출력공간 탐색으로 LLM 제어하기
초록
본 논문은 고정된 인코더가 정의한 3차원 출력공간 Z에 목표점 z*를 지정하고, 검색 기반 정책을 시퀀스‑레벨 강화학습으로 학습시켜 LLM이 해당 좌표에 가깝게 텍스트·코드를 생성하도록 하는 OS‑Search 방식을 제안한다. 이를 통해 토큰‑레벨 경로 탐색 없이 외부 루프에서 병렬 스위프와 블랙박스 최적화를 수행한다. 스토리 분야에서는 다양성 3.1배 향상을, 코드 분야에서는 베이지안 최적화를 통한 목표 함수 개선을 입증한다.
상세 분석
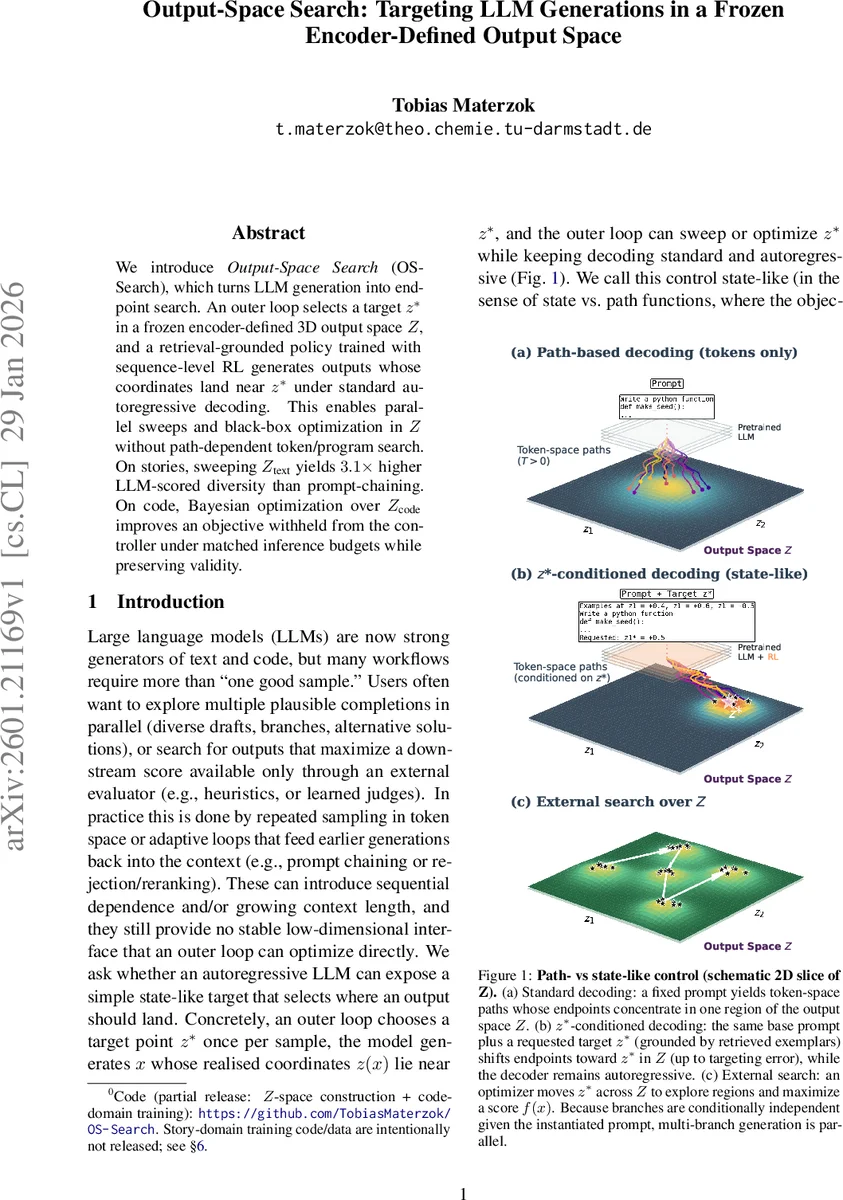
OS‑Search는 LLM 생성 과정을 “끝점 탐색” 문제로 전환한다는 근본적인 아이디어에서 출발한다. 먼저 사전 학습된 인코더 E와 고정된 선형 투사 U를 이용해 텍스트·코드 샘플 x를 저차원 좌표 z(x)∈ℝ³ 로 매핑한다. 이 좌표계는 도메인별 코퍼스에 대해 PCA와 Varimax 회전을 적용해 구축되며, 스토리 실험에서는 추가적인 앵커(z₁)로 기본 스타일을 정렬한다. 외부 루프는 목표점 z를 선택하고, 내부 정책 πθ는 “z‑조건부” 프롬프트에 따라 샘플을 생성한다. 프롬프트에는 z와 근접한 예시 (x₁, z(x₁)), (x₂, z(x₂))와 반대쪽 예시 (x₃, z(x₃))가 포함되어, 모델이 좌표 의미를 직관적으로 파악하도록 돕는다. 정책은 Qwen‑3‑1.7B 기반에 QLoRA 어댑터를 추가해 미세조정되며, 그룹‑상대 정책 최적화(GRPO)와 시퀀스‑레벨 보정(GSPO) 기법을 사용한다. 보상 함수는 (1) 형식·유효성 검증 R_format, (2) 목표 거리 R_dist (좌표가 z에 가까워질수록 보상 증가), (3) 자기 보고 정밀도 R_hon (모델이 보고한 ˆz와 실제 z(x)의 차이를 최소화)으로 구성된다. 이렇게 학습된 정책은 입력 프롬프트 p와 목표 z만으로 자동으로 텍스트·코드를 생성하고, 자체적으로 ˆz를 출력한다. 실험에서는 스토리 도메인에서 Z 텍스트를 격자 탐색해 20개의 프롬프트에 대해 3.1배 높은 LLM‑점수 기반 다양성을 달성했으며, 코드 도메인에서는 Z 코드를 활용한 베이지안 최적화가 사전 정의된 실행 목표를 향상시키면서도 100% 유효한 프로그램을 유지했다. 이 접근은 토큰‑레벨 샘플링에 비해 외부 루프가 독립적으로 병렬 실행될 수 있어 계산 효율성을 크게 높인다. 또한 좌표 z가 저차원 연속값이므로 기존의 고차원 프롬프트 엔지니어링이나 라티스 기반 제어보다 직관적이고 안정적인 사용자 인터페이스를 제공한다. 한계로는 좌표 공간이 고정 인코더에 의존하므로 인코더 업데이트 시 재구성이 필요하고, 현재 d_z=3 이라는 제한이 복잡한 제어 요구를 충분히 표현하지 못할 가능성이 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기