모델 저장소 속 숨은 보석 찾기
초록
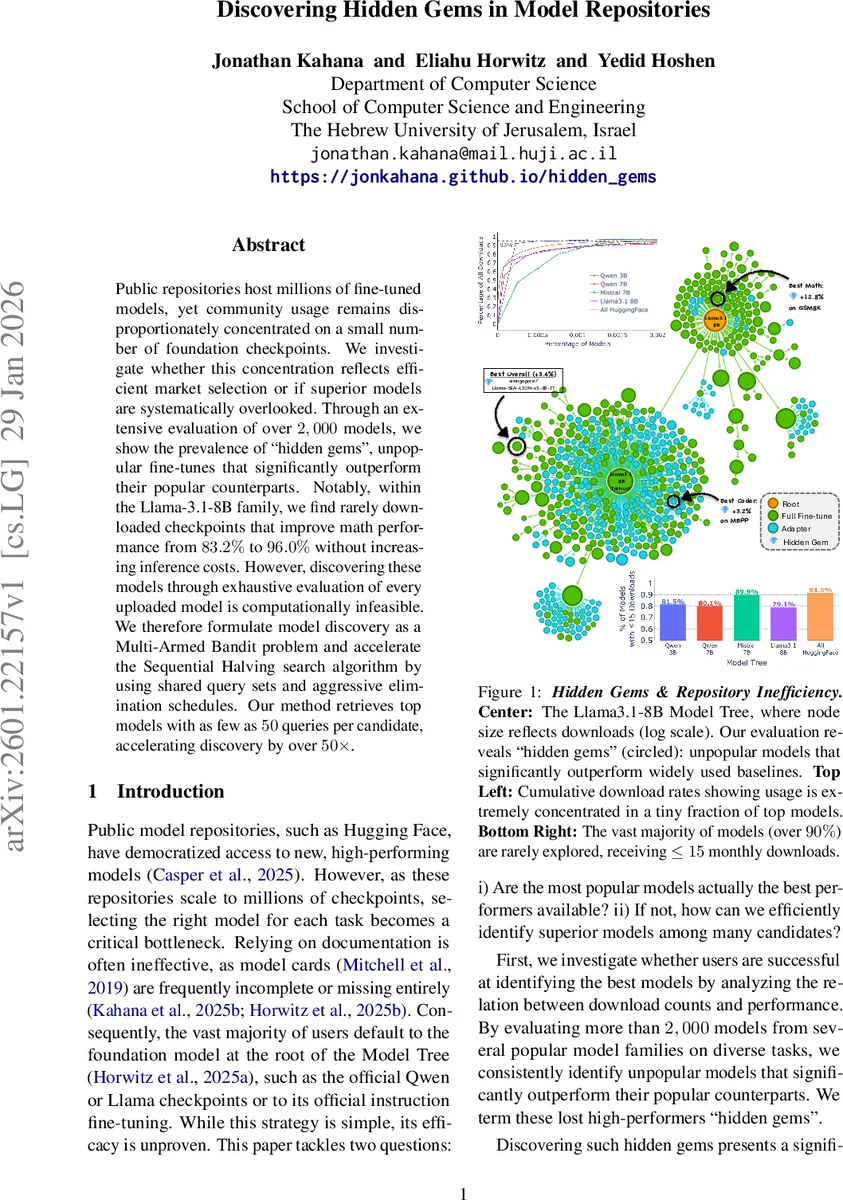
공개 모델 저장소에 수백만 개의 파인튜닝 모델이 존재하지만, 사용자는 소수의 기본 체크포인트에 몰려 있다. 2,000여 개 모델을 평가한 결과, 다운로드가 거의 없지만 성능이 뛰어난 “숨은 보석” 모델이 다수 존재함을 확인했다. 이를 효율적으로 탐색하기 위해 다중 팔 밴딧 문제로 정의하고, 공유 질의 집합과 공격적인 제거 스케줄을 적용한 가속화된 Sequential Halving 알고리즘을 제안한다. 평균 50개의 질의만으로 상위 모델을 찾아내어 기존 방법보다 50배 이상 빠르게 숨은 보석을 발견한다.
상세 분석
본 논문은 두 가지 핵심 질문에 답한다. 첫째, 현재 가장 많이 다운로드된 모델이 실제 최고 성능을 보이는가? 둘째, 수천~수백만 개의 후보 모델 중에서 뛰어난 모델을 효율적으로 찾을 수 있는 방법은 무엇인가? 이를 위해 저자들은 2,000여 개의 파인튜닝 모델을 동일한 모델 트리(공통 조상 모델에서 파생) 내에서 평가하고, 다운로드 수와 성능 간의 상관관계를 분석하였다. 결과는 다운로드가 0.0015%에 불과한 모델이 전체 다운로드의 95%를 차지하는 인기 모델을 크게 앞서는 경우가 빈번히 발생한다는 점이다. 특히 Llama‑3.1‑8B 트리에서는 다운로드가 거의 없던 모델이 GSM8K 수학 테스트에서 83.2%에서 96.0%로 정확도가 크게 상승했으며, 추론 비용은 동일하게 유지되었다.
숨은 보석을 정의하기 위해 ‘인기 합의군(P)’(다운로드 상위 1%)과 ‘엘리트 군(E) ’(성능 상위 1%)를 구분하고, P에 속하지 않으면서 E에 속하고, P 내 최고 성능보다 우수한 모델을 ‘Hidden Gem’이라 명명한다. 이 정의는 단순히 성능이 좋은 모델을 찾는 것이 아니라, 실제 사용자에게 알려지지 않은 고성능 모델을 식별한다는 점에서 의미가 크다.
하지만 모든 후보를 전수 조사하는 것은 계산량이 방대해 실현 불가능하다. 따라서 저자들은 이 문제를 고정 예산 최적 팔 식별(Fixed‑Budget Best‑Arm Identification) 형태의 다중 팔 밴딧(MAB) 문제로 재구성한다. 기존의 Sequential Halving(SH) 알고리즘은 라운드마다 일정 비율(보통 50%)만 제거해 예산 효율이 낮다. 이를 개선하기 위해 두 가지 기법을 도입한다. 첫째, ‘상관 샘플링(Correlated Sampling)’을 통해 라운드마다 모든 살아남은 모델에 동일한 질의 집합을 적용한다. 이는 모델 간 성능 차이 추정의 분산을 크게 감소시켜, 적은 샘플로도 신뢰할 수 있는 순위를 산출한다. 둘째, ‘공격적 제거 스케줄( aggressive elimination schedule)’을 적용해 초기 라운드에서 후보 수를 100개 이하로 급격히 축소한다. 대부분의 저품질 모델은 소수의 질의만으로도 식별 가능하므로, 남은 예산을 상위 후보의 정밀 평가에 집중할 수 있다.
실험에서는 Qwen‑3B, Qwen‑7B, Mistral‑7B, Llama‑8B 네 개 트리를 대상으로, 총 예산 B = N × K (N은 모델당 평균 질의 수, K는 후보 수) 하에서 10과 50 질의 두 시나리오를 테스트했다. 10질의(극저예산)에서는 대부분의 기존 베이스라인이 인기 모델보다 못하거나, 최소한 무작위 선택 수준에 머물렀다. 반면 제안 방법은 일관되게 상위 3위 안에 숨은 보석을 포함시켰으며, 평균 정확도는 0.7260.791 사이로 가장 높은 성능을 기록했다. 50질의(중간 예산)에서는 기존 SH나 UCB 계열도 어느 정도 개선됐지만, 여전히 최적 모델과의 격차가 존재했다. 제안 알고리즘은 평균 순위 13위, 정확도 0.729~0.796을 달성해 50배 이상의 효율 향상을 입증했다. 추가적인 ablation 연구에서는 상관 샘플링과 공격적 제거가 각각 성능에 미치는 영향을 확인했으며, 두 기법 모두 없이 하면 성능이 급격히 저하됨을 보였다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 현재 커뮤니티가 주로 사용하는 인기 모델이 실제 최고 성능을 보장하지 않으며, 정보 비대칭으로 인해 고성능 모델이 장기간 ‘숨은 보석’으로 남아 있다. 둘째, 대규모 모델 저장소에서 효율적인 모델 탐색을 위해서는 전통적인 인기 기반 필터링이 아닌, 제한된 질의 예산 하에서의 탐색적 베스트‑암 식별 전략이 필요하다. 제안된 가속화된 SH는 공유 질의와 공격적 프루닝을 통해 실용적인 탐색 비용을 제공하므로, 향후 모델 허브(예: Hugging Face)에서 자동화된 모델 추천 시스템에 직접 적용될 가능성이 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기