ASTRA 자동화된 에이전트 궤적 합성과 검증 가능한 강화 학습 프레임워크
초록
ASTRA는 도구 호출 그래프의 정적 토폴로지를 활용해 다중 턴 툴 사용 궤적을 자동으로 생성하고, 인간 질문‑답변 흐름을 규칙 검증 가능한 코드 환경으로 변환한다. 이를 통해 대규모 감독 학습(SFT)과 온라인 강화 학습(RL)을 결합한 두 단계 학습 파이프라인을 제공하며, 여러 툴 사용 벤치마크에서 동일 규모 모델 중 최첨단 성능을 달성한다.
상세 분석
본 논문은 도구‑증강 에이전트 훈련의 두 가지 핵심 병목을 동시에 해결한다. 첫 번째는 툴 사용 데이터의 스케일링 문제이다. 저자들은 MCP(Multi‑Component Platform) 서버에서 제공되는 툴 문서를 수집·정규화하고, 동일 서버 내 툴 간 의존 관계를 그래프 형태로 모델링한다. 이 그래프에서 길이‑제한 랜덤 워크를 수행해 다양한 툴 체인을 샘플링하고, 각 체인에 대해 입력‑출력 스키마 일관성을 검증한다. 이렇게 얻어진 체인은 “툴‑체인”이라는 작업 조건으로 활용돼, LLM이 실제 실행 가능한 다중 턴 시나리오를 생성하도록 유도한다.
두 번째는 강화 학습 환경의 검증 가능성이다. 기존 연구는 LLM 자체가 시뮬레이션 엔진 역할을 하면서 비결정적 피드백을 제공했지만, 이는 보상 신호의 신뢰성을 저하시켜 장기 학습을 불안정하게 만든다. ASTRA는 질문‑답변 트레이스를 의미론적 토폴로지로 해석하고, 이를 독립적인 파이썬 코드 환경으로 자동 변환한다. 변환된 환경은 명시적 규칙과 테스트 스위트를 통해 실행 결과를 검증하므로, 에이전트가 받는 보상이 deterministic하고 재현 가능하다.
학습 절차는 두 단계로 구성된다. 먼저, 위에서 만든 고품질 툴 사용 궤적을 이용해 SFT를 수행함으로써 초기 정책을 툴 호출에 특화된 언어 모델로 강화한다. 이후, 변환된 검증 가능한 환경에서 온라인 RL을 진행한다. 보상 설계는 7가지 트래젝터리‑레벨 메트릭(질문 이해, 계획, 툴‑응답 이해·계획, 툴 성공률, 간결성, 최종 답변 품질)을 평균해 단일 스칼라 보상으로 통합한다. 이 보상은 작업 완수와 인터랙션 효율성을 동시에 최적화한다.
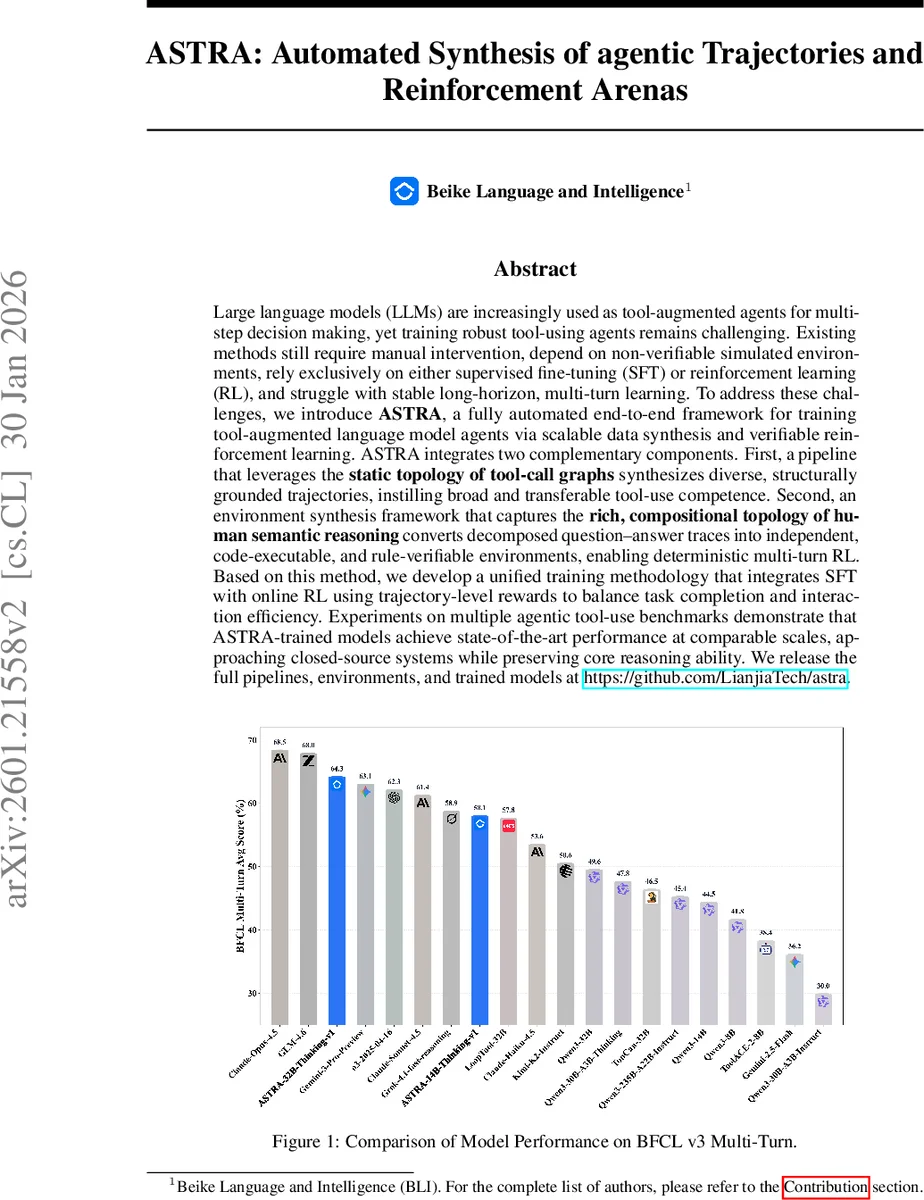
실험 결과는 BFCL v3, ToolBench 등 여러 공개 벤치마크에서 동일 파라미터 규모의 최신 오픈소스 모델들을 앞서는 성능을 보여준다. 특히, 장기 다중 턴 시나리오에서의 성공률과 툴 호출 효율성이 크게 개선되었으며, 폐쇄형 상용 시스템에 근접한 결과를 기록한다. 또한, 전체 파이프라인과 합성된 환경·데이터셋을 공개함으로써 재현성과 확장성을 확보했다.
핵심 기여는 (1) 툴‑체인 기반의 구조적 궤적 자동 생성 방법, (2) 의미론적 토폴로지를 활용한 규칙 검증 가능한 환경 합성 프레임워크, (3) SFT와 온라인 RL을 결합한 두 단계 학습 전략, (4) 다중 메트릭 기반의 균형 잡힌 보상 설계이다. 이러한 요소들은 툴 사용 에이전트가 인간 수준의 추론과 행동을 동시에 학습하도록 하는 데 중요한 전진을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기