프리픽스 중요도 비율로 정책 최적화 안정화
초록
본 논문은 대형 언어 모델(LLM) 강화학습(RL) 사후 학습에서 오프‑폴리시 상황이 심해질 때 토큰‑레벨 중요도 비율이 초래하는 불안정성을 지적한다. 저자는 이론적으로 정확한 보정값은 누적된 프리픽스 중요도 비율임을 증명하고, 이를 직접 사용하면 수치적 폭발과 길이 편향이 발생한다는 문제를 제시한다. 이를 해결하기 위해 최소 프리픽스 비율(MinPRO)이라는 비누적 서브스트레이트를 도입해, 현재 토큰 비율에 이전 토큰들 중 최소 비율을 곱함으로써 변동성을 크게 낮추고 학습 안정성을 확보한다. 실험 결과, 다양한 밀집·MoE 모델과 수학 추론 벤치마크에서 MinPRO가 기존 GRPO, GSPO, CISPO, M2PO 등에 비해 더 높은 보상과 안정적인 수렴을 보여준다.
상세 분석
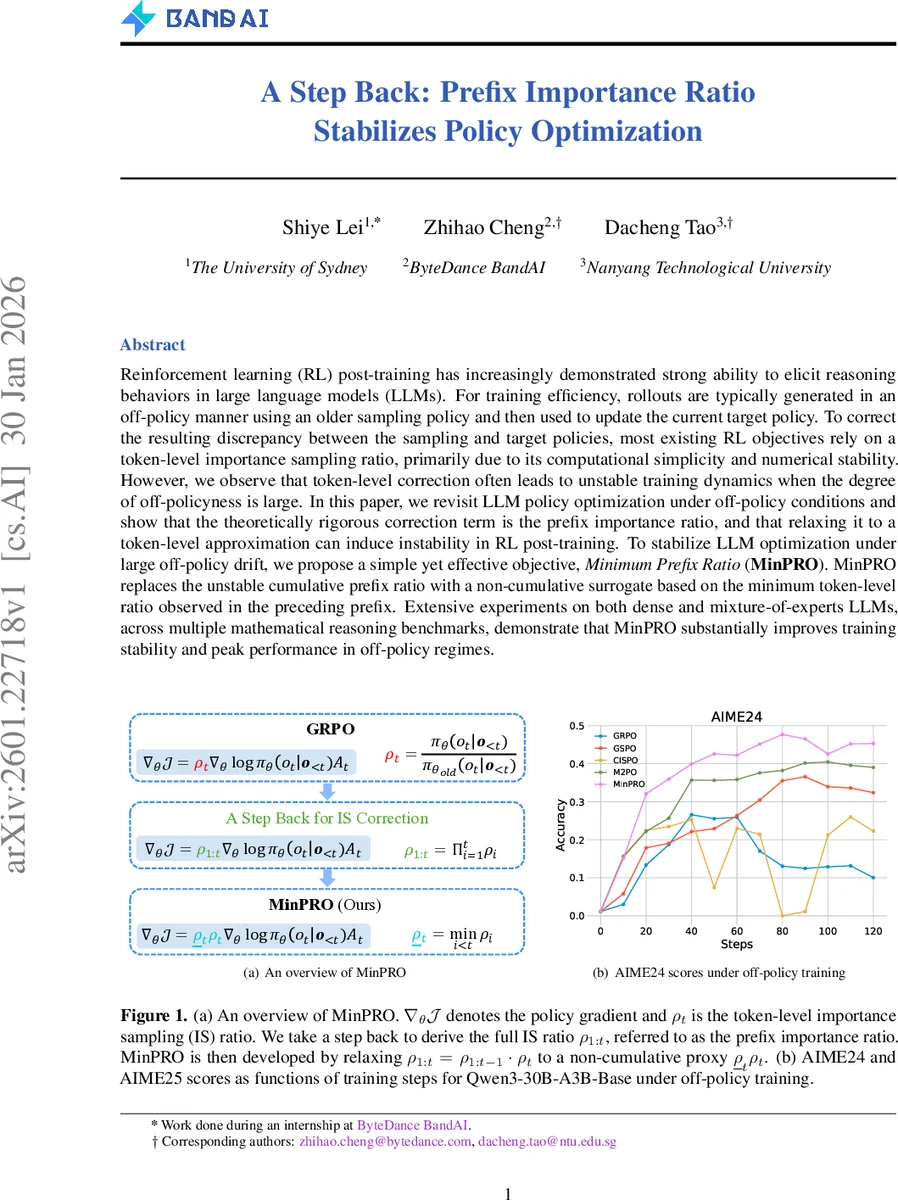
논문은 LLM에 대한 RL 사후 학습이 크게 두 단계, 즉 오래된 정책 π_old 로 롤아웃을 생성하고 이를 현재 정책 π 로 업데이트하는 오프‑폴리시 파이프라인을 따른다는 점을 출발점으로 삼는다. 기존의 대부분 RL 목표는 PPO 기반의 토큰‑레벨 중요도 비율 ρ_t = π(o_t|o_{<t}) / π_old(o_t|o_{<t}) 를 사용한다. 이는 계산이 간단하고 로그‑그라디언트에 바로 적용할 수 있어 실무에서 널리 쓰여 왔다. 그러나 저자는 정책 그래디언트 정리를 오프‑폴리시 상황에 적용했을 때, 실제 보정 인자는 누적된 프리픽스 중요도 비율 ρ_{1:t} = ∏_{i=1}^t ρ_i 라는 것을 수학적으로 증명한다 (Theorem 1). 이 비율은 현재 토큰이 속한 전체 접두사가 현재 정책에 의해 얼마나 잘 샘플링되는지를 반영한다.
프리픽스 비율을 그대로 사용하면 두 가지 근본적인 문제에 봉착한다. 첫째, 곱셈 연산으로 인해 값이 급격히 커지거나 작아져 수치적 폭발·언더플로우가 발생한다. 특히 LLM의 롤아웃 길이가 10 000 토큰을 초과하는 경우, ρ_{1:t}는 지수적으로 변동하여 그래디언트 분산을 크게 증가시킨다. 둘째, 마지막 토큰에 가까워질수록 누적 효과가 누적돼 길이 편향이 심해진다. 즉, 긴 시퀀스에서는 앞쪽 토큰의 기여가 무시되고, 뒤쪽 토큰에 과도한 가중치가 부여돼 정책 업데이트가 불안정해진다.
이를 해결하기 위해 제안된 MinPRO는 “최소 프리픽스 비율”이라는 비누적 근사치를 도입한다. 구체적으로, 현재 토큰 t의 비율 ρ_t와 이전 토큰들 중 최소값 ρ_{min}^{<t}=min_{i<t} ρ_i 를 곱해 ρ̃_{1:t}=ρ_t·ρ_{min}^{<t} 로 대체한다. 이 설계는 두 가지 장점을 제공한다. 첫째, 최소값을 사용함으로써 전체 누적 곱의 폭발을 방지하고, 값이 0에 가까워지는 경우에도 안정적인 상한을 유지한다. 둘째, 최소값은 전체 시퀀스 중 가장 불리한 구간을 대표하므로, 해당 구간이 현재 정책에 의해 거의 샘플링되지 않을 때 그래디언트 크기를 자연스럽게 억제한다. 결과적으로 변동성이 크게 감소하고, 토큰‑레벨 클리핑(ε_low, ε_high)과 결합해 기존 방법보다 더 견고한 학습이 가능해진다.
실험에서는 Qwen3‑8B‑Base, Qwen3‑14B‑Base(밀집형)와 Qwen3‑30B‑A3B‑Base(MoE) 세 모델을 대상으로, AMC23, AIME24/25, Math500, Olympiad, Minerva, GSM8K 등 7개의 수학 추론 벤치마크에서 오프‑폴리시 드리프트를 크게 늘린 상황을 시뮬레이션했다. 보상 곡선과 엔트로피 변화를 보면, GRPO·GSPO·CISPO·M2PO는 오프‑폴리시에서 급격한 진동과 종종 학습 붕괴를 보이는 반면, MinPRO는 일관된 보상 상승과 낮은 엔트로피 변동을 유지한다. 특히 AIME24/25와 같은 고난이도 문제에서는 MinPRO가 최고 점수를 기록했으며, MoE 모델에서도 동일한 안정성 향상이 관찰되었다.
이 논문은 LLM RL 최적화에서 “프리픽스 수준의 중요도 보정”이 필수적임을 이론과 실험으로 입증하고, 누적 곱의 수치적 한계를 최소값 기반 비누적 근사로 효과적으로 극복한 점이 가장 큰 공헌이다. 향후 연구에서는 MinPRO를 다른 클리핑 전략이나 가치‑함수 기반 방법과 결합하거나, 비누적 보정의 다른 형태(예: 평균·중위수)를 탐색함으로써 더욱 일반화된 오프‑폴리시 안정화 기법을 개발할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기