연속 제어에서 오류 증폭이 ANN SNN 변환을 제한한다
초록
본 논문은 연속 제어 환경에서 ANN‑to‑SNN 변환 시 발생하는 작은 행동 근사 오류가 시간적으로 상관되어 누적·증폭됨으로써 상태 분포가 크게 변하고 성능이 급격히 저하되는 현상을 규명한다. 이를 완화하기 위해 잔여 막전위를 다음 의사결정 단계로 전달하는 Cross‑Step Residual Potential Initialization(CRPI) 방식을 제안하고, 벡터·시각 기반 연속 제어 벤치마크에서 기존 변환 파이프라인에 적용했을 때 성능 회복 효과를 입증한다.
상세 분석
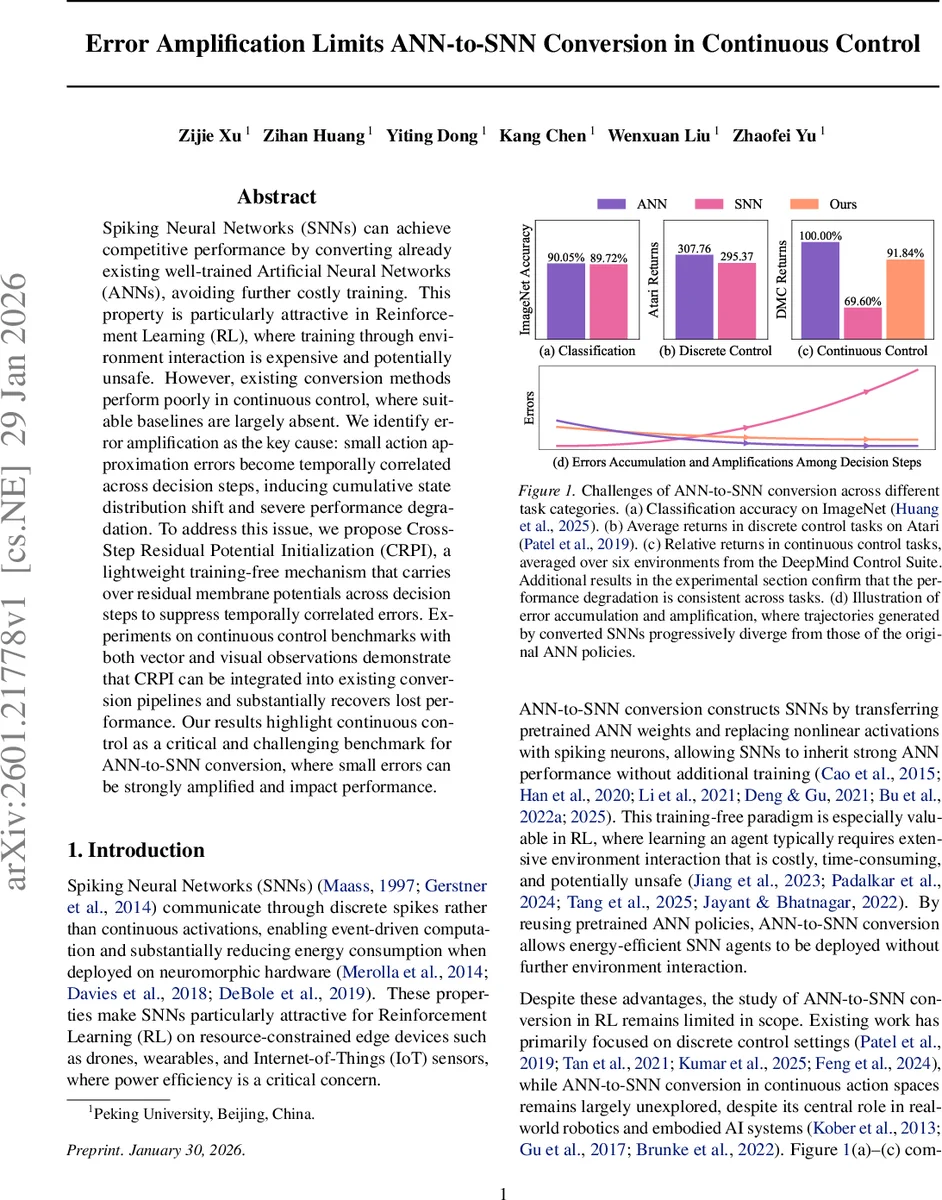
논문은 먼저 기존 ANN‑to‑SNN 변환 기법이 이미지 분류와 이산 제어에서는 비교적 높은 성능을 유지하지만, 연속 제어에서는 급격히 성능이 떨어지는 현상을 실험적으로 확인한다. 이를 설명하기 위해 변환된 SNN 정책의 기대 반환을 두 가지 요소, 즉 “행동 오류”와 “상태 분포 이동”으로 분해한다. 실험 결과, 동일한 상태 분포에서 ANN과 SNN이 선택한 행동 차이는 미미하지만, SNN이 만든 상태 분포 자체가 ANN과 크게 달라져 전체 반환 손실의 대부분을 차지한다는 점을 밝혀냈다.
다음으로 시간 축에서 오류가 어떻게 누적되는지를 분석한다. 연속 제어는 마코프 결정 과정(MDP) 특성상 현재 행동이 미래 상태와 보상에 직접적인 영향을 미치므로, 작은 행동 근사 오차가 다음 단계의 상태를 왜곡하고, 이 왜곡이 다시 행동에 반영되어 오류가 점진적으로 확대된다. 논문은 이를 “오류 증폭” 현상이라고 정의하고, 실제 환경(HalfCheetah‑v4, Hopper‑v4 등)에서 상태 궤적이 초기에는 거의 일치하지만 에피소드가 진행될수록 급격히 발산하는 모습을 시각화한다.
핵심 원인으로는 행동 오류가 연속적인 의사결정 단계 사이에서 양의 상관관계를 보인다는 점을 제시한다. 즉, 한 단계에서 발생한 오차가 다음 단계에서도 비슷한 방향으로 유지되어 오류가 누적된다. 기존 변환 방법은 각 의사결정 단계마다 신경망 상태(막전위)를 초기화하기 때문에 이러한 상관성을 끊어내지 못한다.
이를 해결하기 위해 제안된 CRPI는 “잔여 막전위 전달” 메커니즘이다. 변환된 SNN이 한 의사결정 단계에서 시뮬레이션을 마친 뒤, 각 뉴런의 남은 막전위를 다음 단계의 초기 전위로 그대로 넘겨준다. 이렇게 하면 이전 단계에서 남은 전위가 다음 행동 계산에 반영되어, 동일한 입력에 대한 스파이크 발생 패턴이 보다 일관되게 유지된다. 결과적으로 행동 오류의 시간적 상관성이 크게 감소하고, 상태 분포 이동이 억제된다.
CRPI는 추가 학습 없이 기존 변환 파이프라인에 바로 삽입할 수 있는 경량 기법이며, 실험에서는 다양한 변환 기반(Weight Normalization, Threshold Balancing 등)과 결합했을 때 모두 성능 향상을 보였다. 특히 시각 입력을 사용하는 DMC 환경에서는 직접 학습한 SNN보다도 높은 반환을 달성했다.
전체적으로 이 연구는 연속 제어라는 고차원, 고정밀 요구 환경에서 ANN‑to‑SNN 변환의 근본적인 한계를 오류 증폭 메커니즘으로 규명하고, 잔여 전위 전달이라는 간단하지만 효과적인 해결책을 제시함으로써, 에너지 효율적인 스파이킹 정책의 실용성을 크게 확장한다.
댓글 및 학술 토론
Loading comments...
의견 남기기