수술 로봇을 위한 경량 Mixture‑of‑Experts 기반 행동 예측 모델
초록
**
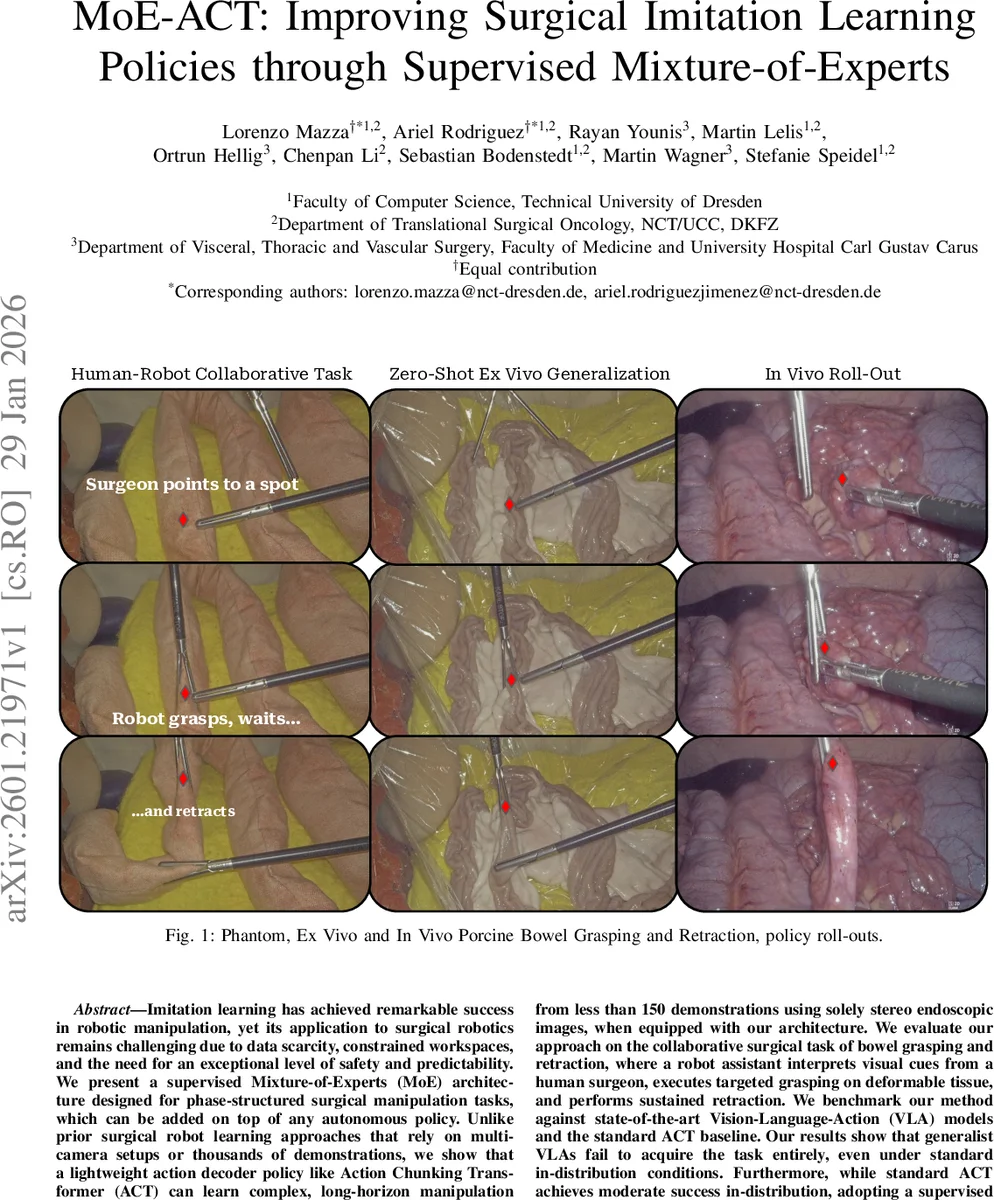
본 논문은 수술용 최소 침습 로봇의 장기 작업을 제한된 데이터와 단일 내시경 영상만으로 학습하기 위해, 단계별 라벨을 이용해 전문가들을 명시적으로 지도하는 감독형 Mixture‑of‑Experts(MoE) 구조를 기존 Action Chunking Transformer(ACT)에 결합한다. 150개 이하의 시연으로도 장폐색 잡기·당김 작업을 성공적으로 수행하며, 시점 변동·조명 저하·부분 가림 등 OOD 상황에서도 일반적인 Vision‑Language‑Action(VLA) 모델보다 뛰어난 견고성을 보인다. 또한, 훈련에 사용한 인공 모델을 그대로 적용해 외부(Ex‑vivo) 돼지 장에 80% 이상의 성공률을 기록하고, 초기 In‑vivo 시연 영상도 제시한다.
**
상세 분석
**
본 연구는 수술 로봇 제어에 있어 두 가지 핵심 난제를 동시에 해결한다. 첫째, 최소 침습 수술(MIS) 환경에서는 다중 카메라나 깊이 센서를 설치하기 어려워 3D 정보를 얻기 힘들다. 둘째, 임상 데이터는 윤리·규제·시간 비용 때문에 수백 개 수준에 머무른다. 이러한 제약 하에 기존의 대규모 사전학습 기반 Vision‑Language‑Action(VLA) 모델은 파라미터 수와 연산량이 과다해 실시간 제어에 부적합하고, 데이터가 부족하면 학습이 불안정해진다.
논문은 이러한 문제를 해결하기 위해 ‘감독형 Mixture‑of‑Experts’를 제안한다. 핵심 아이디어는 수술 작업이 자연스럽게 ‘phase’(예: idle, approach, hold, retract, maintain) 로 구분된다는 점을 이용해, 각 phase마다 별도의 전문가 네트워크를 배치하고, 게이팅 네트워크는 실제 phase 라벨을 직접 학습한다는 것이다. 이렇게 하면 전문가 간의 모드 붕괴(mode collapse)나 활용 불균형을 방지하면서, 각 단계에 특화된 행동 분포를 효율적으로 모델링한다.
구조적으로는 기존 ACT의 변분 프레임워크 위에 MoE 블록을 삽입한다. 이미지 인코더(CNN) → 변분 잠재 변수 z → Transformer encoder‑decoder → MoE 블록(액션 전문가, 그리퍼 전문가, 게이팅) → 최종 행동 청크를 출력한다. 학습 손실은 네 가지 구성요소(L1 행동 재구성, phase 교차 엔트로피, 그리퍼 BCE, KL 정규화)로 이루어져 있어, 행동 정확도와 phase 예측 정확도를 동시에 최적화한다.
실험은 두 대의 UR5e 로봇과 스테레오 내시경을 이용한 OpenHELP 팬텀에서 수행되었다. 고정 시점 데이터 120회와 랜덤 시점 데이터 50회를 수집했으며, 각 시연은 자동으로 phase 라벨링되었다. 비교 대상은 (1) 기본 ACT, (2) SmolVLA(소형 VLA), (3) π0.5(대형 VLA). 결과는 다음과 같다.
- In‑distribution: ACT+MoE가 85% 이상의 성공률을 기록, 기본 ACT는 62%, VLA 계열은 0%에 가까웠다.
- Out‑of‑distribution: 새로운 잡기 위치, 저조도, 부분 가림, 시점 변동 등 네 가지 변형에서 MoE‑ACT는 평균 78% 성공률을 유지했으며, 다른 모델은 급격히 성능이 떨어졌다.
- Zero‑shot ex‑vivo: 훈련에 사용되지 않은 돼지 장에 그대로 적용했을 때 80% 성공률을 달성, 이는 기존 VLA가 전혀 동작하지 못한 것과 대조적이다.
- In‑vivo 예비 시연: 실제 돼지 수술 중 정책을 실행한 영상이 제시되었으며, 비록 정량적 평가는 부족하지만, 정책이 실시간으로 안정적인 그립·당김을 수행함을 보여준다.
또한 파라미터 수는 ACT 52M, MoE‑ACT 53.3M으로 차이가 거의 없으며, 학습 시간도 3시간 수준으로 경량성을 유지한다. 이는 기존 대규모 VLA(수백억 파라미터, 수일 학습)와 비교해 실용적인 장점이다.
한계점으로는 (1) 현재는 phase 라벨이 반드시 제공되어야 하는 ‘감독형’ 접근법이라 라벨링 비용이 존재한다. (2) 실시간 안전 검증을 위한 형식적 방법론이 부재하고, 임상 적용을 위한 규제·윤리 검토가 필요하다. (3) 실험이 주로 팬텀·ex‑vivo 수준에 머물러 있어, 장기적인 in‑vivo 임상 시험이 아직 부족하다.
전반적으로, 이 논문은 “작업 단계가 명확히 구분되는 수술 로봇 작업에, 라벨링된 phase 정보를 활용한 MoE 구조를 도입함으로써 데이터 효율성과 견고성을 동시에 확보한다”는 중요한 교훈을 제공한다. 향후 라벨 자동 추출, 안전 검증 프레임워크와 결합한다면, 실제 수술실에 적용 가능한 경량 자율 로봇 시스템으로 확장될 가능성이 크다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기