그라디언트 노름을 활용한 기대 개선
초록
본 논문은 베이지안 최적화에서 널리 쓰이는 기대 개선(EI) 획득함수의 과도한 탐욕성을 완화하고, 지역 최적점에 머무르는 문제를 해결하기 위해 그라디언트 노름을 이용한 새로운 획득함수 EI‑GN을 제안한다. 함수값과 함께 그라디언트 관측을 활용해 별도의 보조 목적 g(x)=f(x)−α‖∇f(x)‖²를 정의하고, 이 보조 목적에 대한 기대 개선을 하한으로 근사하여 폐쇄형 식을 얻는다. 실험 결과 EI‑GN이 표준 EI보다 더 다양하고 높은 품질의 해를 찾으며, 제어 정책 학습에도 적용 가능함을 보인다.
상세 분석
이 연구는 베이지안 최적화(BO)에서 획득함수(acquisition function)의 설계가 최적화 성능을 좌우한다는 점에 착안한다. 기존의 기대 개선(EI)은 “현재 최적값보다 큰 함수값을 얻을 확률과 기대값”에만 초점을 맞추어, 탐색 영역이 급격히 축소되고 지역 최적점에 갇히는 현상이 빈번하다. 저자들은 이러한 문제를 해결하기 위해, 함수값뿐 아니라 그라디언트 정보도 활용하는 보조 목적 g(x)=f(x)−α‖∇f(x)‖²를 도입한다. 여기서 α는 그라디언트 노름에 부여하는 가중치이며, α>0이면 그라디언트가 작을수록(즉, 1차 최적조건에 가까울수록) 보조 목적이 높아진다.
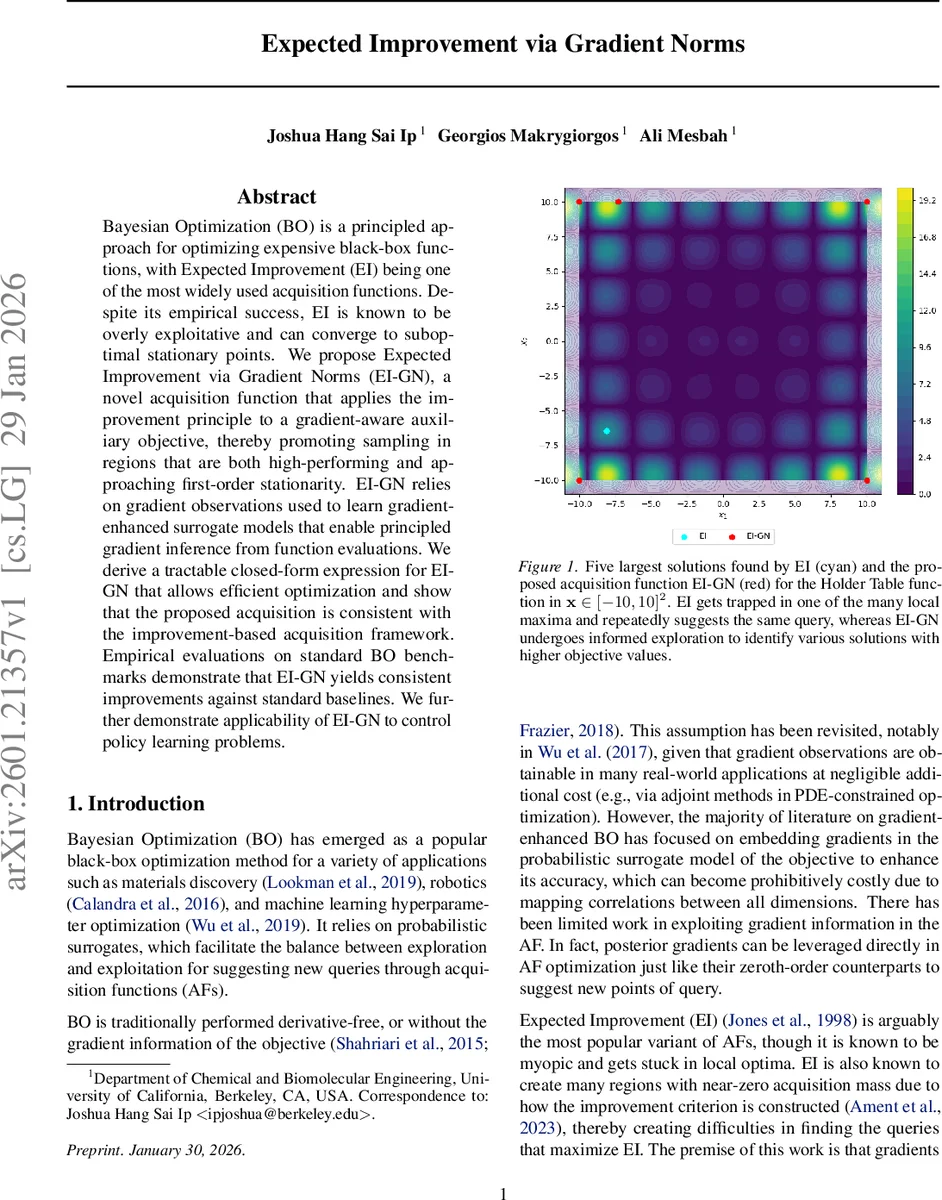
핵심 아이디어는 두 가지 개선 경로를 동시에 고려하는 것이다. (i) 전통적인 EI와 동일하게 함수값이 현재 최적값보다 크게 개선되는 경우, (ii) 함수값은 낮더라도 그라디언트 노름이 현재 incumbent보다 크게 감소하는 경우에도 g(x)−g(x⁺)가 양수가 될 수 있다. 따라서 EI‑GN은 “함수값 개선”과 “정류성(Stationarity) 개선” 두 축을 모두 탐색한다.
수학적으로는 g(x)에 대한 기대 개선 EI_g을 직접 계산하면 함수값과 그라디언트 노름이 결합된 비선형 형태라 폐쇄형 해가 존재하지 않는다. 저자들은 양의 부분 부등식(Positive Part Inequality)을 이용해 EI_g ≥ EI_f − α·EI_s 로 하한을 만든다. 여기서 EI_f는 기존 EI와 동일하고, EI_s는 그라디언트 노름의 기대 개선을 나타낸다. EI_s 자체도 비정형 적분 형태이므로, 평균장(mean‑field) 근사를 도입해 다변량 정규분포의 정규화된 절단(moment) 형태로 변환한다. 이 과정에서 그라디언트 공분산을 대각화하고, Cholesky 분해 L을 이용해 ‖∇f(x)‖²를 일반화된 비중심 카이제곱 변수로 표현한다. 최종적으로 EI‑GN = EI_f − α·EI_s 가 폐쇄형 식으로 얻어지며, 계산 복잡도는 O(N³) 수준으로 기존 GP‑BO와 동등하거나 약간 증가한다.
알고리즘 측면에서는 함수값과 그라디언트를 각각 독립적인 GP로 학습함으로써 f와 ∇f 사이의 교차 공분산을 없애고, 차원 d에 대한 복잡도 의존성을 최소화한다. 이는 고차원 문제에서도 실용적인 실행 시간을 보장한다. 실험에서는 Holder Table, Shekel, Hartmann, Cosine, Griewank, Ackley 등 다양한 합성 벤치마크와 로봇 제어 정책 학습 과제를 사용했으며, EI‑GN이 표준 EI, PI, UCB, 그리고 기존 그라디언트‑강화 BO 방법들보다 평균 최적값이 높고, 탐색 다양성이 향상된 것을 확인했다. 특히 EI‑GN은 초기 탐색 단계에서 그라디언트 노름 감소를 통해 “잠재적 전역 최적점”이 있는 영역을 빠르게 발견하고, 이후 함수값 개선 단계로 자연스럽게 전이한다는 점이 눈에 띈다.
이 논문의 주요 기여는 (1) 그라디언트 정보를 활용해 EI의 탐색‑활용 균형을 구조적으로 개선한 새로운 획득함수 설계, (2) 비정형 기대 개선을 하한으로 변환해 폐쇄형 근사식을 도출한 이론적 분석, (3) 고차원에서도 효율적으로 동작하도록 독립 GP 모델링을 채택한 실용적 구현, (4) 다양한 실험을 통해 기존 방법 대비 일관된 성능 향상을 입증한 실증적 검증이다. 향후 연구에서는 α의 자동 튜닝, 다목표 최적화에의 확장, 그리고 비가우시안 서프라이즈 모델과의 결합 등이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기