JoyAvatar: 텍스트·오디오 조화로 구현한 고표현 아바타 생성
초록
**
JoyAvatar는 트윈‑티처 기반 디스트리뷰션 매칭 디스틸레이션(DMD)과 타임스텝‑조건 CFG를 결합해, 텍스트와 오디오를 동시에 활용한 장시간 고품질 아바타 비디오를 생성한다. 텍스트 정렬, 립싱크, 아이덴티티 유지, 전신 움직임 및 동적 카메라 트래젝터리에서 기존 모델을 크게 앞선다.
**
상세 분석
**
본 논문은 현재 영상 아바타 생성 모델이 텍스트 지시와의 정렬이 약하고, 복합적인 전신 동작·카메라 이동·배경 전환·인간‑물체 상호작용을 다루기 어렵다는 문제점을 정확히 짚어낸다. 이를 해결하기 위해 두 가지 핵심 기술을 제안한다. 첫 번째는 트윈‑티처 강화 DMD이다. 기존 DMD는 단일 교사(실제 스코어 함수)만을 사용하지만, 여기서는 (1) 오디오‑시각 동기화를 담당하는 기존 아바타 교사와 (2) 텍스트 정렬에 특화된 대규모 비디오 기반 모델(Wan2.2‑I2V)을 추가 교사로 도입한다. 두 교사는 각각 오디오·시각과 텍스트 조건에 대한 전문가 수준의 그라디언트를 제공함으로써, 학생 모델이 서로 상충되는 모달리티를 효과적으로 disentangle하고, 텍스트‑주도 움직임을 유지하면서도 정확한 립싱크를 학습한다.
두 번째 혁신은 시간 단계 기반 동적 CFG이다. 확산 과정에서 초기 고노이즈 단계는 전반적인 움직임 구조를 결정하고, 후반 저노이즈 단계는 세밀한 시각적 디테일을 정제한다는 관찰에 기반한다. 따라서 텍스트 CFG 스케일을 초기 단계에서 크게 두어 전신 동작·카메라 트래젝터리와 같은 거시적 제어를 우선시하고, 오디오 CFG 스케일은 후반에 점진적으로 증가시켜 립싱크와 미세한 손동작을 보강한다. 이 스케줄링은 서로 다른 조건이 충돌하는 것을 최소화하고, 각 모달리티가 가장 효과적인 시점에 영향력을 행사하도록 만든다.
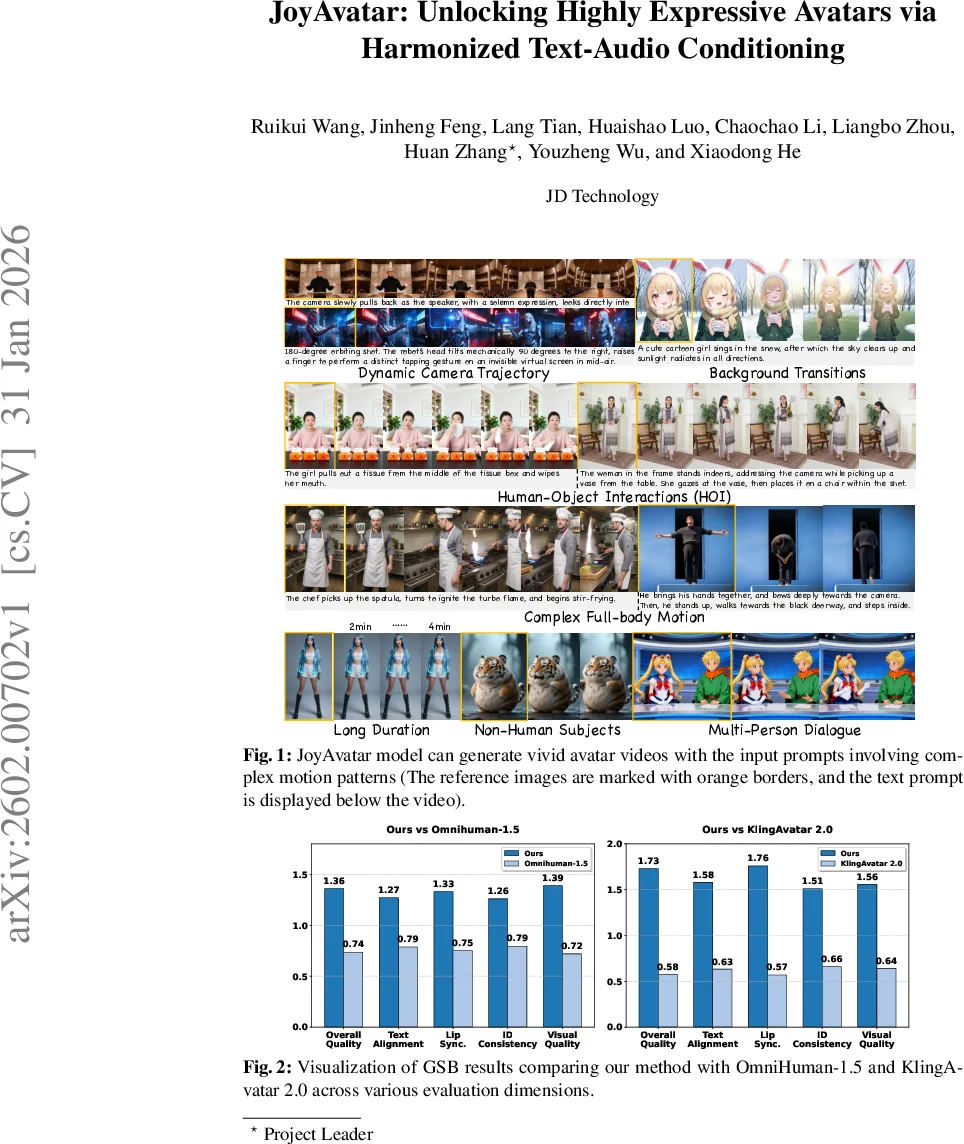
모델 아키텍처는 3D VAE와 FramePack을 이용해 장시간 시퀀스를 압축·연결하고, DiT 기반 비디오 디퓨전 모델에 오디오 교차‑어텐션을 삽입한다. 사전학습 단계에서는 기본적인 오디오‑구동 아바타 기능을 습득하고, 이후 트윈‑티처 DMD와 동적 CFG를 적용해 텍스트 정렬 능력을 크게 향상시킨다. 실험에서는 GSB(Generalized Subjective Benchmark) 평가에서 Omnihuman‑1.5와 KlingAvatar 2.0을 크게 앞서며, 텍스트 정렬, 립싱크, 아이덴티티 일관성, 시각적 품질 모두에서 우수한 점수를 기록한다. 또한 다인물 대화, 비인간 캐릭터 역할극 등 복합 시나리오에서도 안정적인 결과를 보여, 실제 영화·게임 제작 파이프라인에 바로 적용 가능한 수준이다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기