마스터 가중치 없이 양자화 학습을 가능하게 하는 ECO 최적화기
초록
ECO는 양자화된 가중치에 직접 업데이트를 적용하고, 발생하는 양자화 오차를 옵티마이저 모멘텀에 주입함으로써 마스터 가중치(고정밀 복사본)를 완전히 제거한다. 이 방법은 추가 메모리 없이도 수렴을 보장하며, FP8·INT4 등 극저비트 정밀도에서 기존 마스터‑가중치 기반 학습과 거의 동일한 정확도를 달성한다.
상세 분석
본 논문은 대규모 언어 모델(LLM) 학습에서 메모리 사용량을 크게 차지하는 마스터 가중치 버퍼를 없애는 새로운 옵티마이저인 ECO(Error‑Compensating Optimizer)를 제안한다. 기존 양자화 학습은 작은 업데이트가 양자화 그리드보다 작아 사라지는 현상을 방지하기 위해 FP32 혹은 FP16 수준의 마스터 가중치를 유지한다. 이는 특히 Sparse Mixture‑of‑Experts(SMoE)와 같이 파라미터와 옵티마이저 상태가 메모리의 대부분을 차지하는 모델에서 치명적인 오버헤드가 된다. ECO는 매 스텝마다 양자화된 가중치 ˆθₜ를 업데이트한 뒤, 양자화 연산 q(·)에 의해 발생하는 오차 eₜ₊₁ = ˜θₜ₊₁ – ˆθₜ₊₁를 계산하고, 이를 모멘텀 버퍼 m에 ˆmₜ₊₁ = ˜mₜ₊₁ + α·eₜ₊₁ 형태로 주입한다. 여기서 α = (1/η)(1 – 1/β)이며, η는 학습률, β는 모멘텀 계수이다. 이 과정은 오차 피드백 루프를 형성해 양자화 손실을 다음 스텝에 보정한다.
핵심 기술적 공헌은 두 가지이다. 첫째, 모멘텀 버퍼 자체를 오류 저장소로 재활용함으로써 별도의 오류 버퍼를 필요로 하지 않는다. 둘째, eₜ와 eₜ₊₁가 서로 근접한다는 경험적 관찰을 기반으로, 이전 오차를 명시적으로 저장하지 않고 현재 오차만을 사용해 m ← m + (1/η)(1 – 1/β)·eₜ₊₁ 라는 메모리‑프리 업데이트 규칙을 도출한다.
이론적으로는 비볼록 L‑스무스 함수와 감소하는 학습률 가정 하에, ECO가 최적점 근처의 고정 반경 영역으로 수렴함을 증명한다. 수렴 반경은 기존 마스터‑가중치 기반 SGD‑Momentum의 최적 경계보다 (1/(1–β²)) 배만큼만 크게 늘어나며, 이는 실제 실험에서 무시할 수준이다. 반면, 마스터 가중치를 단순히 제거하고 오류를 보정하지 않을 경우, 수렴 오차가 η⁻¹에 비례해 무한히 커지는 악조건을 보인다.
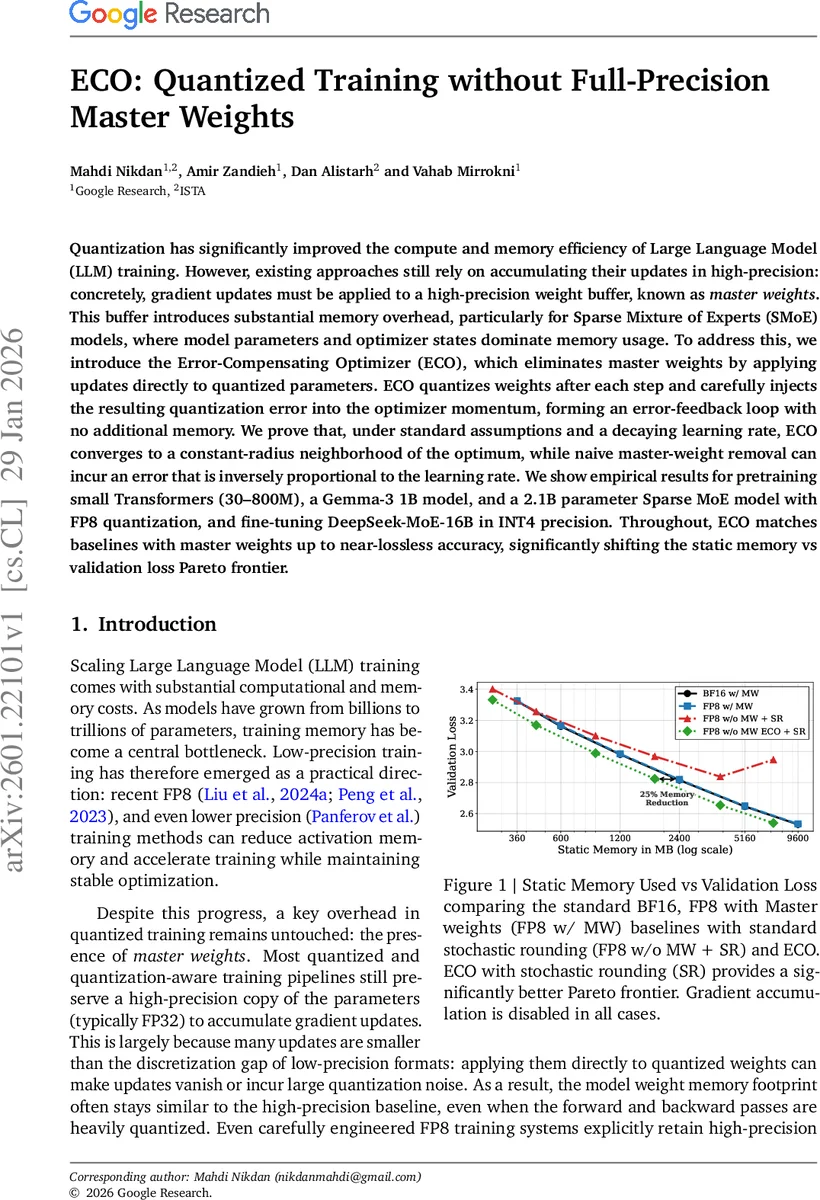
실험에서는 30M~800M 규모의 작은 트랜스포머, 1B Gemma‑3, 2.1B SMoE, 그리고 16B DeepSeek‑MoE를 각각 FP8·INT4 정밀도로 사전학습·미세조정하였다. 모든 설정에서 ECO는 마스터 가중치를 사용한 BF16/FP8 기준과 거의 동일한 검증 손실을 기록했으며, 정적 메모리 사용량을 최대 25% 절감했다. 특히 stochastic rounding(SR)과 결합했을 때 메모리‑손실 Pareto 곡선이 크게 이동하는 것이 관찰되었다.
요약하면, ECO는 마스터 가중치 없이도 양자화 학습의 수렴성을 유지하고, 메모리 효율성을 크게 향상시키는 실용적인 솔루션이며, 특히 메모리 제한이 심한 SMoE와 같은 대규모 모델에 직접 적용 가능하다.
댓글 및 학술 토론
Loading comments...
의견 남기기