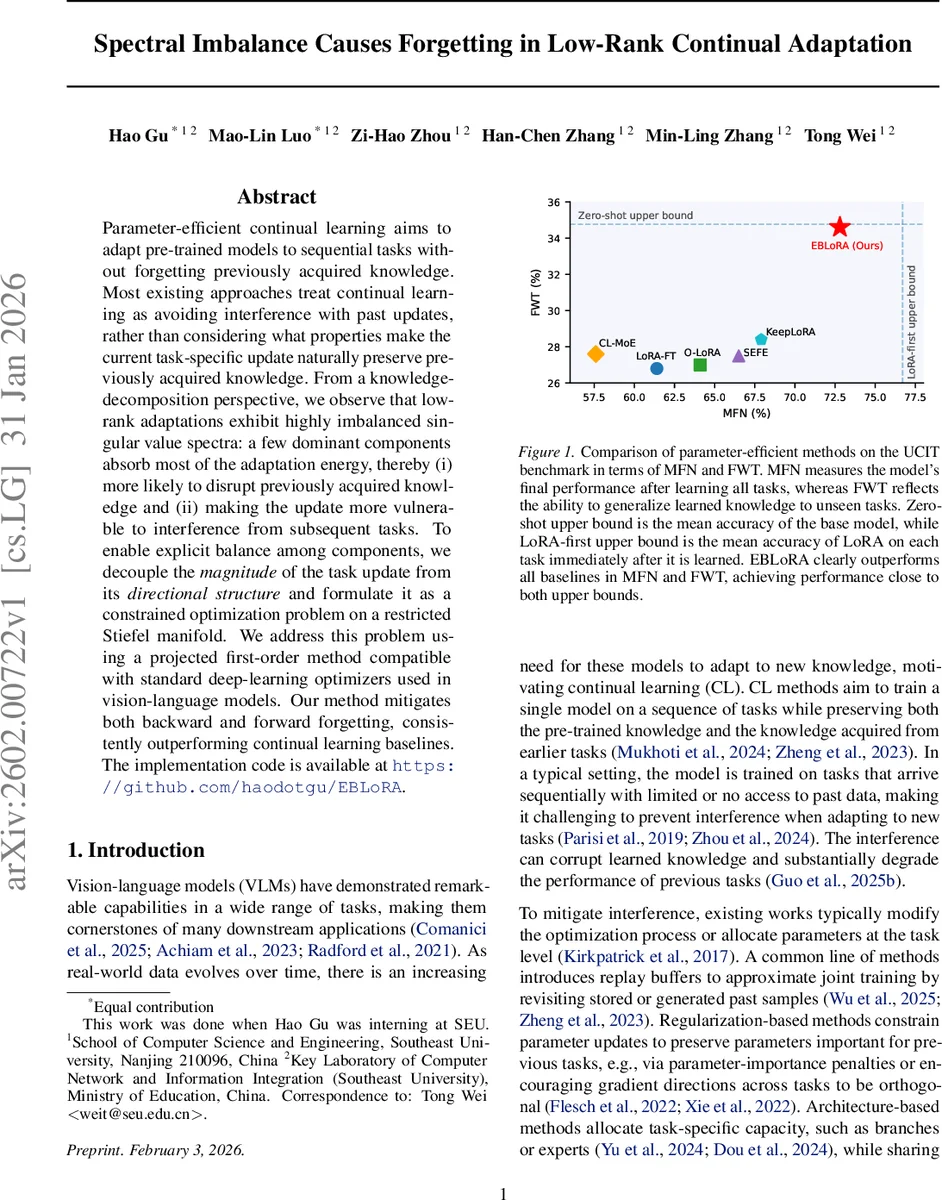
이론적으로 저자들은 제안된 투사·재수축이 Riemannian 기하학 하에서 최적의 근사임을 증명하고, 수렴 속도와 수치 안정성을 분석한다. 실험에서는 UCIT, ImageNet‑R, CLEVR 등 6개 도메인에 걸친 10개 이상의 연속 학습 시나리오를 설정하고, MFN(최종 평균 정확도)과 FWT(전이 학습 성능) 두 지표에서 기존 LoRA‑based, Replay, Regularization, Architecture 기반 방법들을 크게 앞선다. 특히, EBLoRA는 Zero‑shot upper bound(사전학습 모델)와 LoRA‑first upper bound(각 작업 직후 성능) 사이에 위치하며, 스펙트럼 평탄화만 적용한 baseline보다도 일관된 이득을 제공한다.
결과적으로, 이 논문은 “망각은 단순히 최적화 충돌이 아니라, 저랭크 업데이트가 내재한 스펙트럼 불균형”이라는 새로운 원인을 제시하고, 이를 수학적으로 정형화한 제한된 Stiefel manifold 최적화가 연속 학습에서 효과적인 해결책임을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기