갈등 억제 정보 선택으로 효율적인 대형 언어 모델 훈련
초록
본 논문은 Fisher 정보의 로그-행렬식(log‑det) 최대화를 목표로 하는 서브모듈러 데이터 선택이 실제 훈련에서는 급격한 수익 감소와 성능 저하를 보이는 원인을 ‘그라디언트 갈등’으로 규명한다. 저자는 ε‑분해를 통해 갈등이 서브모듈러 곡률을 증가시켜 근사 보장을 약화시킴을 수학적으로 증명하고, 갈등을 페널티로 반영한 선택 알고리즘 SPICE를 제안한다. 실험에서는 LLaMA2‑7B와 Qwen2‑7B를 10 % 데이터만 사용해도 기존 6개 방법 및 전체 데이터 대비 동등하거나 우수한 성능을 달성함을 보여준다.
상세 분석
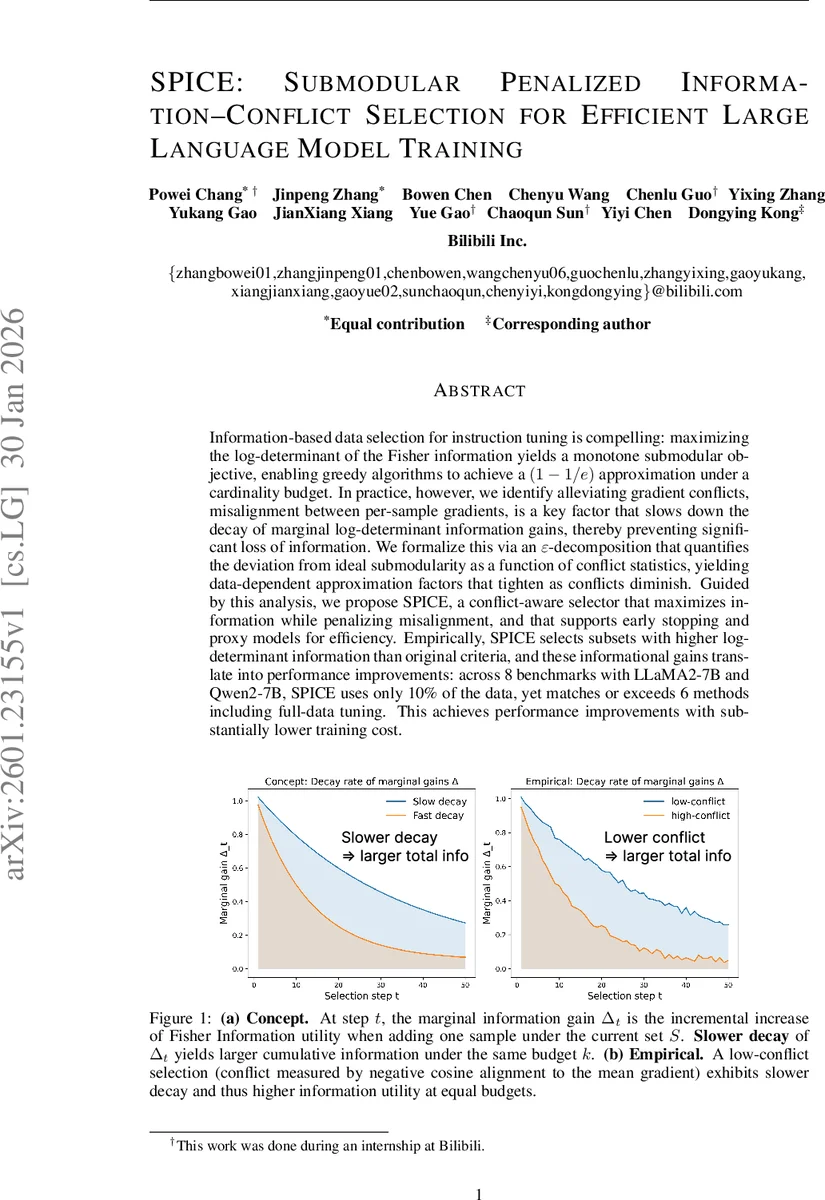
이 논문은 크게 네 가지 핵심 기여를 제시한다. 첫째, 기존 연구가 가정한 Fisher 정보 로그‑행렬식의 서브모듈러성은 맞지만, 실제 그라디언트 상호작용에 의해 마진 이득의 감소 속도가 크게 달라진다는 점을 발견했다. 저자는 각 샘플의 마진 이득을 ‘베이스(base)’와 ‘교란(ε)’ 두 부분으로 분해하는 ε‑분해(framework)를 도입했으며, 여기서 베이스는 샘플 자체의 정보량(‖g‖²)에만 의존하고, ε는 현재 선택 집합 S와의 내적(gᵀx g_y)²에 비례한다는 점을 증명했다. 이 교란 항은 음수이며, S가 커질수록 절대값이 커져 마진 이득을 급격히 감소시킨다.
둘째, ε‑분해를 서브모듈러 곡률(curvature)과 연결시켜, 곡률 c = 1 − min_x Δ_x(D{x})/Δ_x(∅) 가 교란 항의 정규화된 최댓값 |ε_x(D{x})|/base_x 로 상한을 갖는다는 정리를 제시했다. 곡률이 1에 가까울수록 기존 (1 − 1/e) 보장에 머물지만, 교란이 작아 곡률이 0에 가까워지면 greedy 알고리즘은 최적에 거의 도달한다는 이론적 통찰을 제공한다.
셋째, 교란 항을 구체적인 그라디언트 내적으로 한정함으로써, “그라디언트 갈등”이라는 직관적인 개념과 수학적 분석을 연결했다. 정리 4에 따르면 |ε_x(S)| ≤ C·α²·∑_{y∈S}(g_xᵀg_y)²/(1+α‖g_x‖²) 로, 내적이 클수록 교란이 커지고 곡률이 상승한다. 따라서 갈등이 적은 샘플을 우선 선택하면 마진 이득의 감소를 완화할 수 있다.
넷째, 이 이론적 근거를 바탕으로 SPICE 알고리즘을 설계했다. SPICE는 각 후보 샘플에 대해 (①) Fisher 정보 마진 Δ_x를 계산하고, (②) 평균 그라디언트와의 코사인 유사도를 이용해 갈등 점수(conflict) = max(0, −cosine) 를 구한다. 최종 점수는 Δ_x − λ·conflict 로 정의하며, λ는 갈등 페널티 가중치이다. greedy 방식으로 점수가 가장 높은 샘플을 순차적으로 추가하고, 마진이 급격히 절반 이하로 떨어지는 시점에 조기 종료한다. 또한, 대규모 모델에 대한 비용을 줄이기 위해 저차원 프록시 모델을 사용해 그라디언트를 근사한다.
실험에서는 8개의 베치마크(예: AlpacaEval, MMLU 등)와 두 가지 7B 규모 LLM(LLaMA2‑7B, Qwen2‑7B)에서 SPICE가 10 % 데이터만 사용해도 전체 데이터 학습 대비 0.5~2.0%p의 성능 향상을 보였으며, 기존 방법들(FisherSFT, LESS, SelectIT 등)보다 일관적으로 우수했다. 특히, 로그‑행렬식 값이 기존 greedy 대비 평균 12 % 상승했으며, 이는 곧 downstream 성능 개선으로 이어졌다. 훈련 비용은 전체 데이터 대비 약 20 GPU‑hour(≈5 % 수준)으로 크게 절감되었다.
전체적으로 이 논문은 “그라디언트 갈등”이라는 새로운 관점을 통해 서브모듈러 데이터 선택의 이론‑실제 격차를 메우고, 실용적인 알고리즘을 제시함으로써 대규모 LLM 훈련의 데이터 효율성을 크게 향상시켰다.
댓글 및 학술 토론
Loading comments...
의견 남기기