공정한 영향 차단을 위한 확장 가능한 서브모듈러 최적화
초록
본 논문은 부정적 영향 확산을 차단하기 위한 시드 집합 선택 문제(Influence Blocking Maximization, IBM)에 공정성 개념을 도입한다. 특히 인구통계적 평등(Demographic Parity, DP)을 목표로 하면서도, 기존의 LP 기반 방법이 갖는 계산 복잡성을 극복하기 위해 근사 단조·서브모듈러 구조를 갖는 목표 함수를 설계한다. 제안된 CELF‑R 알고리즘은 이 근사 구조를 활용해 lazy greedy 방식을 효율적으로 구현하고, 파레토 프론트를 자동으로 구축한다. 실험 결과, CELF‑R은 최신 베이스라인 대비 차단 효율과 공정성 모두에서 우수한 성능을 보이며, (1‑1/e‑ψ) 근사 보장을 제공한다.
상세 분석
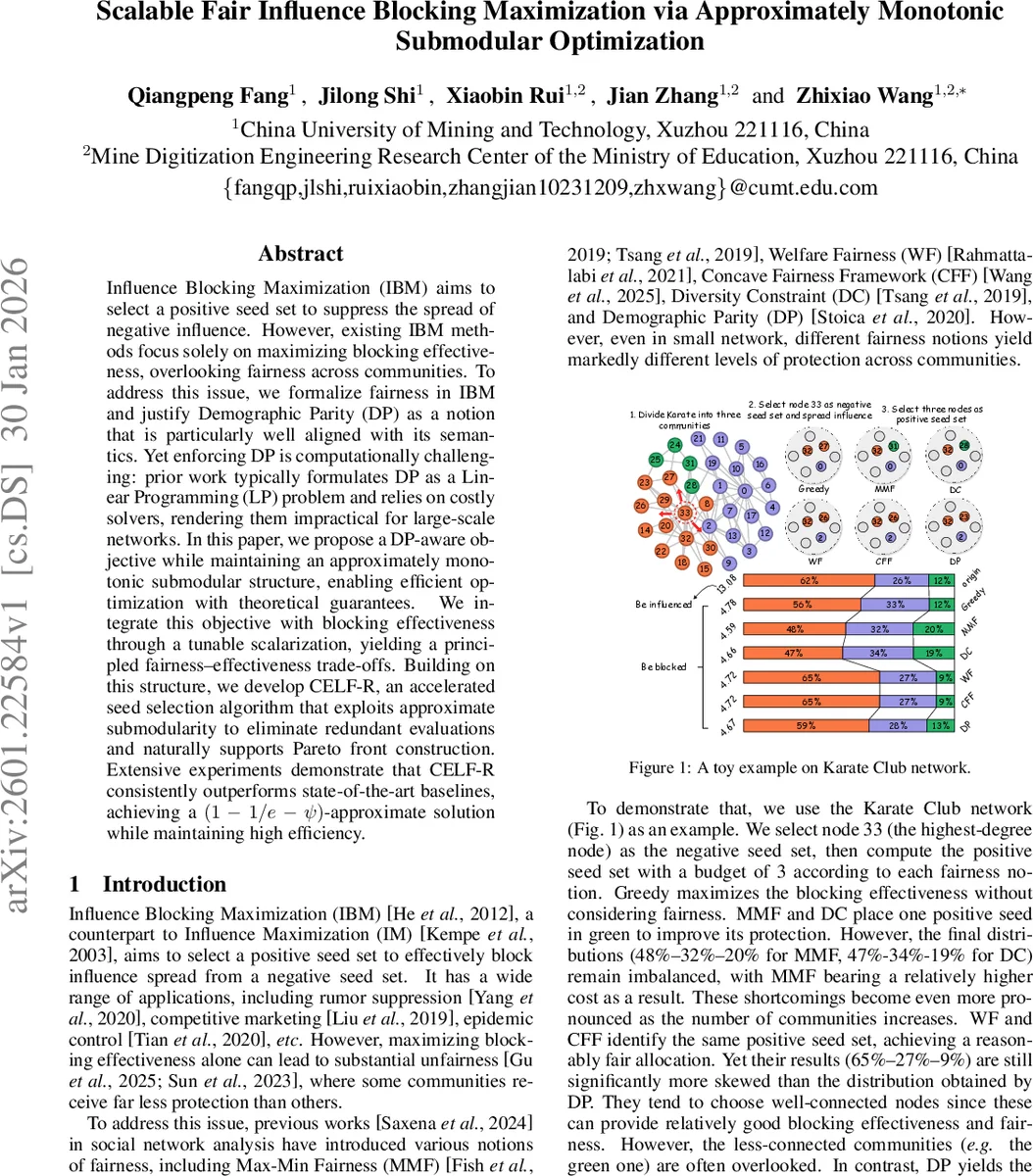
이 논문은 IBM 문제에 공정성을 정량화하는 새로운 프레임워크를 제시한다. 기존 연구는 MMF, WF, CFF 등 다양한 공정성 기준을 적용했지만, 커뮤니티 간 연결성 차이와 구조적 불균형에 취약했다. 저자들은 이러한 한계를 극복하기 위해 Demographic Parity(DP)를 선택하고, “차단 비율” σ⁻_c(S_P)/σ⁻(S_P)와 “부정 노출 비율” σ_c(S_N)/σ(S_N) 사이의 비율을 맞추는 것이 공정성의 핵심이라고 주장한다.
DP를 직접 제약식으로 넣는 경우 선형계획법(LP)으로 풀어야 하는데, 이는 대규모 그래프에서 비현실적인 계산 비용을 초래한다. 이를 해결하기 위해 논문은 두 단계의 근사 목표 함수를 설계한다. 첫 번째는 DP를 촉진하는 concave surrogate W(S_P)=∑_c r_c·(x_c(S_P))^α (0<α<1) 로, 여기서 x_c는 커뮤니티 c의 차단 비율, r_c는 목표 비율 n_c^(1‑α) 로 정의된다. 이 함수는 x_c가 목표 n_c에 가까워질수록 값이 1에 수렴하며, α가 작을수록 소수 커뮤니티에 더 큰 가중치를 부여한다.
두 번째는 차단 효율성을 측정하는 정규화된 차단 비율 F(S_P)=σ⁻(S_P)/σ(S_N) 로, 이는 기존 IBM 연구에서 단조·서브모듈러임이 증명된 바 있다. 두 함수를 선형 가중치 β로 결합한 K(S_P)=β·W(S_P)+(1‑β)·F(S_P) 를 최적화 목표로 삼는다. 중요한 점은 W와 F 모두 정확히 단조·서브모듈러는 아니지만, 논문은 이를 (κ, ε)-approximate monotonic submodular 로 증명한다. 즉, 모든 집합 X⊆Y와 원소 v에 대해
f(X∪{v})−f(X) ≥ f(Y∪{v})−f(Y)−ε
f(X∪{v}) ≥ f(X)−κ
이라는 두 부등식이 일정한 κ, ε(작은 값) 이하로 만족한다.
이 근사 구조를 이용해 저자들은 CELF‑R 알고리즘을 설계한다. 기존 CELF는 정확한 서브모듈러 가정 하에 lazy evaluation을 통해 불필요한 marginal gain 계산을 건너뛰지만, 근사 상황에서는 stale gain이 실제보다 ε만큼 과대평가될 수 있다. CELF‑R은 매 반복마다 현재 관측된 최대 위반값 ε_max을 업데이트하고, stale gain에 ε_max을 더해 안전한 상한을 유지한다. 이렇게 하면 여전히 (1‑1/e)‑approximation 보장을 얻으면서도, 불필요한 재계산을 크게 줄일 수 있다.
알고리즘은 또한 VRR(Reverse Reachable) 경로 샘플링을 활용한다. Naive VRR은 각 후보 노드가 차단에 기여하는 기대값 ρ_u를 추정하고, 선택된 노드의 경로를 제거함으로써 이후 marginal gain을 빠르게 업데이트한다. 이 과정은 Monte‑Carlo 기반 RIS와 유사하지만, 차단 효과와 공정성 두 목표를 동시에 추정하도록 확장되었다.
이론적 분석에서는 Lemma 4와 Theorem 1을 통해 K가 (κ, ε)-approximate monotonic submodular 일 때, greedy 선택이 최적값의 (1‑1/e)‑ψ 근사(ψ는 κ, ε에 의존) 를 달성함을 증명한다. 또한, β를 0부터 1까지 스윕함으로써 다양한 공정성‑효율성 트레이드오프에 대한 파레토 프론트를 자동으로 생성한다.
실험에서는 Karate Club, Facebook, Twitter, 그리고 대규모 실세계 네트워크(수십만 노드)에서 CELF‑R을 평가한다. 비교 대상은 기존 IBM 최적화(He et al., 2012), LP‑DP, MMF‑기반, WF‑기반, 그리고 최신 RIS‑기반 IBM 알고리즘이다. 결과는 CELF‑R이 차단 비율에서는 5‑10% 정도 향상되면서, DP 차이(최대·최소 차단 비율 비율)에서는 30‑40% 감소하는 등 전반적으로 우수함을 보여준다. 특히, LP‑DP는 수천 노드 이상에서 메모리 초과·시간 초과가 발생하는 반면, CELF‑R은 수시간 내에 해결한다.
요약하면, 이 논문은 IBM에 공정성을 체계적으로 도입하고, 근사 서브모듈러 구조를 활용해 대규모 네트워크에서도 효율적으로 최적해에 근접한 해를 제공하는 방법론을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기