분자 언어 모델의 규모와 데이터와 표현 방식에 따른 스케일링 법칙
초록
본 연구는 GPT‑스타일 분자 언어 모델을 300종, 10 000여 실험에 걸쳐 체계적으로 평가하여, 고정된 연산 예산 하에서 모델 크기, 학습 토큰 수, 그리고 분자 문자열 표현(SMILES, SAFE, DeepSMILES, FragSeq, FragLink)이 각각 성능에 미치는 영향을 정량화한다. 전처리 손실과 다운스트림 예측 모두에서 명확한 파워‑법칙 형태의 스케일링이 관찰되었으며, 특히 표현 방식이 최적 토큰‑파라미터 비율과 최종 성능에 큰 변동을 일으킨다는 점을 밝힌다. 또한 기존 연구에서 보고된 생성 태스크의 스케일링 부재는 평가 지표의 한계와 데이터·표현 불일치 때문임을 설명한다.
상세 분석
이 논문은 분자 생성 모델에 대한 스케일링 연구가 아직 불완전하다는 점을 지적하고, 이를 보완하기 위해 5가지 문자열 표현과 8가지 모델 규모(1 M ~ 650 M 파라미터), 4가지 데이터 토큰 규모(100 M ~ 3 B)를 조합한 300개의 독립적인 사전학습 실험을 설계하였다. 핵심은 연산 예산 C를 고정하고, 파라미터 수 P와 학습 토큰 수 D가 C = P·D 관계를 만족하도록 제어함으로써 “compute‑optimal frontier”를 명시적으로 탐색한 점이다.
-
이중 파워‑법칙 모델
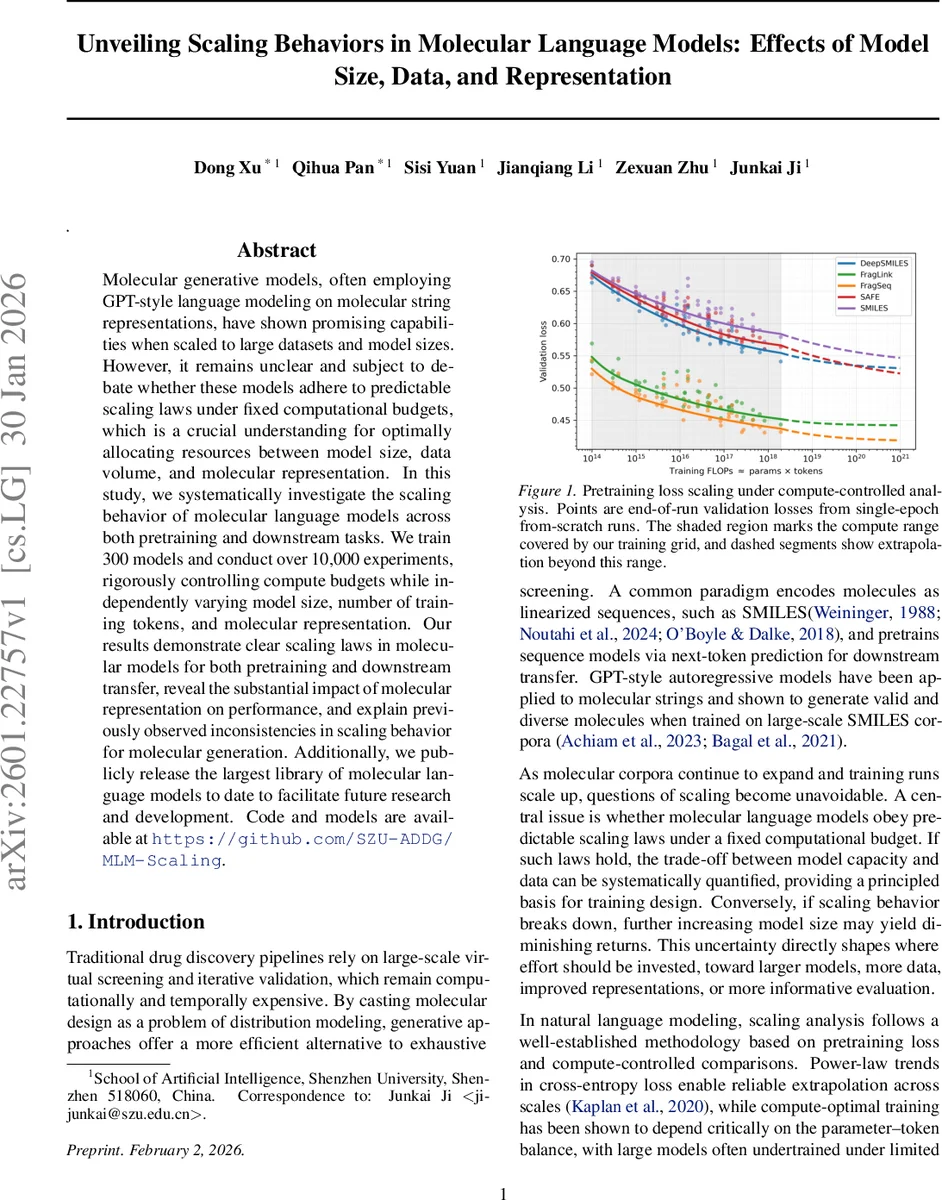
L(P,D) = L∞ + k_P · P^{‑α} + k_D · D^{‑β} 형태를 각 표현별로 피팅했으며, 모든 표현에서 α와 β가 양수임을 확인했다. 이는 모델 규모와 데이터 양이 증가할수록 손실이 꾸준히 감소한다는 전형적인 스케일링 거동을 의미한다. 특히 SMILES와 DeepSMILES는 α가 크고 β가 작아 파라미터 확대에 민감하지만, 데이터 확대 효율은 상대적으로 낮았다. 반면 FragSeq와 FragLink는 β가 크게 나타나 데이터 규모 확대가 손실 감소에 더 큰 기여를 함을 보여준다. -
Compute‑optimal 파라미터‑토큰 비율 (ρ_opt)
고정된 FLOP 예산 하에서 손실을 최소화하는 P_opt과 D_opt을 미분으로 도출하고, ρ_opt = D_opt/P_opt ≈ a·C^{s} 형태의 파워‑법칙으로 요약했다. 실험 결과 s 값이 표현마다 크게 달라, 예를 들어 SMILES는 s≈0.45(데이터 비중이 높음), SAFE는 s≈0.30(파라미터 비중이 높음)으로 나타났다. 이는 동일한 연산량이라도 어떤 표현을 선택하느냐에 따라 최적 학습 전략이 달라진다는 실질적인 설계 지침을 제공한다. -
다운스트림 전이 성능
사전학습된 체크포인트를 LoRA 기반 경량 적응으로 9가지 화학‑생물학적 베치에 적용했으며, ROC‑AUC(분류)와 RMSE(회귀) 모두 L(P,D)와 높은 상관관계를 보였다. 특히 43 M 파라미터 모델이 300 M 토큰 데이터와 결합될 때 가장 높은 효율을 기록했으며, 이는 compute‑optimal 곡선과 일치한다. -
생성 태스크 스케일링 부재 해명
기존 연구에서 보고된 “스케일링이 안 된다”는 현상은 주로 유효성(validity)·다양성(diversity) 같은 표면적 지표에 의존했기 때문이다. 본 논문은 토큰‑레벨 손실이 계속 감소함에도 불구하고, 생성 샘플의 화학적 다양성은 표현에 따라 포화점이 다르게 나타난다는 점을 실험적으로 입증한다. 즉, 스케일링은 존재하지만 평가 메트릭이 이를 포착하지 못한 것이 원인이다. -
공개 모델 라이브러리
300개의 모델을 GitHub에 공개함으로써, 향후 연구자는 특정 파라미터‑데이터‑표현 조합을 재현하거나 새로운 베이스라인으로 활용할 수 있다. 이는 화학 AI 분야에서 재현 가능성을 크게 향상시킨다.
전반적으로 이 연구는 “연산 예산 고정 → 파라미터‑데이터‑표현 삼각형 최적화”라는 프레임워크를 제시하고, 실제 실험을 통해 이론적 스케일링 법칙이 분자 언어 모델에도 적용됨을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기