시점 일반화 로봇 조작을 위한 기하학 기반 3D 시각 표현 학습
초록
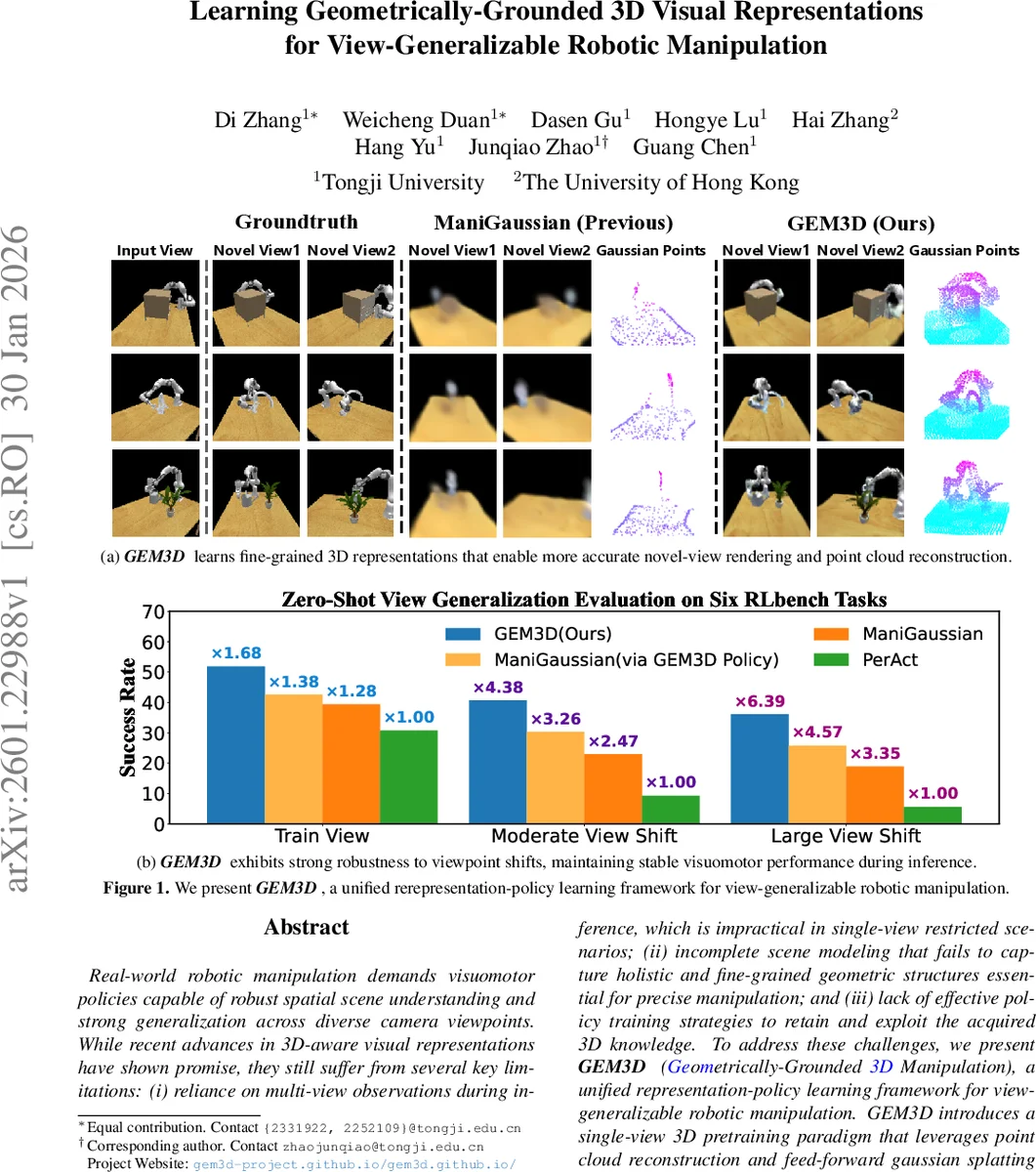
GEM3D는 단일 시점 RGB‑D 입력만으로 전체 장면의 정밀한 3D 구조와 텍스처를 복원하고, 이를 다단계 디스틸레이션을 통해 로봇 조작 정책에 전달한다. 12개의 RLBench 과제에서 기존 최첨단 대비 평균 성공률을 12.7% 끌어올렸으며, 시점 변동이 큰 상황에서도 성공률 감소폭을 현저히 억제한다.
상세 분석
본 논문은 로봇 조작에서 시점 변화에 강인한 3D 인식을 구현하기 위해 두 가지 핵심 문제를 해결한다. 첫째, 기존 3D‑aware 방법들은 다중 카메라 입력에 의존하거나, 복원된 장면이 거칠어 정밀 조작에 부적합했다. 둘째, 3D 사전학습된 인코더를 그대로 파인튜닝하면 정책 학습 과정에서 기하학적 지식이 소실된다. GEM3D는 이러한 한계를 극복하기 위해 (1) 단일 시점 RGB‑D를 입력으로 하는 3D 사전학습 파이프라인을 설계한다. 여기서는 깊이 맵을 역투영해 포인트 클라우드를 만들고, 사전학습된 DinoV2로 추출한 2D 피처를 포인트에 투사한다. 이후 voxel‑grid와 3D U‑Net을 이용해 Dense Volumetric Feature를 생성한다. (2) 이 volumetric feature를 기반으로 coarse‑to‑fine Snowflake 방식의 포인트 클라우드 복원을 수행한다. 학습 가능한 voxel query를 통해 저해상도와 고해상도 cross‑attention을 적용해 seed point를 얻고, SPD 블록으로 점진적 세분화를 진행한다. Chamfer loss를 다중 시점 GT 포인트와 비교해 전체 장면을 정밀히 재구성한다. (3) 재구성된 포인트를 Gaussian splatting의 중심으로 활용해 feed‑forward 3D Gaussian Splatting을 수행한다. Gaussian 파라미터를 ResNetFC에 입력해 색, 불투명도, 회전·스케일 등을 예측하고, 차별화 가능한 렌더러로 다중 시점 이미지를 합성한다. 여기서는 focal loss를 사용해 시각적으로 어려운 영역을 강조한다. 사전학습 단계는 단일 시점 입력만으로도 전체 장면의 기하학·텍스처를 고해상도로 복원하도록 설계돼, 실제 로봇 환경에서 카메라 시점이 변해도 일관된 3D 표현을 제공한다. 정책 학습 단계에서는 사전학습된 3D 피처 추출기를 고정하고, 별도의 정책 인코더를 두어 현재 시점의 RGB‑D를 토큰화한다. 정책 인코더의 토큰과 사전학습된 volumetric feature를 patch‑wise로 매핑해 cosine similarity 기반 디스틸레이션 손실을 적용한다. 또한, 잠재 공간에서의 시간적 일관성을 유지하기 위해 implicit dynamics model을 도입해 다음 latent state를 예측하고, 이를 다단계 디스틸레이션에 포함한다. 최종 손실은 행동 복제 손실과 디스틸레이션 손실의 가중합이다. 실험에서는 12개의 RLBench 과제에서 평균 성공률이 71.3%에서 84.0%로 상승했으며, 시점 변동이 moderate(±30°)와 large(±60°)일 때 성공률 감소폭이 각각 22.0%·29.7%에 그쳐, 기존 ManiGaussian 대비 19.6%·21.8% 적은 감소를 보였다. Ablation study는 각 모듈(볼류메트릭 피처, Snowflake 복원, Gaussian splatting, 다단계 디스틸레이션)의 기여를 정량화했으며, 특히 다단계 디스틸레이션이 정책의 3D 지식 보존에 핵심임을 확인했다. 전체적으로 GEM3D는 단일 시점 입력만으로도 정밀한 3D 재구성을 가능하게 하고, 이를 효과적으로 정책에 전이함으로써 시점 일반화 로봇 조작에 새로운 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기