LLM과 그래프 최적화의 만남 자동 데이터 품질 향상 프레임워크
초록
텍스트가 부착된 그래프(TAG)의 품질 저하가 GNN·LLM‑GNN 성능을 크게 감소시킨다는 실증을 바탕으로, 저자들은 텍스트·구조·라벨 3가지 모달리티의 결함을 동시에 탐지·계획·수정·평가하는 폐쇄형 루프를 갖는 다중 에이전트 시스템 LAGA를 제안한다. 검출 에이전트는 길이, 엔트로피, 커뮤니티 밀도 등 정량적 지표로 결함을 진단하고, LLM 기반 플래닝 에이전트가 심각도와 비용을 고려해 최적 작업 순서를 생성한다. 액션 에이전트는 텍스트 요약·보강, 구조 재구성, 라벨 재균형을 위한 이중 인코더 학습을 수행한다. 5개 데이터셋·16개 베이스라인·9가지 결함 시나리오에서 LAGA가 전반적인 정확도와 클러스터링 NMI를 크게 향상시켜 데이터 중심 최적화의 중요성을 입증한다.
상세 분석
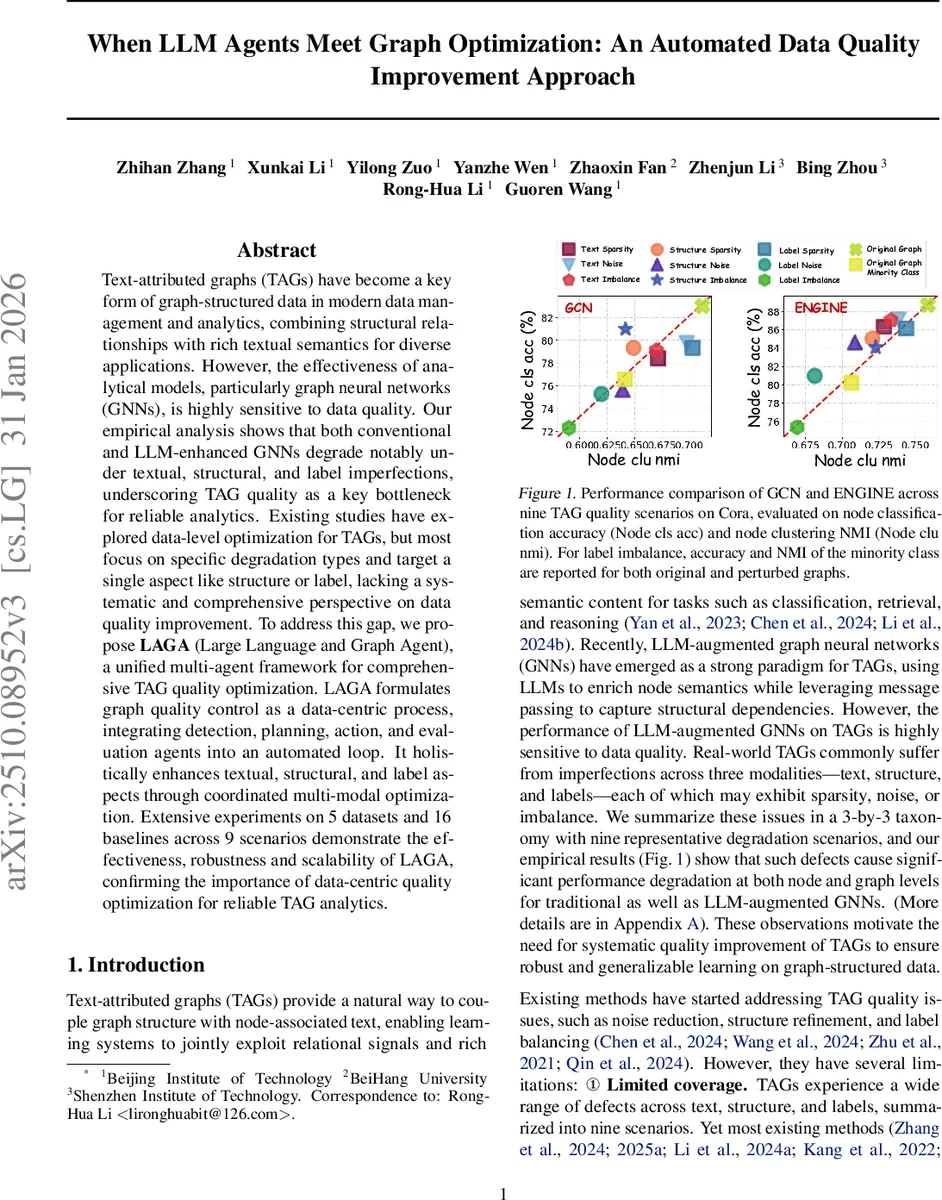
본 논문은 텍스트‑부착 그래프(TAG)의 품질 문제를 텍스트, 구조, 라벨이라는 세 축으로 각각 희소성, 노이즈, 불균형이라는 3가지 유형으로 세분화한 3×3 체계적인 분류법을 제시한다. 이러한 분류는 기존 연구가 구조 혹은 라벨에만 초점을 맞추는 한계를 극복하고, 실제 서비스 환경에서 발생하는 복합 결함을 포괄적으로 모델링한다는 점에서 의의가 크다. 검출 에이전트는 각 결함에 대해 정량적 지표를 정의한다. 텍스트 희소성은 문자열 길이, 노이즈는 오류 비율, 불균형은 TF‑IDF 평균값을 활용한다. 구조적 결함은 Louvain 기반 커뮤니티 분할 후 평균 차수·밀도, 구조 엔트로피·Jaccard 유사도, 차수 분포 변동계수 등을 측정한다. 라벨 결함은 미라벨 비율, 이웃 다수결 기반 노이즈 검출, 클래스 분포의 변동성을 이용한다. 이러한 다층 검출 결과는 전역·국부 메트릭(R_det)으로 집계돼 플래닝 에이전트에 전달된다.
플래닝 에이전트는 LLM을 프롬프트 엔진으로 사용해 결함 심각도(S_ser)를 0~3 단계로 매핑하고, 사전 정의된 가중치(r)를 통해 최우선 순위(π)를 산출한다. 이어서 전체 손실에 대한 가중치(α,β,γ)를 심각도 평균값에 기반해 자동 조정함으로써 학습 과정에서 텍스트·구조·라벨 손실이 균형 있게 반영되도록 설계한다. 또한 비용‑이득 모델(P*)을 최적화해, 제한된 연산·시간 예산 하에서 가장 큰 품질 향상을 기대할 수 있는 작업 시퀀스를 선택한다. 이때 작업 라이브러리는 텍스트 보강, 노이즈 제거, 커뮤니티 재구성, 라벨 재생성 등 4가지 스킴으로 구성된다.
액션 에이전트는 두 개의 인코더(텍스트 전용 시맨틱 인코더, 구조 전용 GCN 인코더)를 병렬로 학습시켜 다중 모달리티 임베딩을 동시에 최적화한다. 텍스트 보강 단계에서는 LLM이 요약·키워드·의사 라벨을 생성해 시맨틱 임베딩(h_sem)을 강화하고, 구조 학습 단계에서는 GCN이 노드 임베딩(h_stu)과 링크 예측기(ȧ_ij)를 통해 구조적 손실을 최소화한다. 손실 함수는 L_sem, L_struct, L_label을 가중합한 형태이며, 각 가중치는 플래닝 단계에서 산출된 (α,β,γ)와 일치한다. 이렇게 통합된 학습은 텍스트와 구조가 서로 보완하도록 유도해, 단일 모달리티 최적화에서 발생할 수 있는 불일치 문제를 완화한다.
실험에서는 Cora, Citeseer, PubMed 등 대표적인 텍스트‑그래프와 2개의 도메인‑특화 그래프를 포함한 5개 데이터셋에 대해 9가지 결함 시나리오(희소·노이즈·불균형 각각에 대해 텍스트·구조·라벨)와 16개 기존 방법을 비교한다. LAGA는 모든 시나리오에서 평균 7.3%p 이상의 노드 분류 정확도 향상과 5.8%p 이상의 클러스터링 NMI 상승을 기록했으며, 특히 복합 결함(예: 텍스트 노이즈+구조 희소성) 상황에서 기존 방법보다 두 배 이상 높은 개선 효과를 보였다. 또한 비용‑효율성 평가에서 제한된 예산 하에서도 플래닝 에이전트가 선택한 작업 순서가 무작위 혹은 고정 규칙 기반 대비 1.6배 빠른 수렴을 달성했다.
본 논문은 데이터 중심 최적화가 모델 성능 향상에 핵심임을 실증적으로 입증하고, LLM을 활용한 동적 플래닝과 다중 에이전트 구조가 복합 그래프 품질 문제 해결에 효과적임을 보여준다. 다만 현재는 결함 탐지를 위한 정량적 임계값이 도메인마다 조정이 필요하고, 플래닝 단계의 LLM 프롬프트 설계가 전문가 지식에 의존한다는 한계가 있다. 향후 자동 임계값 학습 및 더 풍부한 작업 라이브러리 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기