오버스케일링 저주를 깨다: 병렬 사고 전 사전 병렬도 예측
초록
본 논문은 LLM의 병렬 사고(parallel thinking)에서 전역 병렬도 N을 모든 샘플에 동일하게 적용하면, 실제로는 일부 샘플이 더 작은 병렬도 N′ 만으로도 동일한 정확도를 달성함에도 불구하고 불필요한 연산 비용이 발생한다는 “오버스케일링 저주”를 정의하고 정량화한다. 저자는 각 입력의 잠재 표현을 이용해 최적 병렬도를 사전 예측하는 경량 모델 T2를 제안하여, 전체 성능을 유지하면서 연산 비용을 크게 절감한다.
상세 분석
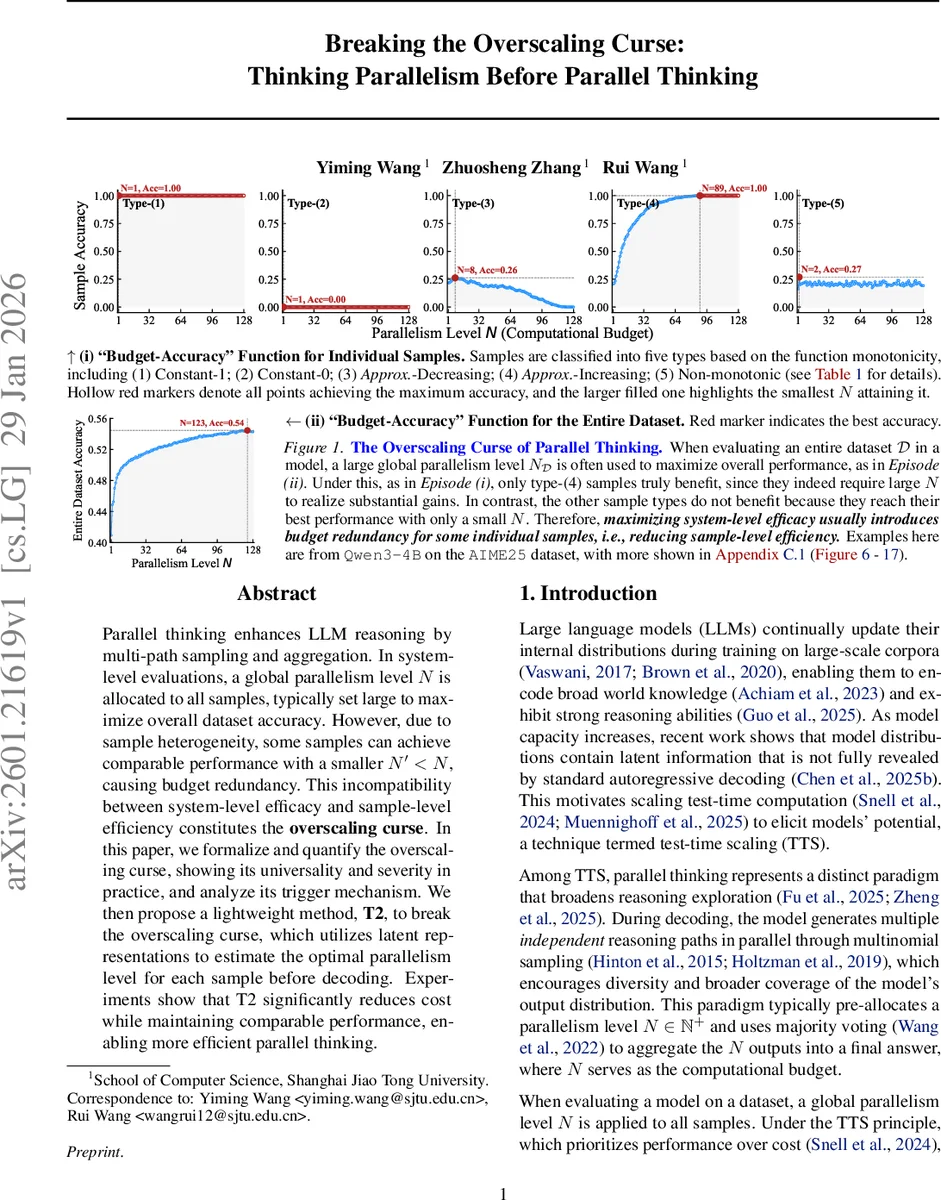
논문은 먼저 병렬 사고(parallel thinking)의 기본 메커니즘을 정리한다. LLM이 입력 x 에 대해 N 개의 독립적인 추론 경로를 생성하고, 다수결 투표로 최종 답을 선택한다. 전통적인 평가에서는 데이터셋 전체에 대해 하나의 전역 병렬도 N_D 를 고정하고, 이를 가능한 한 크게 설정해 전체 정확도 A_D(N) 를 최적화한다. 그러나 샘플별 정확도 함수 A_x(N) 를 조사하면, 대부분의 샘플은 N이 작아도 정확도가 포화하거나, 오히려 N이 커질수록 정확도가 감소하는 유형으로 구분된다. 저자는 이러한 현상을 다섯 가지 유형(상수 1, 상수 0, 근사 감소, 근사 증가, 비단조)으로 분류하고, 각 유형별 최적 병렬도 N*_x 와 전체 데이터셋 최적 병렬도 N_D 를 정의한다.
오버스케일링 저주는 정의(5)에서 N_D > N*_D (전체 최적 병렬도가 샘플별 평균 최적 병렬도보다 크다)로 공식화된다. 이를 정량화한 지표인 오버스케일링 인덱스 M_D = N*_D / N_D 는 0~1 사이 값을 갖으며, 1에 가까울수록 저주가 약함을 의미한다. 실험 결과, 6개의 데이터셋과 4개의 모델에 대해 M_D 값이 모두 0.5 이하이며, 일부 경우는 0.2 이하까지 떨어져 전체 연산 비용의 80% 이상이 낭비된다는 심각성을 보여준다.
왜 이런 현상이 발생하는가에 대한 분석에서는 유형‑4(근사 증가) 샘플이 핵심 원인임을 밝혀낸다. 유형‑4는 N이 커질수록 정확도가 크게 상승해 전체 데이터셋 성능을 끌어올리지만, 동시에 유형‑1~3,5는 큰 N에서 거의 이득을 얻지 못한다. 따라서 전역 N_D 를 크게 잡으면 유형‑4의 이득을 최대화하면서도 다른 샘플에선 불필요한 연산이 발생한다.
이를 해결하기 위해 저자는 “T2”(Thinking Parallelism Before Parallel Thinking)라는 경량 예측기를 제안한다. T2는 각 레이어의 최종 토큰 표현을 입력으로 받아, 레이어별 가중치를 학습한 뒤, 가중 평균을 통해 샘플별 최적 병렬도 ĤN* 를 추정한다. 학습 단계에서는 다양한 N에 대한 정확도 라벨을 이용해 회귀 손실을 최소화하고, 레이어별 검증 오차에 따라 가중치를 부여한다. 추론 시에는 입력을 먼저 인코딩하고, T2가 예측한 ĤN* 에 따라 실제 병렬 샘플링 수를 동적으로 할당한다.
실험에서는 T2가 기존 고정 N 전략 대비 평균 35%~60%의 연산 비용 절감과 메모리 사용량 감소를 달성하면서, 전체 정확도는 0.2% 이내로 유지되는 것을 확인한다. 또한, 기존 적응형 배치 방법(예: 비용‑성능 트레이드오프 기반)보다 학습·추론 오버헤드가 현저히 낮고, 다양한 모델·데이터셋에 대해 일관된 효과를 보인다.
결론적으로, 논문은 LLM 병렬 사고에서 “시스템‑레벨 효율성 vs 샘플‑레벨 효율성” 사이의 불일치를 정량화하고, 잠재 표현 기반 사전 예측을 통해 이를 해소하는 실용적인 방법을 제시한다. 이는 향후 대규모 LLM 서비스에서 비용 효율적인 추론 전략을 설계하는 데 중요한 지침이 될 것이다.
댓글 및 학술 토론
Loading comments...
의견 남기기