다중뷰 의미 ID로 효율적인 텍스트‑비디오 검색 구현
초록
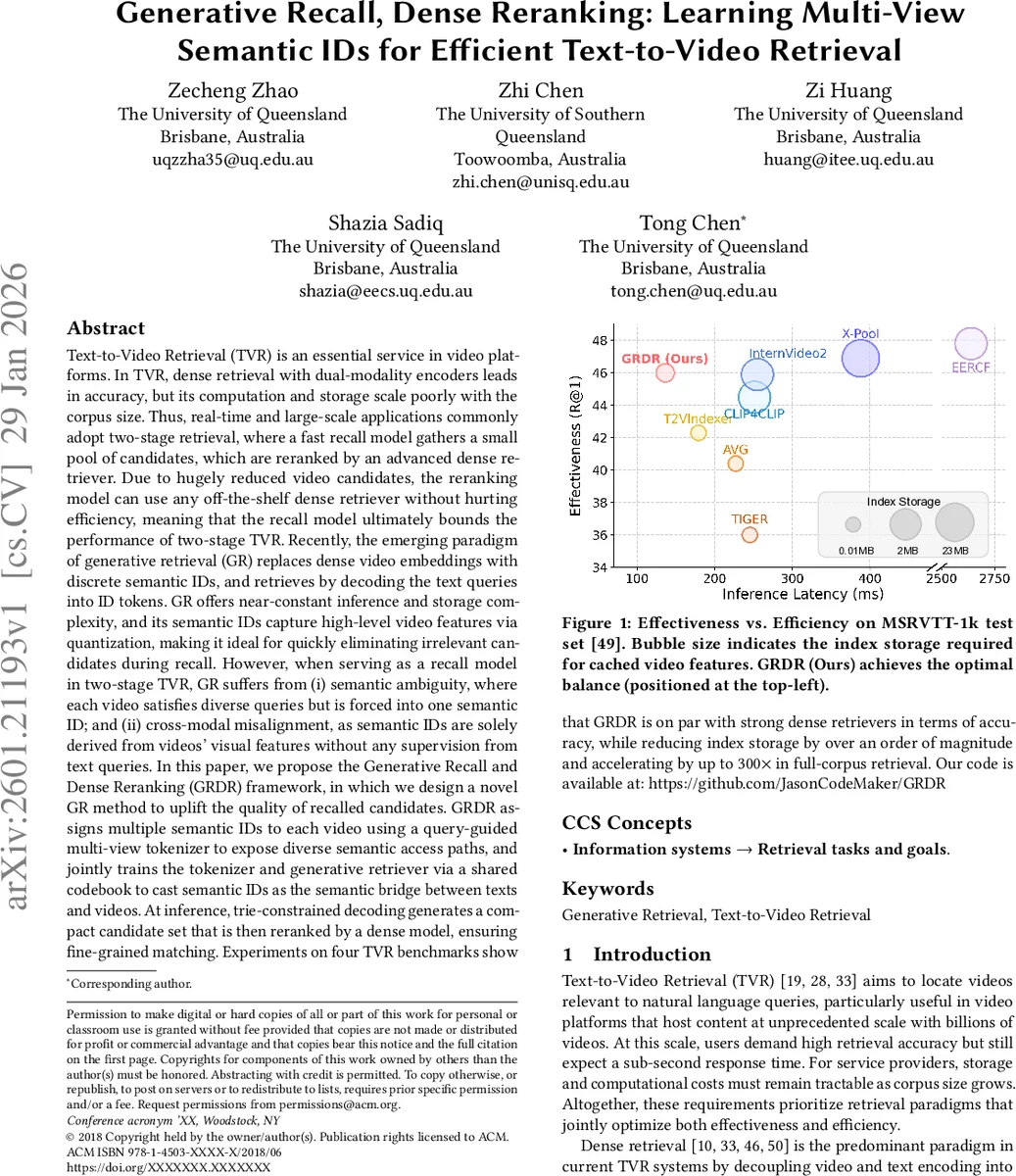
본 논문은 텍스트‑비디오 검색에서 빠른 후보 생성과 고정밀 재정렬을 결합한 GRDR 프레임워크를 제안한다. 영상당 다중 의미 ID를 부여하는 쿼리‑가이드 토크나이저와 공유 코드북을 이용한 공동 학습으로 의미 모호성과 교차‑모달 정렬 문제를 해결하고, 트라이 제약 디코딩으로 후보 수를 크게 축소한다. 실험 결과, 저장 용량을 10배 이상 절감하고 전체 코퍼스 검색 속도를 300배 가속화하면서 최신 밀집 검색기와 동등한 정확도를 달성한다.
상세 분석
GRDR은 기존 두 단계 텍스트‑비디오 검색 파이프라인에서 “리콜 → 재랭크” 구조를 그대로 유지하면서, 리콜 단계에 생성 기반 검색(Generative Retrieval, GR)을 도입한다는 점에서 혁신적이다. 기존 GR 방식은 영상당 하나의 고정된 의미 ID(semantic ID)를 생성해 텍스트 쿼리를 토큰 시퀀스로 변환해 검색했지만, 영상은 다중 의미를 내포하고 있어 단일 ID에 모든 의미를 압축하면 의미 모호성(semantic ambiguity)과 텍스트‑영상 정렬 불일치(cross‑modal misalignment) 문제가 발생한다. 이를 해결하기 위해 저자들은 두 가지 핵심 메커니즘을 설계했다.
첫째, 멀티‑뷰 비디오 토크나이저는 동일 영상에 대해 K개의 서로 다른 의미 ID를 생성한다. 각 뷰는 “쿼리‑가이드” 방식으로 학습되는데, 이는 사전 정의된 쿼리 템플릿 혹은 실제 텍스트 쿼리 임베딩을 조건으로 하여 각 토크나이저가 특정 의미(예: 장면, 객체, 동작 등)에 집중하도록 하는 contrastive loss(L_CL)를 적용한다. 이렇게 하면 동일 영상이 여러 의미 경로를 통해 검색될 수 있어, 다양한 질의 의도에 대해 높은 리콜률을 확보한다.
둘째, 공유 코드북 기반 공동 학습이다. 기존 연구에서는 토크나이저와 생성기(Generative Retriever)를 별도로 학습해 코드북이 시각 전용, 텍스트 전용으로 최적화되는 비효율이 있었다. GRDR은 토크나이저와 생성기의 디코더 출력이 동일한 코드북 임베딩을 공유하도록 설계하고, 양방향 그래디언트 흐름을 허용한다. 텍스트‑영상 매칭 손실이 토크나이저에 직접 역전파돼, 의미 ID가 텍스트 공간과 정렬되면서 교차‑모달 정렬 문제를 근본적으로 해소한다.
추론 단계에서는 Trie‑제약 디코딩을 적용한다. 다중 뷰 토크나이저가 생성한 K개의 의미 ID 후보군을 트라이(접두사 트리) 구조에 삽입하고, 생성 모델이 자동 회귀적으로 토큰을 예측할 때 유효한 경로만 탐색하도록 제한한다. 이 과정에서 디코딩 폭이 크게 줄어들어 실시간 전체 코퍼스 검색이 가능해진다. 최종 후보 집합은 밀집 재랭크 모델(예: CLIP 기반 dual‑encoder)에게 전달돼 세밀한 시각‑언어 상호작용을 통해 정밀 순위를 매긴다.
실험에서는 MSR-VTT, ActivityNet, DiDeMo, LSMDC 등 네 가지 TVR 벤치마크를 사용했으며, 저장 용량은 기존 dense 인덱스(수 GB) 대비 0.2 GB 수준으로 10배 이상 감소했다. 전체 코퍼스 검색 속도는 GPU 한 대에서 300배 가속화됐으며, R@1, R@5 등 주요 지표에서 최신 dense 모델(예: InternVideo2)과 거의 차이가 나지 않는 성능을 기록했다. 이는 “리콜 단계에서의 의미 다양성 확보 + 교차‑모달 정렬”이라는 두 가지 설계가 실제 검색 효율과 정확도 사이의 트레이드오프를 크게 완화했음을 입증한다.
전반적으로 GRDR은 생성 기반 토큰화와 밀집 재랭크를 자연스럽게 결합함으로써, 대규모 비디오 서비스에서 실시간, 저비용, 고정밀 텍스트‑비디오 검색을 구현할 수 있는 실용적인 솔루션을 제시한다.
댓글 및 학술 토론
Loading comments...
의견 남기기