다비드가 골리앗을 이길 수 있을까? 자원 제한 환경에서의 다중 홉 추론
초록
**
본 논문은 소형 언어 모델을 강화학습(RL) 기반 다중 홉 질문응답 에이전트로 활용하면서, 제한된 연산·예산 하에서도 높은 정확도를 달성할 수 있음을 보인다. 저자들은 ‘DAVID‑GRPO’라는 예산 효율적인 프레임워크를 제안한다. 핵심은 (1) 소량의 전문가 시연을 이용한 few‑shot warm‑start, (2) 증거 문서 회수를 기반으로 한 ‘grounded retrieval reward’, (3) 부분 성공 경로를 재활용하는 ‘grounded expansion’이다. 1.5 B 파라미터 모델을 4대 RTX 3090 GPU만으로 학습시켰으며, 6개 다중 홉 QA 벤치마크에서 기존 대규모 모델 기반 RL 방법들을 일관적으로 앞섰다.
**
상세 분석
**
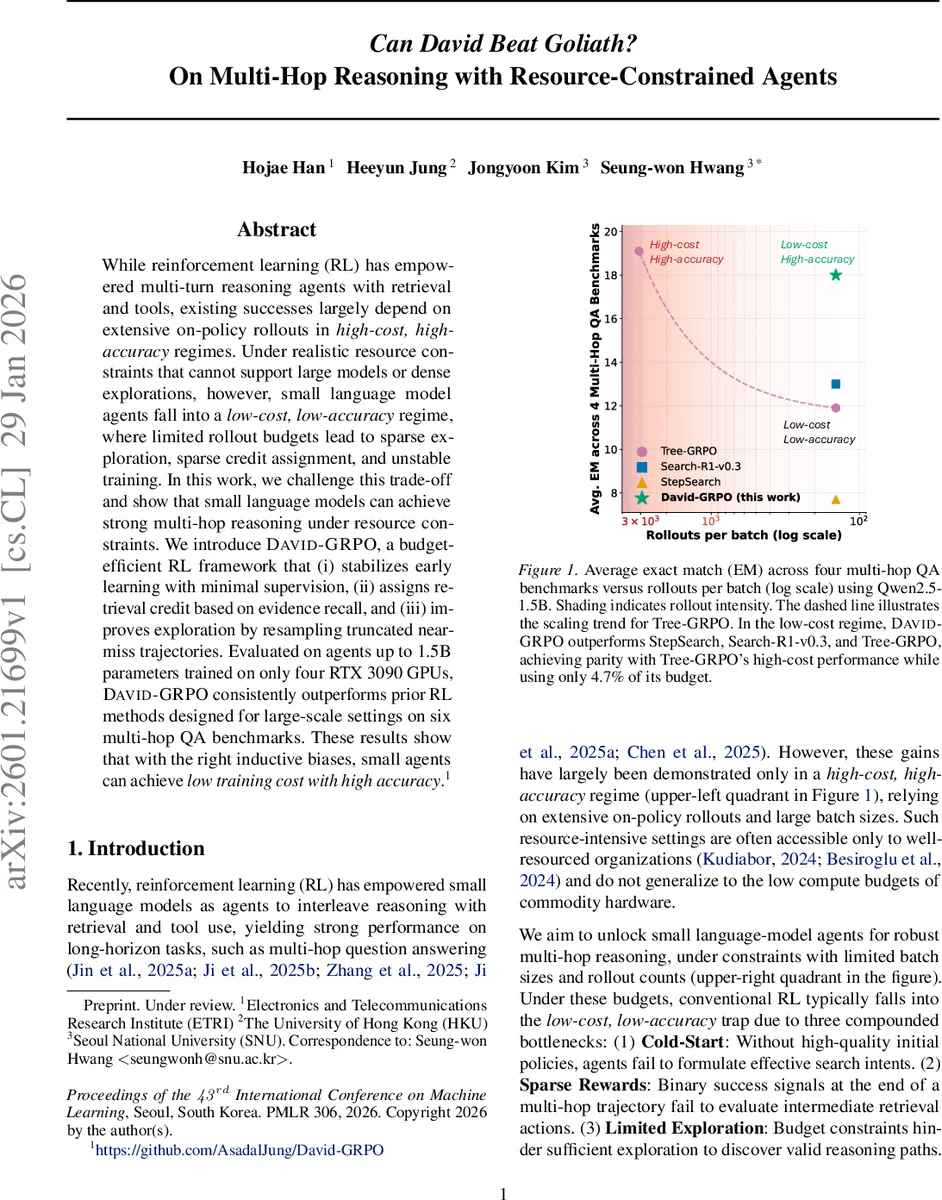
논문은 먼저 현재 RL‑기반 다중 홉 추론 연구가 고비용·고정밀 환경에 의존하고 있음을 지적한다. 대규모 모델과 대용량 배치를 활용하면 풍부한 온‑폴리시 롤아웃을 수행해 탐색과 보상 할당이 원활하지만, 실제 서비스·연구 환경에서는 GPU 메모리·시간·전력 제한으로 이러한 조건을 만족시키기 어렵다. 저자들은 이 문제를 ‘cold‑start’, ‘sparse reward’, ‘limited exploration’이라는 세 가지 병목으로 구체화한다.
1️⃣ Cold‑Start 해결: 기존 방법은 대규모 라벨링 혹은 강력한 교사 모델을 필요로 한다. DAVID‑GRPO는 ‘few‑shot warm‑start’를 도입해, 수십 개 수준의 전문가 시연(예: 큰 모델 또는 인간 annotator)만을 사용한다. 이 시연을 오프‑폴리시 샘플로 포함시켜 GRPO 손실에 혼합함으로써, 초기 정책이 전혀 보상을 받지 못하는 상황을 방지한다. 또한, 오프‑폴리시 중요도 가중치 ρ*를 도입해 정책 업데이트 시 교사 샘플에 적절한 advantage를 부여한다.
2️⃣ Sparse Reward 완화: 다중 홉 QA에서는 최종 정답만이 보상으로 주어지는 경우가 많아 중간 검색 단계의 기여도를 파악하기 어렵다. 논문은 ‘grounded retrieval reward (r_g)’를 정의한다. 전체 트랙션에서 수집된 문서 집합 D_union을 구하고, 이를 정답 증거 집합 D*와 교집합을 통해 recall 비율을 계산한다. r_g는 정확히 증거 문서를 회수했는지를 측정하므로, lexical similarity 기반 보상보다 잡음이 적고, 중간 브리지 문서까지 포괄한다. 최종 보상은 r_g와 정답 정확도 보상 r_o를 가중합(λ)으로 결합해, 탐색 단계와 최종 예측을 동시에 최적화한다.
3️⃣ Limited Exploration 보완: 예산이 제한되면 대부분의 롤아웃이 실패하고, GRPO의 advantage 추정이 불안정해진다. 저자들은 ‘grounded expansion’이라는 동적 재샘플링 전략을 제시한다. 그룹 내에서 부분적으로 성공한 트랙션(예: 일부 증거를 회수한 경우)을 식별하고, 해당 중간 상태를 시작점으로 새로운 탐색을 수행한다. 이렇게 하면 ‘near‑miss’ 경로를 재활용해 더 높은 보상의 트랙션을 발견할 확률이 크게 증가한다. 실험에서는 30% 수준의 전형적 실패 사례가 10% 이하로 감소하였다.
학습 효율성: DAVID‑GRPO는 1.5 B 파라미터 모델을 4대 RTX 3090 GPU(총 48 GB VRAM)에서 48 시간 이내에 학습한다. 기존 대규모 RL 방법(예: Tree‑GRPO, StepSearch)은 동일한 성능을 얻기 위해 최소 20배 이상의 GPU·시간을 요구한다.
실험 결과: 6개 다중 홉 QA 벤치마크(HotpotQA, MuSiQue, ComplexWebQuestions 등)에서 평균 Exact Match(EM) 점수가 4.7%12% 상승했으며, 특히 low‑cost 구간(rollout per batch ≈ 5)에서도 high‑cost 기준과 동등한 성능을 보였다. Ablation study는 (i) warm‑start 제거 → 초기 학습 불안정, (ii) r_g 제거 → 최종 정확도 69% 감소, (iii) grounded expansion 제거 → 탐색 효율 15% 감소를 각각 확인한다.
의의와 한계: 이 연구는 “작은 모델도 적절한 inductive bias와 효율적인 RL 설계만 있으면 다중 홉 추론을 충분히 수행할 수 있다”는 강력한 메시지를 전달한다. 다만, few‑shot 교사 시연을 얻기 위해서는 여전히 큰 모델이나 인간 라벨링이 필요하며, 증거 문서 집합 D*가 명시적으로 제공되는 데이터셋에 한정된다는 점이 있다. 향후 연구에서는 자동 pseudo‑positive 생성 혹은 self‑supervised 증거 추출 기법을 결합해 완전한 zero‑resource 설정을 목표로 할 수 있다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기