흐름 기반 비전 언어 액션 모델을 위한 온라인 강화학습 미세조정
초록
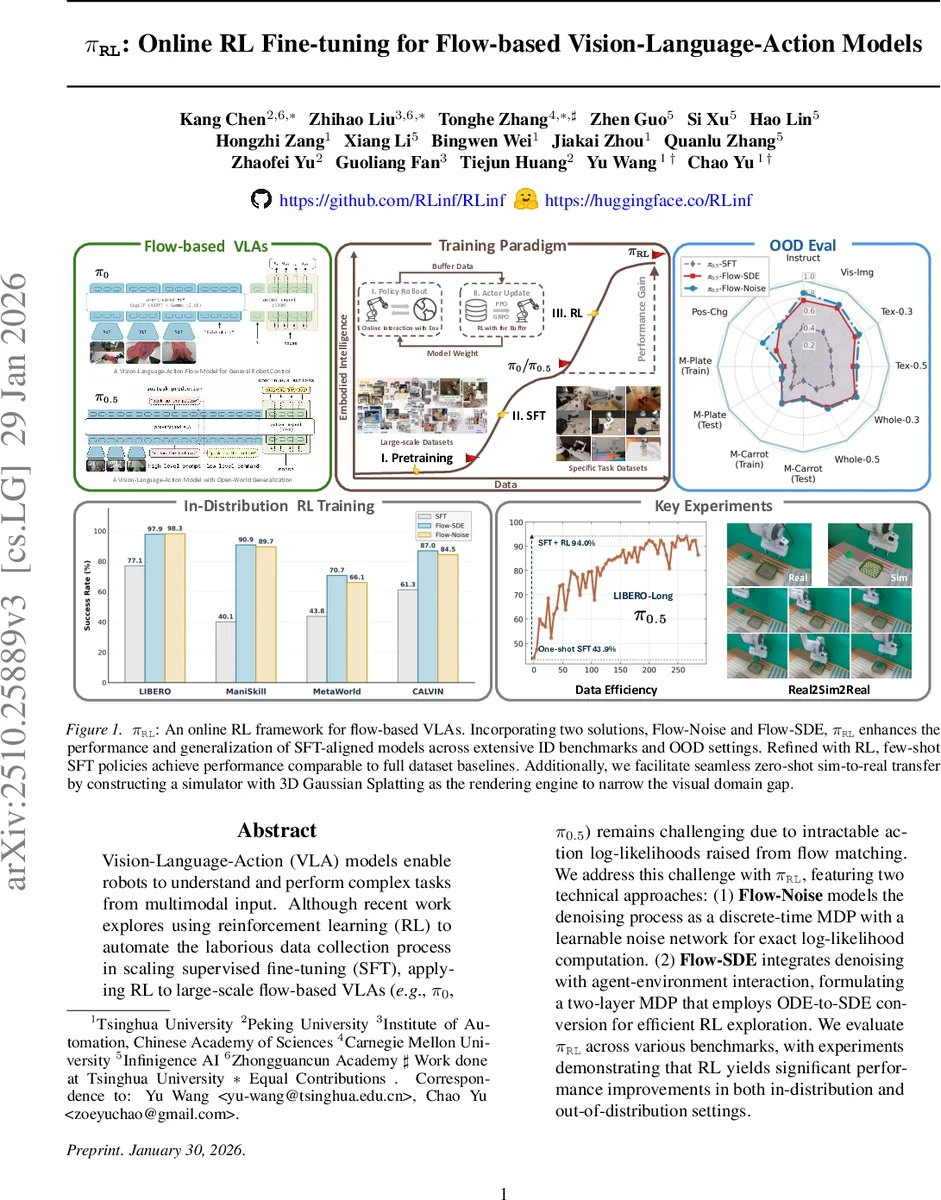
π_RL은 흐름 매칭으로 동작을 생성하는 VLA 모델에 강화학습을 적용하기 위해 두 가지 기법, Flow‑Noise와 Flow‑SDE를 제안한다. 이 기법들은 정확한 로그우도 계산과 탐색 효율성을 제공해, 기존 SFT 기반 모델을 인‑도메인·아웃‑도메인 모두에서 크게 향상시킨다.
상세 분석
본 논문은 최근 급부상한 흐름 기반 Vision‑Language‑Action(VLA) 모델(π₀, π₀.₅ 등)의 핵심 한계인 “액션 로그우도 계산의 비정형성”을 해결하고, 이를 강화학습(RL) 프레임워크에 자연스럽게 통합한다는 점에서 의미가 크다. 첫 번째 제안인 Flow‑Noise는 기존 흐름 매칭 과정에 학습 가능한 노이즈 네트워크를 삽입해, 디노이징 단계를 이산 시간 마코프 결정 과정(MDP)으로 재구성한다. 이때 전이 확률 p(A_{τ+δ}|A_{τ})를 평균 μ_{τ}=A_{τ}+v_{τ}·δ, 공분산 Σ_{τ}=diag(σ_{θ’}^{2})인 가우시안으로 명시함으로써 전체 디노이징 시퀀스에 대한 정확한 로그우도 log π(A|o)=∑{k}log π(A{τ_{k+1}}|A_{τ_{k}},o) 를 얻는다. 로그우도가 정확히 계산되면 정책 그래디언트 식(2)에 그대로 대입할 수 있어, 기존 흐름 기반 모델이 갖던 “우도 추정 불가능 → 정책 업데이트 불가” 문제를 근본적으로 해소한다.
두 번째 제안인 Flow‑SDE는 ODE 기반 디노이징을 확률적 미분방정식(SDE)으로 변환한다. ODE의 드리프트 v_{τ}에 스코어 함수 ∇log q_{τ}(A_{τ})를 연결하고, 가변 스케줄 g(τ)·dW_{τ} 형태의 확산 항을 추가함으로써 동일한 주변분포를 유지하면서 탐색성을 크게 높인다. 이 SDE를 이산화하면 전이 확률이 μ_{τ}=A_{τ}+h·v_{τ}+σ_{τ}^{2}/(2τ)(A_{τ}+(1-τ)v_{τ})·δ, Σ_{τ}=σ_{τ}^{2}·δ·I인 등방성 가우시안이 된다.
Flow‑SDE는 내부 디노이징 MDP와 외부 환경 MDP를 2‑layer 구조로 결합한다. 내부 MDP는 τ∈
댓글 및 학술 토론
Loading comments...
의견 남기기