영향 기반 샘플링으로 텍스트 검색 모델 도메인 적응 최적화
초록
본 논문은 다양한 코퍼스와 검색 과제에 대해 어떻게 샘플링할지를 다루며, 기존의 균등·크기 비례·전문가 지정 방식의 한계를 지적한다. 저자는 영향(influence) 점수를 보상으로 활용하는 강화학습 기반 프레임워크 Inf‑DDS를 제안한다. Inf‑DDS는 각 도메인(데이터셋)별로 작은 업데이트 후 dev 셋 성능 변화를 측정해 보상으로 사용하고, 이를 통해 샘플링 정책 ψ를 REINFORCE 방식으로 학습한다. 또한 Reptile‑style 메타‑업데이트를 이용해 모델 파라미터 θ와 샘플링 파라미터를 동시에 효율적으로 업데이트한다. 실험에서는 BEIR, MLDR‑13, 그리고 대규모 Sentence‑Transformers 학습 데이터에서 기존 DDS·DoGE 등 대비 0.9~5.0 NDCG@10 절대 향상을 기록했으며, GPU 비용도 1.5‑4배 절감하였다.
상세 분석
Inf‑DDS는 텍스트 검색 모델의 도메인 적응을 위한 데이터 샘플링 문제를 양층 최적화(bilevel optimization) 로 정식화한다. 상위 레벨에서는 샘플링 확률 분포 (P_D(i;\psi)=\frac{e^{\psi_i}}{\sum_j e^{\psi_j}}) 를 파라미터 (\psi) 로 조정해 목표 dev 셋의 성능을 최대화하고, 하위 레벨에서는 기존의 파라미터 (\theta) 를 일반적인 gradient descent 로 업데이트한다. 핵심 차별점은 보상 신호를 전통적인 gradient‑based DDS와 달리 영향 점수(influence score) 로 정의한다는 점이다. 구체적으로, 현재 모델 (\theta_t) 에 대해 특정 도메인 (D_i^{train}) 를 (l) 스텝 학습한 뒤 (\theta_{i}^{t+1}) 를 얻고, 이를 dev 셋 (D_j^{val}) 에 적용해 성능 변화 (\Delta M_{ij}=M(\theta_{i}^{t+1};d_j^{val})-M(\theta_t;d_j^{val})) 를 측정한다. 이 변화를 모든 dev 셋에 평균해 (\Delta M_i) 로 정규화하고, 이를 영향 점수 (I_i) 로 사용한다.
보상 계산이 데이터셋 수준에서 이루어지므로 개별 샘플에 대한 고비용 2차 미분이나 대규모 프록시 모델이 필요 없으며, Reptile‑style 메타‑업데이트를 통해 (\theta) 와 (\psi) 를 동시에 업데이트한다. 구체적으로, 각 도메인에 대해 (\theta_{i}^{t+1}) 와 (\theta_t) 의 차이를 (I_i) 로 가중합해 (\bar{\nabla}t) 를 만든 뒤, (\theta{t+1} = \theta_t + \alpha \bar{\nabla}_t) 로 진행한다. 이렇게 하면 그라디언트 캐시를 하나만 유지해 메모리 사용량을 크게 줄일 수 있다.
대규모 데이터셋 수 (M) 가 클 경우 모든 도메인에 대해 (I_i) 를 매 iteration 계산하는 비용이 prohibitive 하다. 저자는 무작위 서브샘플 (S\subset{D_i}) 을 선택해 (\psi) 의 업데이트를 근사한다. 이때 사용되는 정책 그래디언트는 (\nabla_\psi = \sum_{i\in S} P_D(i;\psi) I_i \nabla_\psi \log P_D(i|!S;\psi)) 로, 전체 목표에 대한 편향된 추정이지만 실험적으로 충분히 좋은 성능을 보인다.
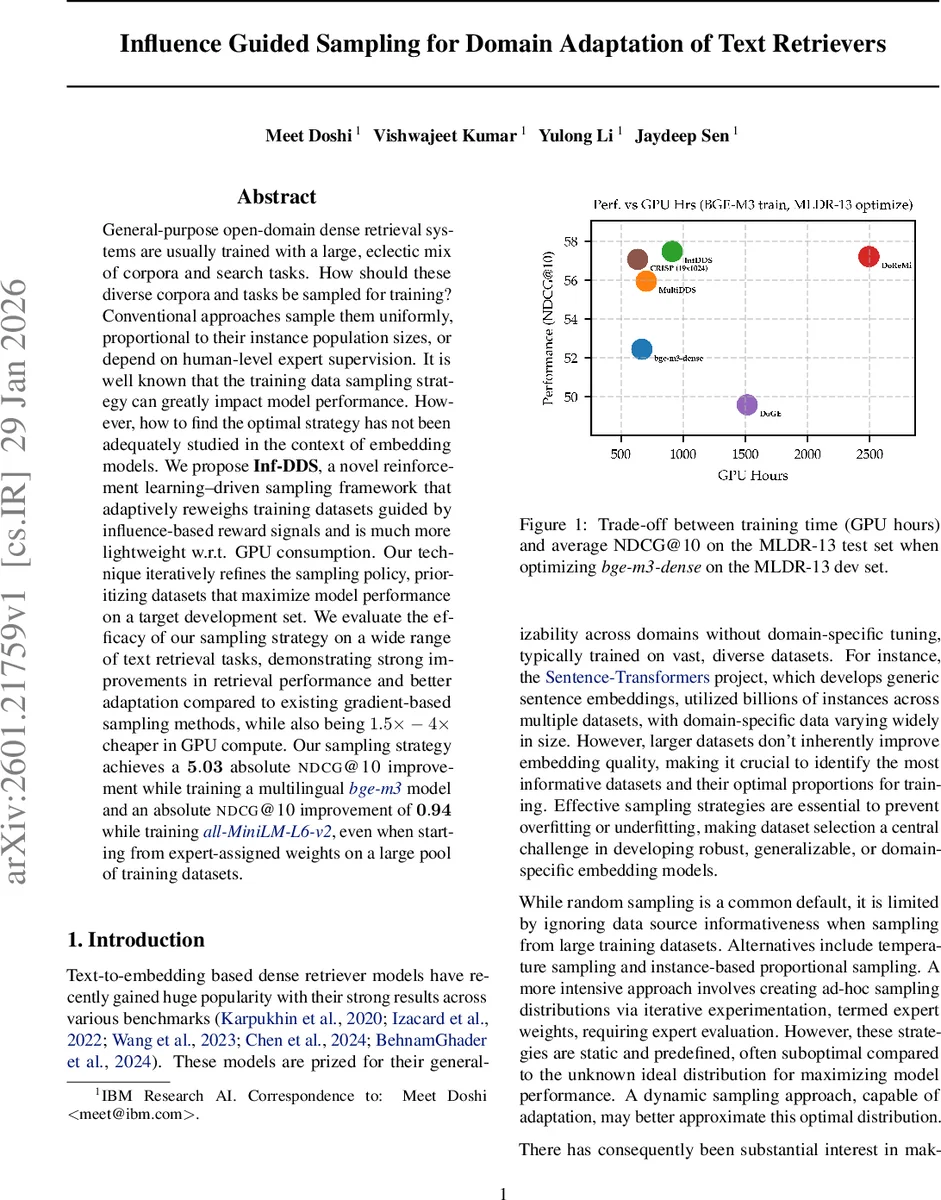
실험 설계는 세 가지 벤치마크를 포함한다. 1) BEIR: 7개의 도메인(예: MSMarco, NQ 등)에서 FEVER dev 셋을 목표로 샘플링을 최적화하고, 다른 도메인에서도 전이 성능을 측정한다. 2) MLDR‑13: 다국어 장문 검색에서 각 언어를 도메인으로 보고, bge‑m3 모델을 기반으로 5.03 NDCG@10 절대 향상을 달성했다. 3) Sentence‑Transformers: 1 B 토큰 규모의 32개 데이터셋을 포함한 대규모 학습에서 기존 전문가 지정 가중치(Expert init)를 초과하는 0.94 NDCG@10 향상을 기록했다. 모든 실험에서 GPU 시간 대비 1.5‑4배 비용 절감 효과가 입증되었다.
핵심 기여는 다음과 같다. (1) 노이즈가 큰 gradient‑based 보상 대신 정확한 영향 기반 보상을 사용해 학습 안정성을 크게 향상시켰다. (2) Reptile‑style 메타‑업데이트와 샘플링 파라미터 재활용을 통해 메모리와 연산량을 최소화했다. (3) 데이터셋 수준의 동적 샘플링을 통해 도메인 적응 효율을 높이고, 기존 전문가 지정 가중치를 능가하는 자동화된 샘플링 정책을 제공한다.
이러한 설계는 특히 대규모 멀티도메인 텍스트 임베딩 상황에서, 데이터 양이 방대하고 도메인 간 편차가 클 때, 효율적인 학습 자원 배분과 성능 최적화를 동시에 달성하고자 하는 실무자와 연구자에게 큰 의미를 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기