엔트로피 코딩 기반 초극소형 모델 압축
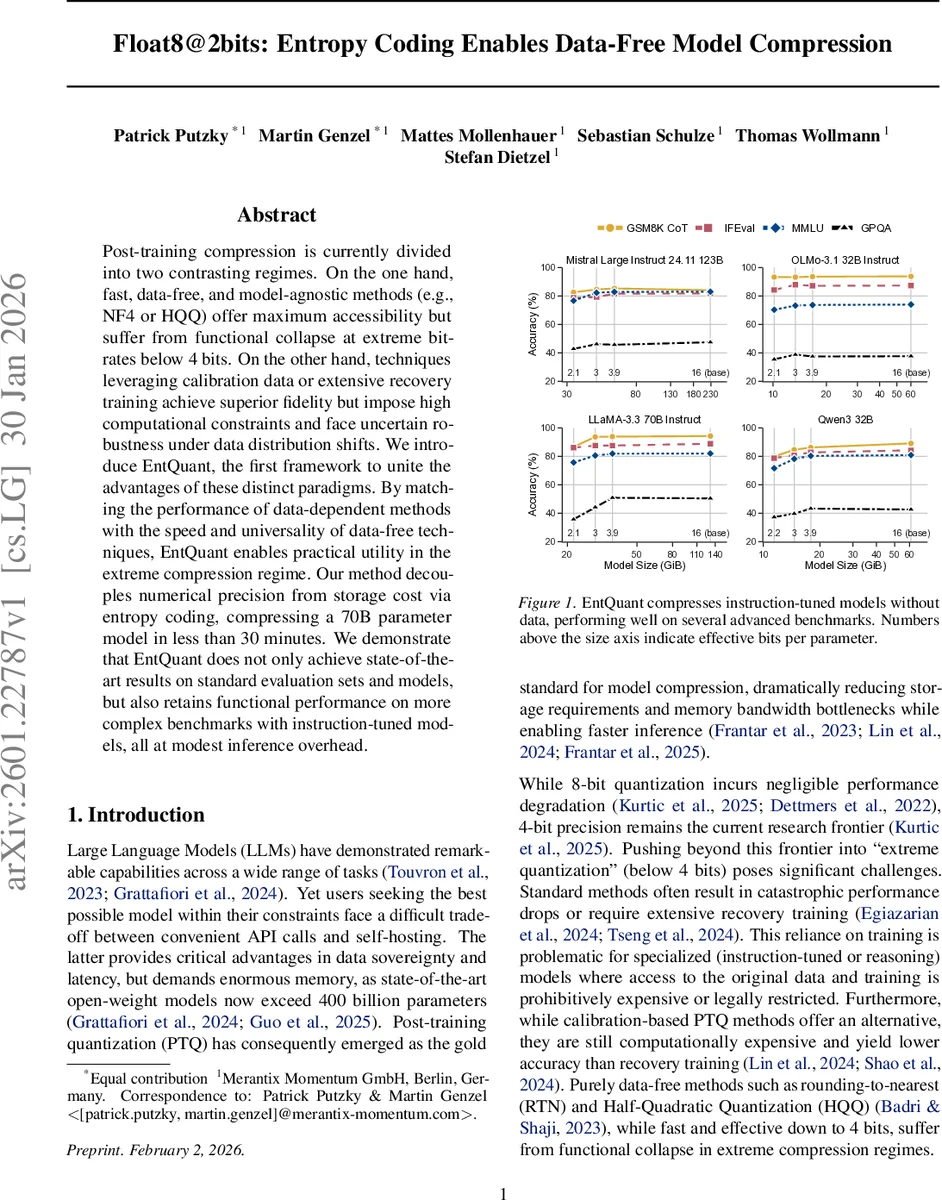
초록
EntQuant는 8비트 혹은 16비트와 같은 고정 정밀도 포맷을 유지하면서 가중치의 엔트로피를 최소화하고, ANS 기반 손실 없는 엔트로피 코딩으로 저장 용량을 2비트 수준까지 압축한다. 데이터와 캘리브레이션이 필요 없으며, 70B 모델을 30분 이내에 압축하고, 추론 시 추가적인 디코딩 오버헤드만 발생한다.
상세 분석
본 논문은 기존 포스트‑트레이닝 양자화(Post‑Training Quantization, PTQ) 방법이 비트폭과 압축률을 강하게 결합시켜 극단적인 2‑4비트 영역에서 성능 붕괴를 일으키는 문제점을 정확히 짚어낸다. 이를 해결하기 위해 저자들은 “압축률 ↔ 정밀도”의 결합을 끊고, 고정 비트폭(예: Float8, Int8) 내에서 가중치 분포의 엔트로피를 최소화하는 새로운 프레임워크 EntQuant를 제안한다. 핵심 아이디어는 두 단계로 구성된다. 첫 번째 단계에서는 각 채널별 스케일 파라미터를 최적화해 양자화된 가중치 행렬 (W_q)의 엔트로피를 감소시킨다. 여기서 저자는 엔트로피 자체를 직접 미분할 수 없으므로, (\ell_1)‑노름을 엔트로피의 연속적인 근사치로 사용한다. (\ell_1)‑노름은 값이 자주 등장할수록 절댓값이 작아지는 특성을 갖기 때문에, 최적화 과정에서 빈번히 사용되는 값이 집중되고 희소성이 증가한다. 두 번째 단계에서는 최적화된 (W_q)를 일차원 심볼 스트림으로 평탄화한 뒤, GPU‑가속 ANS(Asymmetric Numeral Systems) 코덱을 이용해 손실 없는 압축을 수행한다. ANS는 산술 코딩과 동일한 압축 효율을 유지하면서 곱셈·비트시프트만으로 구현 가능해 대규모 모델에 적합하다. 압축된 비트스트림과 스케일 파라미터, 그리고 ANS 메타데이터만을 저장하면 되므로, 전체 저장 비용은 주로 가중치 엔트로피에 의해 결정된다.
추론 단계에서는 기존과 달리 가중치를 바로 메모리에 로드하지 않고, VRAM에 압축된 비트스트림을 그대로 두고 필요 시 GPU‑병렬 ANS 디코더로 실시간 복호화한다. 이는 디코딩 연산이 GPU 연산 파이프라인에 자연스럽게 삽입되어, 메모리 대역폭 절감 효과와 동시에 약간의 연산 오버헤드만을 발생시킨다. 실험 결과, 70B 파라미터를 갖는 LLaMA‑2, Mistral, Qwen3 등 다양한 모델에서 2‑3비트 수준의 효과적 비트당 파라미터를 달성하면서, 기존 NF4·HQQ와 같은 데이터‑프리 방법이 4비트 이하에서 보이는 급격한 성능 저하를 회피한다. 특히, instruction‑tuned 모델에 대해 GSM8K, MMLU, GPQA 등 복합 벤치마크에서 데이터‑의존 PTQ(캘리브레이션 기반)와 거의 동등한 정확도를 유지한다.
또한 저자들은 스케일 파라미터를 채널 단위로 제한함으로써 메모리 오버헤드를 최소화하고, L‑BFGS 기반 최적화를 각 레이어별 독립적으로 수행해 전체 압축 시간을 수십 분 수준으로 단축한다. λ‑값과 목표 엔트로피 사이의 로그‑선형 관계를 실험적으로 확인함으로써, 사용자는 모델‑별로 복잡한 튜닝 없이도 직관적인 λ 선택만으로 원하는 압축률을 제어할 수 있다.
결과적으로 EntQuant는 (1) 데이터‑프리, (2) 고정 비트폭 유지, (3) 엔트로피 기반 압축률 조절, (4) 빠른 최적화·압축, (5) 실시간 디코딩을 모두 만족하는 최초의 프레임워크로, 극단적인 비트‑레이트에서도 모델 기능을 보존한다는 중요한 돌파구를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기