엔트로피 기반 동적 절단으로 효율적인 사유 체인 구현
초록
본 논문은 대규모 추론 모델(LRM)의 사유 체인 길이를 동적으로 줄이기 위해, 초기 추론 단계에서 출력 분포의 엔트로피를 신뢰도 지표로 활용한다. 엔트로피가 낮아지면 모델이 충분히 확신한 것으로 판단하고, 이후 추론을 중단해 최종 답변을 생성한다. 이를 ‘EntroCut’이라 명명하고, 토큰 절감 대비 정확도 손실을 정량화하는 새로운 지표 EPR을 제안한다. 실험 결과, 네 가지 수학 벤치마크에서 최대 40 % 토큰을 절감하면서 정확도 저하를 최소화한다.
상세 분석
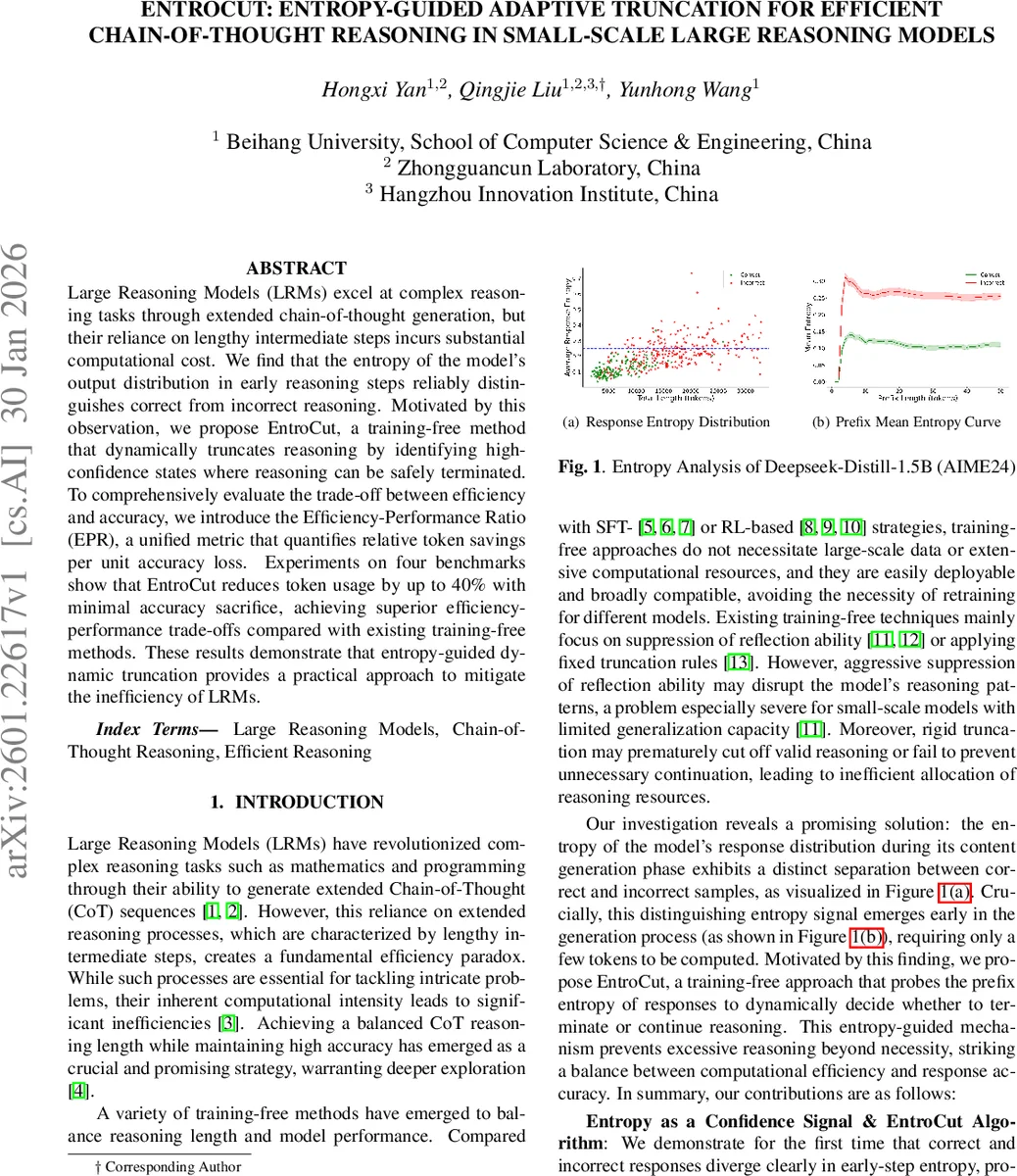
EntroCut은 사전 학습된 LRM에 추가적인 파인튜닝 없이 적용 가능한 ‘training‑free’ 방식이다. 핵심 가정은 모델이 초기 추론 단계에서 생성하는 토큰들의 확률 분포 엔트로피가 올바른 추론과 오류 추론을 명확히 구분한다는 점이다. 논문은 DeepSeek‑R1‑Distill‑Qwen‑1.5B(1.5B)와 7B 모델을 대상으로, AIME24·25, Math500, AMC23 네 데이터셋에서 엔트로피 분포를 시각화하고, 올바른 샘플은 평균 엔트로피가 낮은 반면 오류 샘플은 높은 경향을 보임을 확인한다.
이를 기반으로, 현재까지 생성된 사유 토큰 뒤에 특수 프로브 문자열(예: “\n\nSo the final answer is”)을 삽입하고, 그 뒤 k 개의 토큰에 대한 엔트로피 H_i를 계산한다. k개의 평균 엔트로피 (\bar H_{probe})가 사전에 정의된 임계값 τ (모델·데이터셋별로 실험적으로 설정) 이하이면, 모델이 충분히 확신한 것으로 판단하고 사유 단계(think phase)를 종료한다. 이후에는 별도 제한 없이 최종 답변을 생성하도록 허용한다.
EntroCut은 두 가지 구현 세부 사항을 포함한다. 첫째, 모든 토큰마다 엔트로피를 측정하는 것이 비효율적이므로, 모델이 “wait”와 같은 반사(reflection) 토큰을 출력할 때만 프로브를 트리거한다. 이는 모델이 자연스럽게 생각을 정리하고 새로운 반성을 시작하는 시점과 일치해, 엔트로피 측정 시점을 최적화한다. 둘째, 엔트로피 임계값 τ는 모델 크기와 데이터 특성에 따라 다르게 설정되며, 실험에서는 DS‑1.5B에 0.15, DS‑7B에 0.225 등으로 튜닝하였다.
효율성‑성능 트레이드오프를 정량화하기 위해 제안된 EPR(Efficiency‑Performance Ratio)은 토큰 절감 비율을 정확도 손실 비율로 나눈 값이다. 기준점은 ‘Vanilla’(전체 사유 체인 유지)와 ‘NOWAIT’(반사 토큰 전부 억제) 두 극단 모델이며, EPR이 클수록 적은 토큰 손실로 높은 정확도를 유지한다는 의미다.
실험에서는 EntroCut이 토큰 사용량을 평균 30‑40 % 감소시키면서, 정확도 손실은 1‑2 % 수준에 머물렀다. 특히 DS‑1.5B에서는 평균 EPR이 4.05에 달했으며, 기존 방법인 NOWAIT, TIP, DEER에 비해 모두 우수한 결과를 보였다. 파라미터 스위프를 통한 Pareto 곡선에서도 EntroCut이 동일 토큰 범위 내에서 최고의 정확도를 제공함을 확인했다.
Ablation 연구에서는 (1) ‘hard budget’ 변형—사유 단계 종료 직후 바로 답변을 강제—가 정확도를 크게 떨어뜨려, 사유 단계 이후의 응답 생성이 성능 유지에 필수적임을 보여준다. (2) ‘without entropy probe’—고정 길이로 사유를 종료—는 엔트로피 기반 제어보다 정확도와 EPR 모두에서 열등함을 입증한다.
한계점으로는 엔트로피 임계값 설정이 모델·데이터마다 별도 튜닝을 요구한다는 점과, 프로브 문자열 삽입이 일부 토큰 오버헤드를 발생시킨다는 점을 들 수 있다. 또한, 현재는 수학·논리 문제에 초점을 맞추었으므로, 복합적인 언어 이해나 대화형 상황에서의 일반화 가능성은 추가 검증이 필요하다.
전반적으로 EntroCut은 사유 체인의 불필요한 길이를 동적으로 줄이는 실용적인 방법을 제시하며, EPR이라는 통합 효율성 지표를 통해 다양한 모델·태스크 간 비교를 가능하게 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기