시각 압축으로 다중 에이전트 토론 효율 극대화
초록
DebateOCR는 텍스트 토론 기록을 이미지로 변환하고 전용 비전 인코더로 압축해, 다중 에이전트 토론에서 토큰 사용량을 92% 이상 감소시키면서도 정확도를 유지한다. 다수 에이전트의 다양성을 활용해 압축 손실을 보완한다는 이론적 근거를 제시한다.
상세 분석
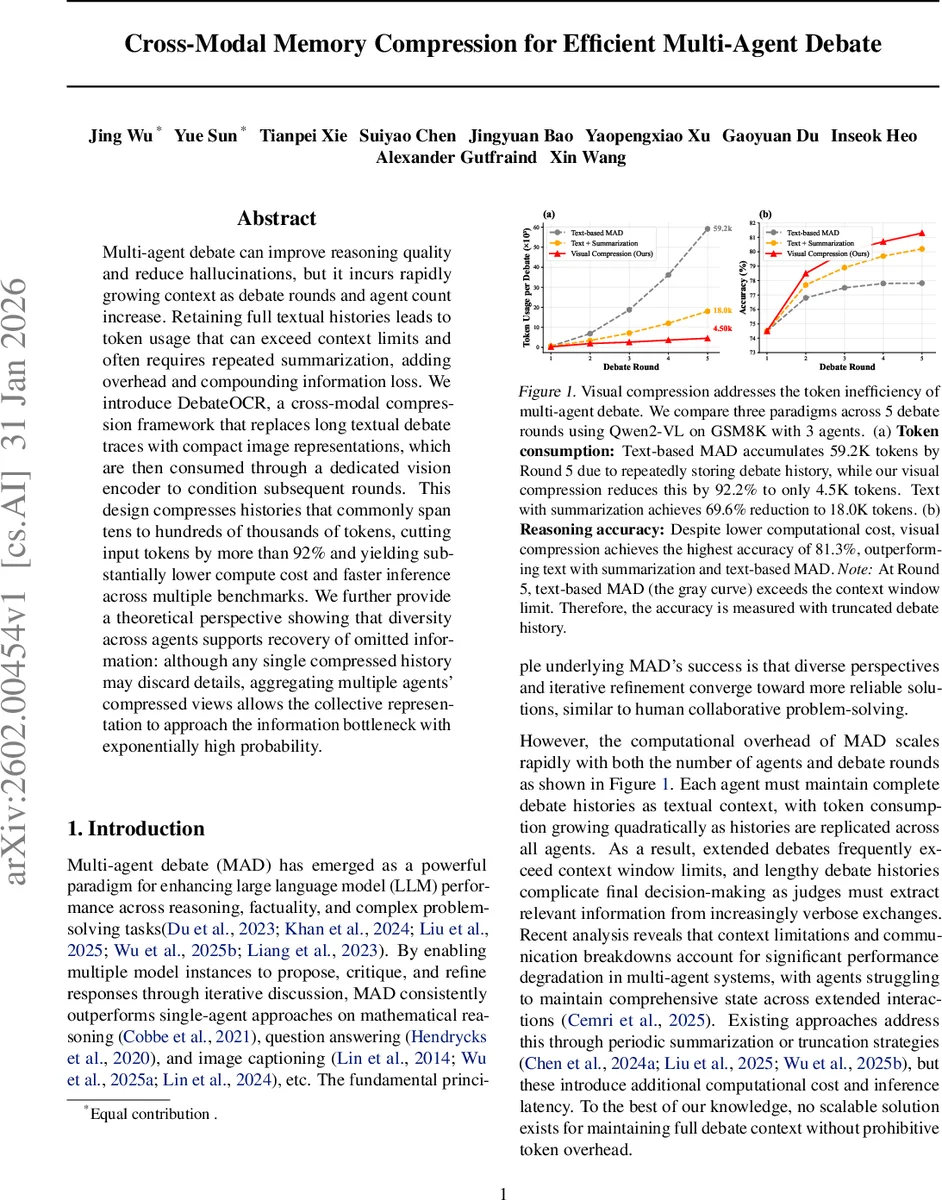
본 논문은 다중 에이전트 토론(MAD)에서 발생하는 토큰 폭증 문제를 근본적으로 해결하고자, 텍스트 기록을 시각적 이미지로 변환한 뒤 경량 비전 인코더와 어댑터 네트워크를 통해 고정된 수의 비전 토큰으로 압축하는 DebateOCR 프레임워크를 제안한다. 기존 텍스트 기반 MAD는 토론 라운드와 에이전트 수가 증가할수록 O(K²R²L)의 복합 토큰 비용을 초래해 컨텍스트 윈도우를 초과하고, 요약 과정에서 정보 손실과 추가 연산 비용이 발생한다. DebateOCR는 SAM과 CLIP을 결합한 피처 추출 파이프라인을 사용해 1024×1024 해상도의 토론 기록 이미지를 256개의 비전 토큰으로 요약한다. 어댑터는 이 피처를 목표 멀티모달 LLM의 토큰 임베딩 공간에 정렬하도록 학습되며, 학습 단계에서만 파라미터를 업데이트하고 사전 학습된 비전 모델은 고정한다는 점이 효율성을 높인다.
이론적 분석에서는 정보 병목(Information Bottleneck) 관점을 도입해, 압축된 히스토리가 개별 에이전트마다 일부 정보를 잃더라도, 에이전트 간 다양성이 서로 보완적인 정보를 보존한다는 ‘다양성 기반 복구’ 메커니즘을 증명한다. 구체적으로, 서로 다른 에이전트가 동일한 토론을 서로 다른 시각적 관점으로 압축하면, 각 이미지가 포함하는 부분 집합이 독립적인 확률 변수처럼 작용해, 다수결 혹은 가중 평균을 통해 원본 텍스트의 핵심 정보를 고확률로 재구성할 수 있다. 이는 압축 비율이 높아도 시스템 수준의 정확도가 크게 저하되지 않는 이유를 설명한다.
실험에서는 GSM8K, MATH, GPQA 등 3가지 베엔치마크와 Qwen2‑VL, Llama‑3.2‑Vision, InternVL2, Pixtral 등 4가지 비전‑언어 모델을 대상으로 평가하였다. 토큰 사용량은 평균 92% 이상 감소했으며, 특히 5라운드 토론에서 텍스트 기반 MAD가 컨텍스트 한계에 도달해 성능이 급락하는 반면, DebateOCR는 81.3%의 최고 정확도를 기록했다. 요약 기반 대비 토큰 절감률은 69.6%에서 92.2%로 크게 향상되었으며, 추론 시간도 30% 이상 단축되었다.
전체적으로 이 연구는 (1) 텍스트‑이미지 변환을 통한 초고밀도 압축, (2) 비전 인코더와 어댑터만으로 기존 LLM 구조를 그대로 활용, (3) 다중 에이전트의 다양성을 정보 복구 메커니즘으로 활용한다는 세 가지 혁신 포인트를 제공한다. 향후 연구에서는 압축 이미지의 해상도와 토큰 수 사이의 최적 트레이드오프, 그리고 비전‑언어 모델의 스케일업에 따른 압축 효율성을 탐색할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기