퍼플렉시티가 모델 선택을 속일 수 있다
초록
퍼플렉시티는 모델의 자신감과 정확도가 일치하지 않을 때 잘못된 모델을 선택하게 만들 수 있으며, 특히 컴팩트한 디코더‑전용 트랜스포머에서 이 현상이 이론적으로 증명된다.
상세 분석
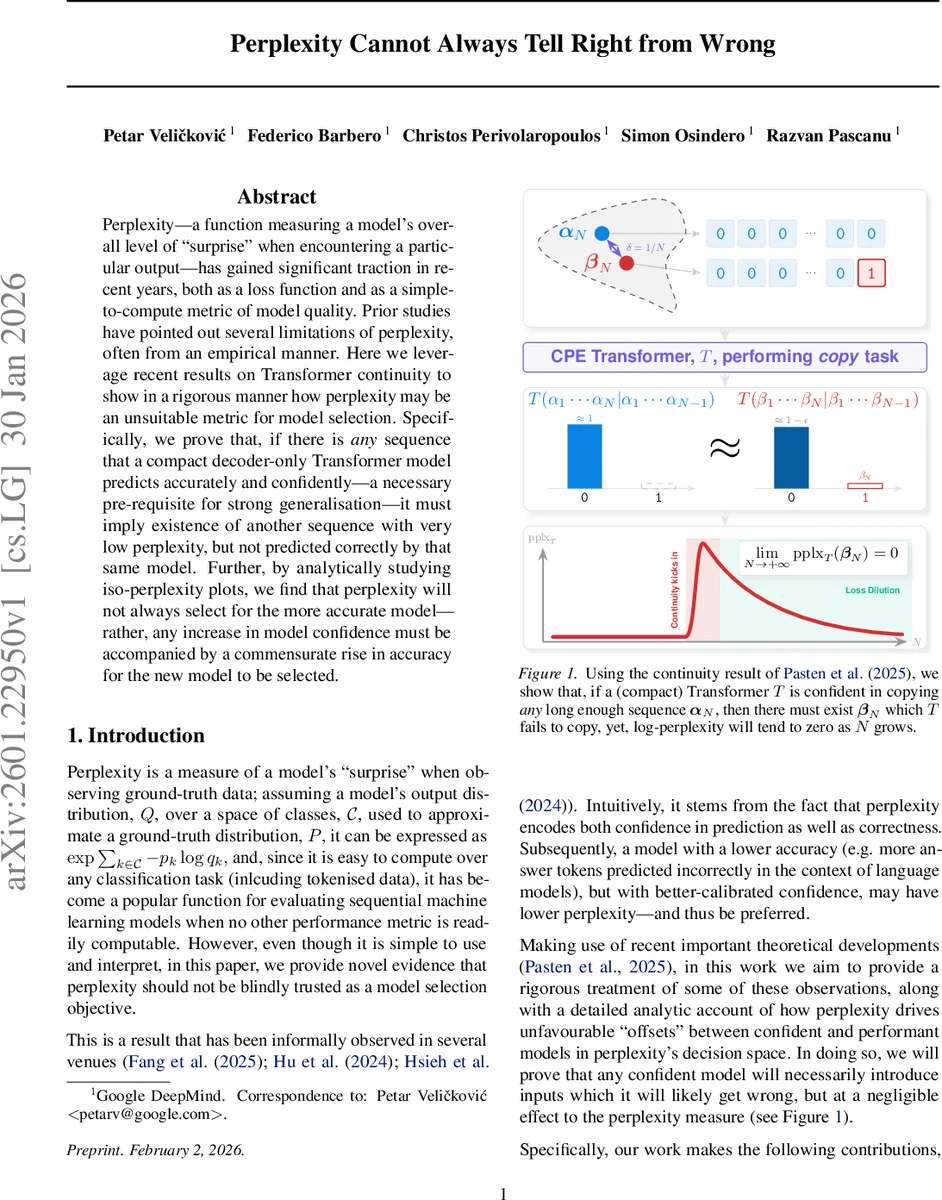
본 논문은 퍼플렉시티가 모델 선택 지표로서 갖는 근본적인 한계를 트랜스포머 연속성 이론을 활용해 엄밀히 증명한다. 핵심 가정은 ‘컴팩트한 위치 임베딩(CPE)을 가진 디코더‑전용 트랜스포머’이며, 이러한 모델은 Pasten et al. (2025)의 연속성 결과에 따라 무한히 긴 시퀀스 집합을 하나씩만 정확히 복제할 수 있다. 저자들은 비트스트링 복사 작업을 정형화된 실험 환경으로 채택해, 모델이 어떤 무한 시퀀스 α를 높은 확신(1‑γ)으로 정확히 복제한다면, 동일한 모델이 거의 동일한 로그‑퍼플렉시티를 보이는 다른 시퀀스 β를 복제하지 못한다는 명제(Prop. 3.2)를 도출한다. 특히 γ=0, 즉 완전 확신일 경우 β의 퍼플렉시티는 N→∞ 일 때 0에 수렴한다(Cor. 3.3). 이는 ‘확신이 높을수록 잘못된 입력에 대한 퍼플렉시티 손실이 사라진다’는 직관과 일치한다.
또한, 확률적 샘플링(temperature > 0) 상황을 고려해 γ와 온도를 결합한 γ′로 변환함으로써, 온도 변화가 실제로는 확신 수준을 조정하는 효과와 동일함을 보인다(Remark 3.4). Boole’s inequality를 이용해 N·γ가 작을 때 오류 발생 확률이 제한됨을 보이고, 연속성 결과와 결합해 β에 대한 오류 확률이 여전히 낮지만 퍼플렉시티 차이는 사라진다는 점을 강조한다(Prop. 3.6).
학습 역학 측면에서는 α에 대한 손실이 0에 수렴하면 β에 대한 손실도 동시에 0에 접근하게 되며, 이때 β에 대한 그래디언트는 사라진다(Cor. 3.7). 즉, 모델이 α에 과도하게 최적화될수록 β와 같은 오류 샘플에 대한 학습 신호가 소멸해, 데이터셋에 존재하는 어려운 사례를 학습하기 어려워진다.
실험에서는 자체 학습한 소형 CPE 트랜스포머와 Gemma 3 4B 대형 모델을 사용해 α=0…0, β=0…01 형태의 시퀀스를 평가하였다. 두 모델 모두 N이 증가함에 따라 α와 β의 로그‑퍼플렉시티 차이가 급격히 감소했으며, β에 대한 복제 성공률은 급격히 떨어졌다. 대형 모델에서는 토큰 다양성으로 인한 노이즈가 관찰됐지만, 전반적인 경향은 이론과 일치했다.
마지막으로 iso‑퍼플렉시티 곡선을 confidence‑accuracy 평면에 그려, ‘과도한 확신이 정확도 향상보다 큰 경우’ 모델이 퍼플렉시티 기준으로 선택되지 못하는 불리한 영역을 시각화했다. 이 영역은 특히 데이터 분포 변화가 있을 때 빈번히 나타났으며, 모델 선택 시 퍼플렉시티만을 의존하면 실제 성능이 더 좋은 모델을 놓칠 위험이 있음을 강조한다.
요약하면, 퍼플렉시티는 모델의 자신감과 정확도가 비례하지 않을 때, 특히 트랜스포머의 연속성 특성에 의해 발생하는 ‘잘못된 고신뢰 입력’에 대해 무감각해진다. 따라서 모델 선택 시 퍼플렉시티 외에 정확도, 캘리브레이션, 분포 적합성 등을 복합적으로 고려해야 한다는 강력한 이론적·실험적 근거를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기