빠르고 기하학적으로 정밀한 로렌츠 신경망
초록
본 논문은 기존 로렌츠 모델 기반 하이퍼볼릭 선형층이 그래디언트 단계가 증가함에 따라 출력의 하이퍼볼릭 노름이 로그 스케일로 성장하는 문제를 지적한다. 이를 해결하기 위해 거리‑초평면(distance‑to‑hyperplane) 개념을 도입한 새로운 로렌츠 선형층을 제안하고, 이 층이 하이퍼볼릭 노름을 선형적으로 증가시킴을 증명한다. 또한 로렌츠 활성화 함수와 파라미터 캐싱 기법을 결합해 연산 효율성을 크게 향상시켜, 기존 로렌츠 및 포인케 네트워크 대비 학습·추론 속도를 2.9배~8.3배 가속한다.
상세 분석
논문은 먼저 하이퍼볼릭 공간에서 계층적 구조를 효율적으로 임베딩하려면 출력 벡터의 하이퍼볼릭 노름이 깊이에 비례해 선형적으로 증가해야 함을 강조한다. 기존 로렌츠 선형층(Chen et al., 2022)은 유클리드 좌표 Wx를 그대로 공간 좌표로 사용하고, 시간 성분을 ‖Wx‖에 비례하도록 정의한다. 이때 하이퍼볼릭 거리 d(o, y)≈arccosh(√κ·y₁)∝log‖Wx‖이 되므로, 깊이 h를 표현하려면 ‖Wx‖≈e^{h}가 필요하고, 이는 가중치 행렬의 Frobenius 노름도 e^{h} 수준으로 커져야 함을 의미한다. 결과적으로 그래디언트 업데이트 수가 O(e^{h})에 달해 실용성이 떨어진다.
이를 정량화하기 위해 Proposition 3.1–3.3을 제시한다. Proposition 3.1은 제한된 노름의 그래디언트 업데이트(δ) 하에서 하이퍼볼릭 노름 증가가 O(log n)임을 보이며, Proposition 3.2는 저왜곡 트리 임베딩에 필요한 최소 자식-부모 거리 s=Ω(ln m·√κ)임을 증명한다. 두 결과를 결합하면 깊이 h 트리를 임베딩하려면 Ω(e^{h}) 단계가 필요함을 도출한다.
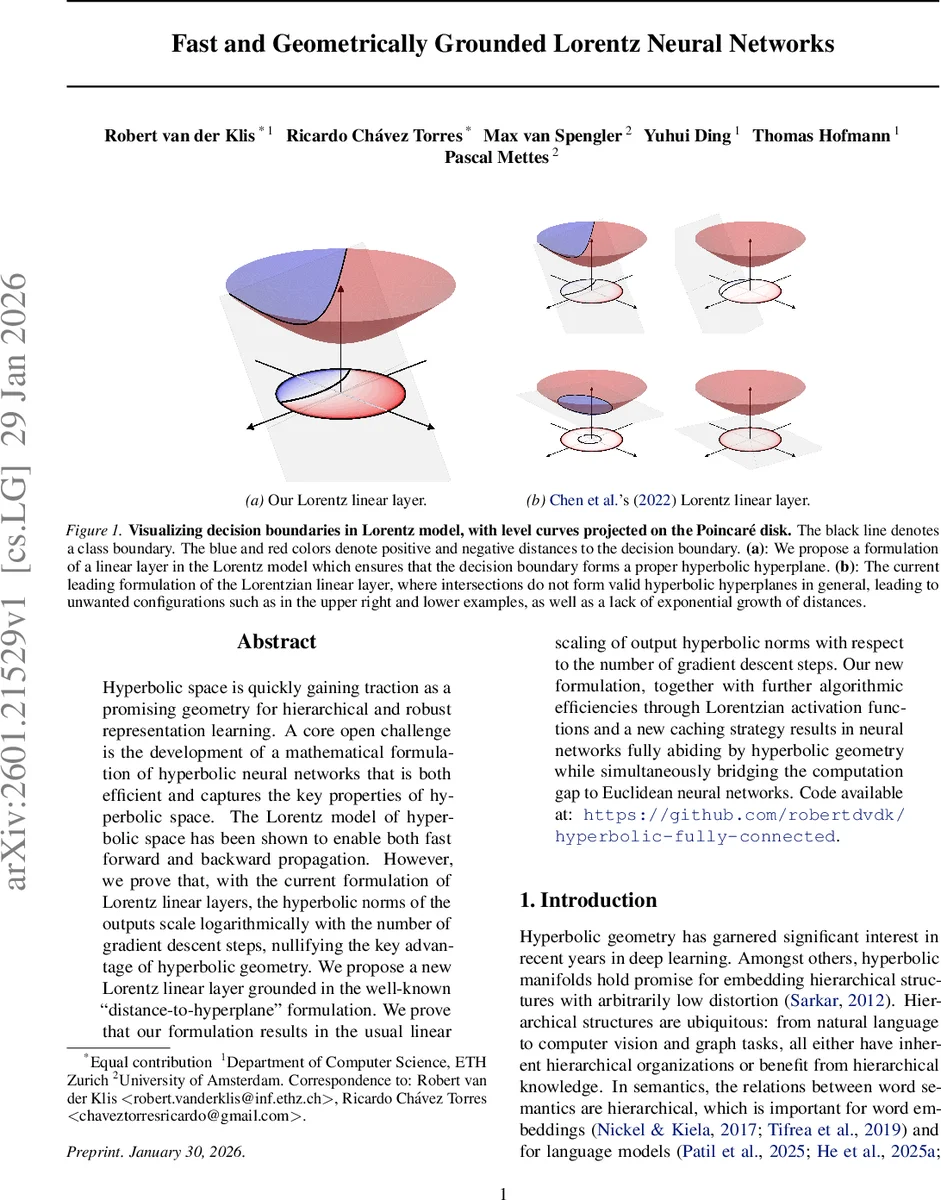
문제 해결을 위해 저자들은 Euclidean MLR(다중 로지스틱 회귀)의 거리‑초평면 해석을 로렌츠 모델에 그대로 옮긴다. 입력 매니폴드 M_in에 초평면을 정의할 때, 기준점 p_i를 원점에서 −b_i·‖w_i‖ 방향으로 Exp 연산을 통해 이동시킨다. 이후 평행 이동(Parallel Transport)으로 가중치 w_i를 p_i에 옮겨 v_i를 얻고, 초평면은 ambient space에서 단순히 z◦v_i=0인 점들의 집합으로 표현된다(Prop. 4.1).
이제 전활성값 z_i는 초평면까지의 부호·스케일된 거리로 정의한다. Theorem 4.2에 따르면 거리 d(x, H_i)= (1/√κ)·arcsinh(√κ·|x◦v_i| / ‖v_i‖_L)이며, 부호는 x◦v_i의 부호와 동일함(Prop. 4.3). 따라서 최종 전활성식은
z_i = (1/√κ)·arcsinh(√κ·x◦v_i / ‖v_i‖_L)·‖w_i‖_o
가 된다. 이 식은 Euclidean 선형층이 거리·가중치 크기로 스케일링되는 방식을 정확히 복제하면서, 하이퍼볼릭 거리의 로그‑선형 관계를 회피한다.
활성화 함수는 로렌츠 내에서 닫힌 형태를 유지하도록 설계된 “Lorentzian activation”을 도입해 연산량을 최소화한다. 또한 파라미터 v_i를 사전 계산해 캐시함으로써, 전방·후방 연산에서 매번 평행 이동을 수행할 필요가 없게 하여 2.9배(로렌츠)·8.3배(Poincaré) 속도 향상을 달성한다.
실험에서는 ResNet‑18 기반 FGG‑LNN을 기존 로렌츠 및 포인케 네트워크와 비교했으며, 학습 시간은 각각 3.5배·7.5배 가속되었다. 정확도와 계층적 임베딩 품질은 기존 방법과 동등하거나 약간 상회한다.
결과적으로, 논문은 하이퍼볼릭 신경망 설계에서 “거리‑초평면” 접근이 기하학적 일관성을 유지하면서도 효율성을 확보할 수 있음을 증명한다. 이는 하이퍼볼릭 공간을 활용한 계층적 데이터 처리, 그래프 임베딩, 저샷 학습 등에 실용적인 기반을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기