초저비트율을 위한 생성형 오디오 압축: 0.275kbps의 새로운 패러다임
초록
본 논문은 전통적인 파형 복원 중심의 코덱을 넘어, 송신 측에서 의미론적 토큰을 추출하고 수신 측에서 대규모 생성 모델을 활용해 32kHz 일반 오디오를 0.275 kbps(최대 0.175 kbps)로 복원하는 ‘Generative Audio Compression(GAC)’을 제안한다. 정보 용량 법칙(IC‑1)과 AI Flow 이론을 기반으로 ‘More Computation, Less Bandwidth’ 원칙을 실증하며, 1.8 B 파라미터 모델이 기존 신경 코덱 대비 3000배 이상의 압축률에서도 청각적·의미적 품질을 크게 향상시킴을 실험적으로 입증한다.
상세 분석
본 연구는 초저비트율 오디오 전송이라는 실용적 문제를 ‘정보 전송량을 최소화하고 계산량을 최대화한다’는 정보이론적 관점에서 재정의한다. 저자들은 먼저 An et al.이 제시한 정보 용량 법칙(IC‑1, η N = D(H‑L))을 오디오 도메인에 적용해, 학습 손실 L을 전송 비트율 R과 동등시켜 H = R + η N D라는 기본 식을 도출한다. 이 식은 모델 파라미터(N)와 데이터 규모(D)를 늘릴수록 전송 비트율 R을 이론적으로 0에 가깝게 만들 수 있음을 보여준다.
구현 측면에서 GAC는 두 단계로 구성된다. 1단계는 입력 오디오 X를 의미론적 토큰 Z로 압축하는 인코더이며, 이는 변분 정보병목(Information Bottleneck) 원리를 적용해 I(Z;Y) 최대화와 I(Z;X) 최소화를 동시에 최적화한다. 여기서 Y는 텍스트 설명이며, 대규모 사전학습 언어 모델을 활용해 Z가 음성·음악의 의미적 핵심을 담도록 지도한다. 2단계는 Z를 조건으로 고품질 오디오 ˆX를 생성하는 디코더이며, 저자는 흐름 기반 생성 모델(정규화 흐름, Rectified Flow Matching)을 사용해 대규모 파라미터(N)와 고 η를 통해 손실된 세부 정보를 복원한다.
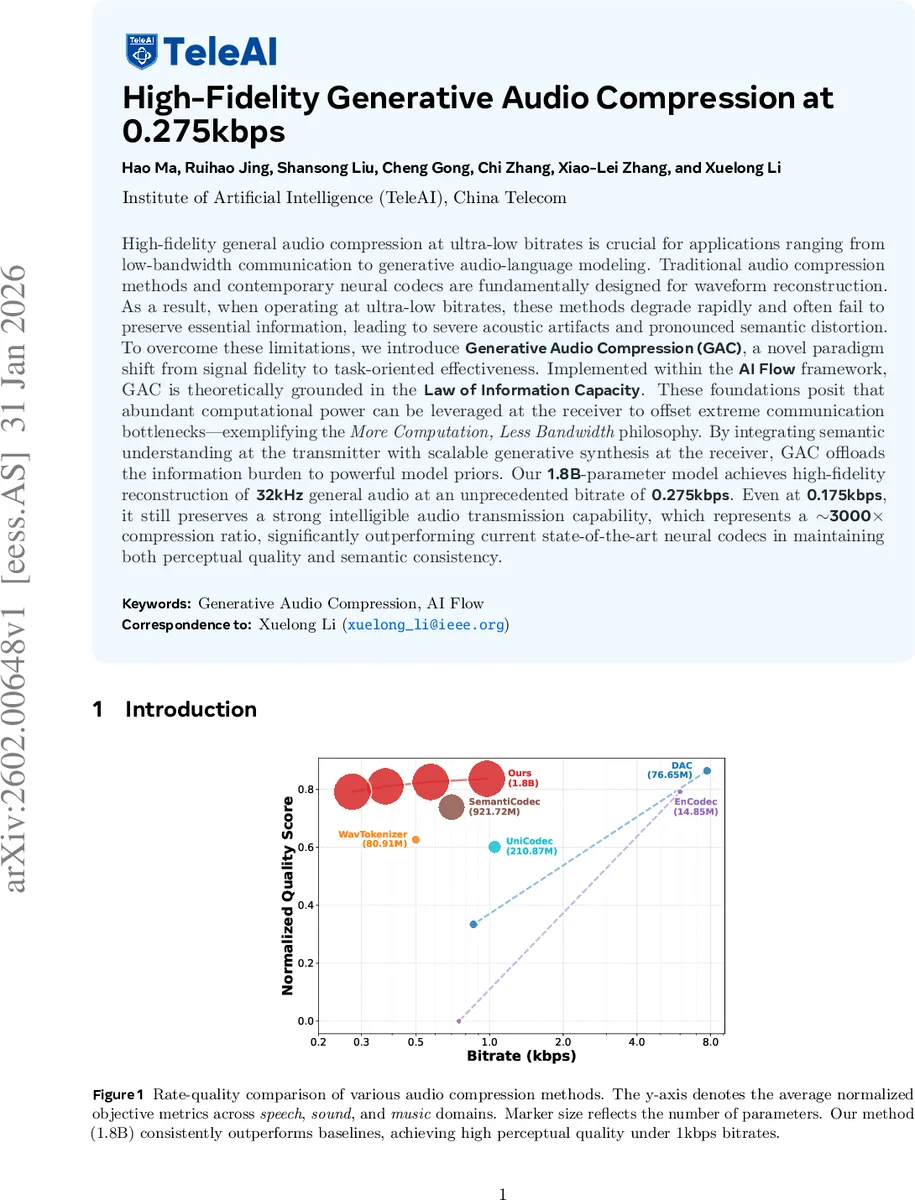
실험에서는 32 kHz 샘플링, 0.275 kbps(최저 0.175 kbps)에서 1.8 B 파라미터 모델이 기존 EnCodec, UniCodec, SemantiCodec 등과 비교해 FAD, KL, MOS, SIM, CER 등 다중 지표에서 일관되게 우수함을 보인다. 특히 음성 영역에서 스피커 동일성(SIM)과 인식 오류(CER)에서 경쟁 모델을 크게 앞서며, 음악·일반 사운드에서도 FAD와 KL이 현저히 낮아 음향적 왜곡이 거의 없음을 확인한다. 주관적 MUSHRA 테스트에서도 높은 평점을 받아 인간 청취자 수준의 품질을 입증한다.
한계점으로는 1.8 B 파라미터라는 거대한 모델 크기가 실시간 스트리밍이나 모바일 디바이스에 직접 적용하기 어려울 수 있다. 또한 의미론적 토큰 생성에 텍스트 라벨이 필요하므로 라벨이 없는 순수 오디오 데이터에 대한 일반화가 제한될 가능성이 있다. 향후 연구에서는 모델 경량화, 라벨 프리 의미 추출, 그리고 다양한 언어·문화권에 대한 적응성을 탐구할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기