대규모 조회 레이어
초록
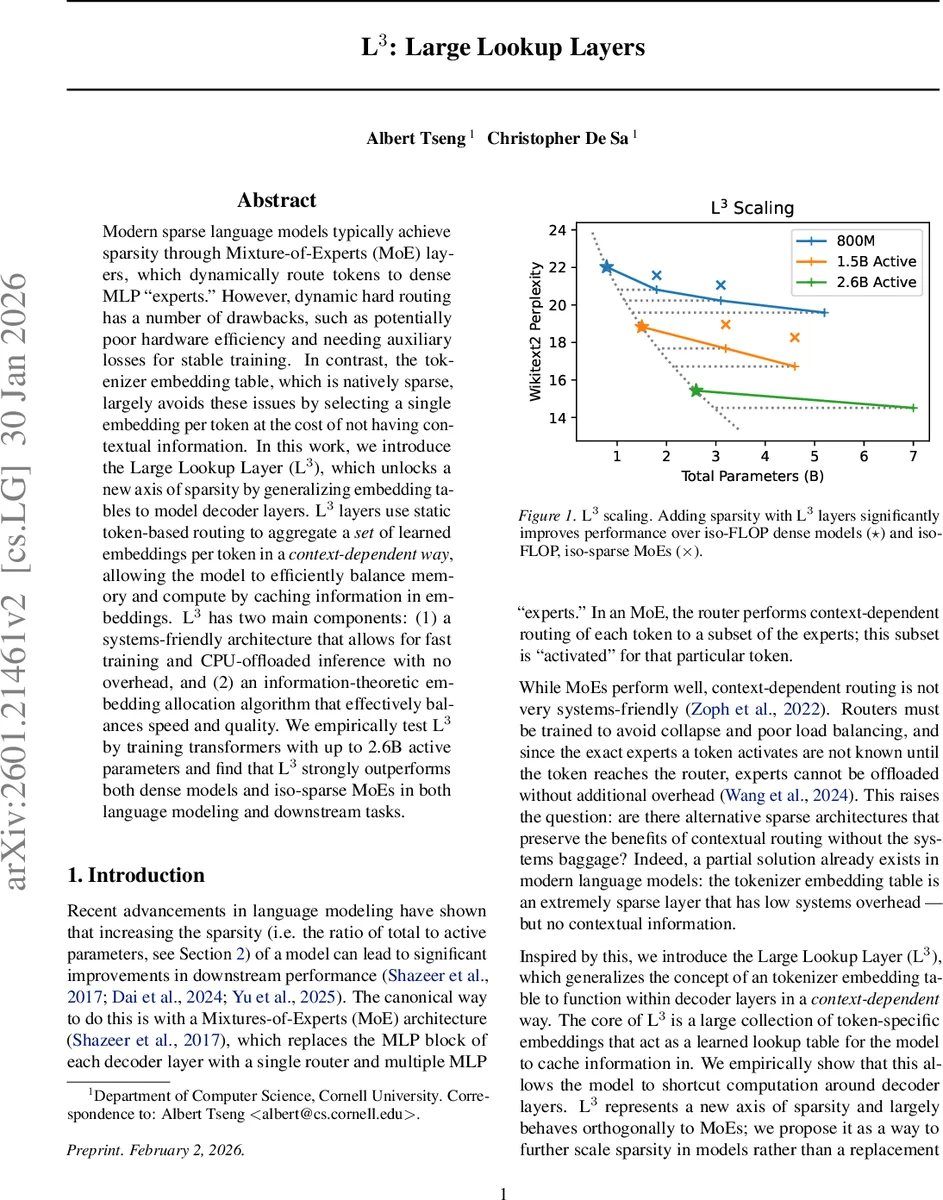
L³(Large Lookup Layer)는 토큰 ID 기반 정적 라우팅으로 여러 임베딩을 조회하고, 컨텍스트에 따라 어텐션으로 결합하는 새로운 희소성 메커니즘이다. LZW 기반 임베딩 할당 알고리즘으로 토큰 빈도에 맞춰 임베딩 수를 조절하고, 파라미터를 CPU에 오프로드해 학습·추론 효율을 크게 높인다. 2.6 B 활성 파라미터 모델에서 기존 밀집 모델과 동일 FLOP의 MoE를 능가한다.
상세 분석
본 논문은 기존 Mixture‑of‑Experts(MoE) 구조가 갖는 동적 라우팅의 하드웨어 비효율성, 라우터 불안정성, 보조 손실 필요성 등을 극복하기 위해 정적 토큰 라우팅을 채택한 Large Lookup Layer(L³)를 제안한다. L³는 토큰 ID마다 사전에 정의된 개수의 키·밸류 임베딩을 저장하고, 현재 토큰의 은닉 상태와 어텐션 연산을 통해 컨텍스트 의존적인 가중합을 수행한다. 이때 라우팅은 토큰 ID만으로 결정되므로, 토큰이 생성되는 순간 필요한 파라미터가 미리 알려져 CPU에 오프로드하거나 미리 페치할 수 있다. 이는 기존 MoE가 라우터 계산 후에야 전문가 파라미터를 알 수 있어 발생하는 메모리 이동 및 스케줄링 오버헤드를 근본적으로 제거한다.
임베딩 할당 단계에서는 전체 파라미터 예산(v) 내에서 토큰별 임베딩 수(dₜ)를 결정한다. 저자들은 LZW 압축 알고리즘을 변형해 코드를 생성하고, 코드 빈도에 따라 토큰에 할당할 임베딩을 선택한다. 자주 등장하는 토큰은 최대 k개의 임베딩을 받으며, 희귀 토큰은 최소 1개만 할당한다. 이 방식은 토큰 빈도 분포가 Zipf 법칙을 따르는 자연어에 최적화된 할당을 제공해, 동일 파라미터 수 대비 모델 품질을 크게 향상시킨다.
시스템 측면에서는 L³ 파라미터를 하나의 큰 행렬(K와 V를 각각 합친 W_K, W_V)로 구성하고, 배치 전체를 토큰 ID 기준으로 정렬해 블록 대각 어텐션 마스크를 만든다. 이렇게 하면 MegaBlocks, FlexAttention 등 기존 고성능 어텐션 커널을 그대로 활용할 수 있어 GPU 연산 효율이 높다. 또한, 배치 정렬 비용은 토큰 생성 전 사전 작업으로 처리되며, 오프로드된 파라미터는 사전 연산 단계에서 미리 CPU로 전송·프리페치가 가능해 추론 지연을 최소화한다.
실험에서는 2.6 B 활성 파라미터를 갖는 트랜스포머에 L³를 삽입해 사전 학습을 수행했으며, 동일 FLOP·파라미터 규모의 밀집 모델 및 iso‑FLOP MoE 대비 퍼플렉시티와 다운스트림 태스크 성능이 크게 개선되었다. 특히, L³는 토큰당 평균 활성 파라미터가 100 M 정도에 불과해 메모리 사용량과 전력 소모를 크게 낮추면서도, 컨텍스트 정보를 효과적으로 활용해 MoE와 비슷하거나 더 나은 품질을 달성했다.
요약하면, L³는 정적 토큰 라우팅과 정보이론적 임베딩 할당을 결합해, MoE가 제공하던 컨텍스트 의존적 파라미터 선택 효과를 하드웨어 친화적인 형태로 구현한다. 이는 대규모 언어 모델에서 파라미터 효율성을 극대화하고, CPU‑GPU 협업 추론을 자연스럽게 지원하는 새로운 설계 패러다임을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기