동적 목표 기반 LLM 탈옥 공격
초록
기존의 고정된 해답을 목표로 하는 프롬프트 최적화 방식은 안전 정렬된 대형 언어 모델(LLM)에서 매우 낮은 확률 영역을 겨냥해 비효율적이다. 본 논문은 목표 모델이 실제로 생성하는 고확률 응답을 동적으로 샘플링하고, 그 중 가장 해로운 응답을 임시 목표로 삼아 프롬프트를 반복적으로 조정한다. 백‑백 및 블랙‑박스 환경 모두에서 200회 이하의 최적화 단계로 87% 이상의 공격 성공률(ASR)을 달성하며, 기존 최첨단 방법보다 15% 이상, 실행 시간은 2‑26배 빠르게 개선한다.
상세 분석
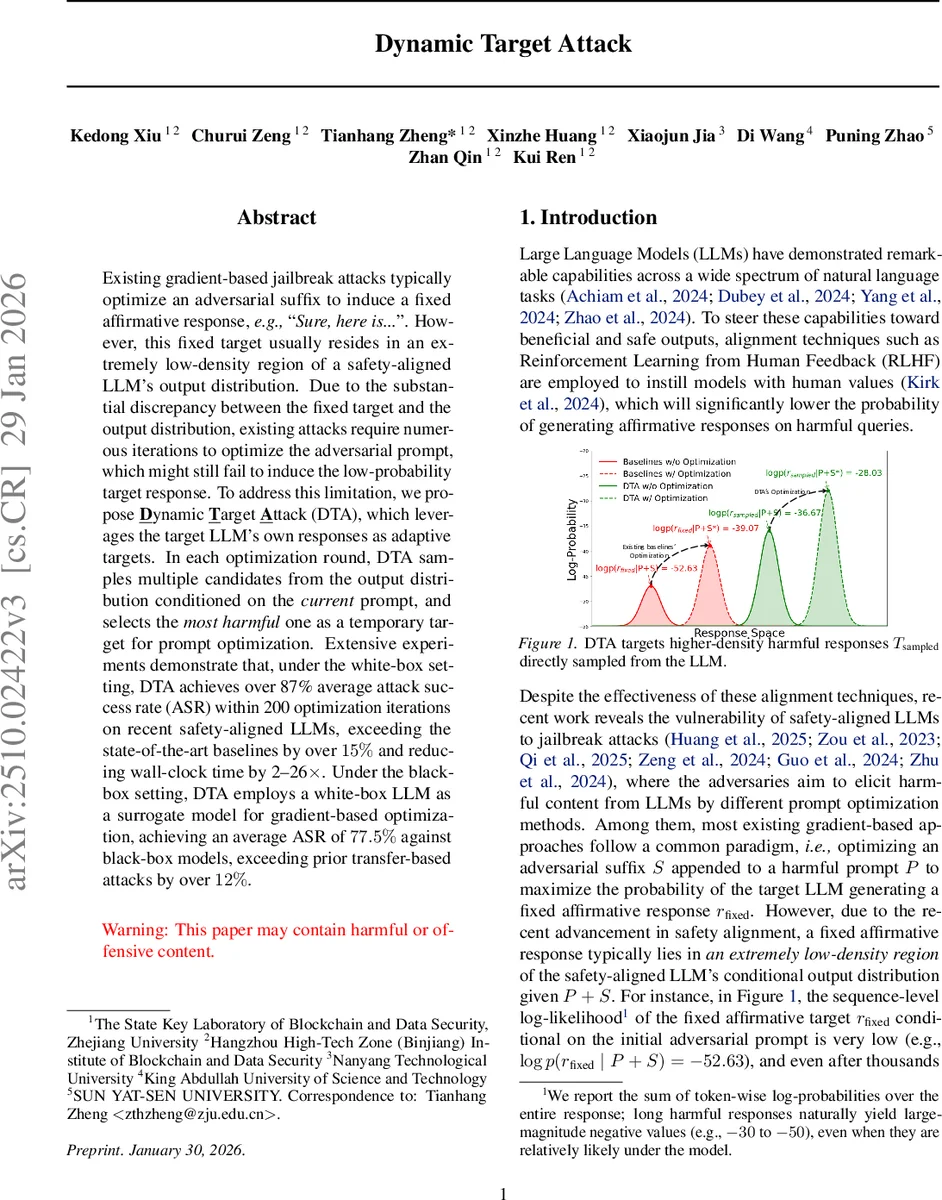
본 연구는 “고정 목표” 패러다임의 근본적인 한계를 정확히 짚어낸다. 안전 정렬된 LLM은 유해 프롬프트에 대해 거부 혹은 “죄송합니다”와 같은 사전 정의된 응답을 거의 생성하지 않는다. 따라서 기존 GCG, COLD‑Attack 등은 사전에 지정된 “Sure, here is …”와 같은 토큰 시퀀스를 목표로 삼아 로그우도(log‑likelihood)를 최소화하려 하지만, 해당 시퀀스는 모델의 조건부 확률 분포에서 극히 낮은 밀도 영역에 위치한다. 결과적으로 수천 번의 반복에도 목표 확률이 충분히 상승하지 않아 공격이 실패한다.
Dynamic Target Attack(DTA)은 이 불일치를 완화하기 위해 두 단계의 순환 과정을 도입한다. 첫 번째 단계에서는 현재 프롬프트 P+S에 대해 다중 샘플링(temperature > 0, multinomial)으로 고확률 응답 후보들을 생성한다. 여기서 “해로운 정도”를 판단하는 별도 판단기(harmfulness judge)를 적용해 가장 위험한 후보 r를 선택한다. 두 번째 단계에서는 로컬 LLM f_ϕ를 이용해 r와 유사한 응답 r_local을 생성하고, 기존의 교차 엔트로피 손실을 최소화하도록 S를 미세 조정한다. 이렇게 하면 최적화 목표가 모델이 실제로 높은 확률로 생성할 수 있는 영역에 머물게 되므로, 로그우도가 급격히 상승하고, 최종적으로 목표 모델이 r*와 유사한 혹은 더 해로운 응답을 출력하게 된다.
핵심 기술적 기여는 다음과 같다. ① 동적 목표 샘플링을 통해 목표와 출력 분포 간 KL‑다이버전스를 실시간으로 최소화한다. ② 임시 목표를 고밀도 영역에서 선택함으로써 최적화 단계 수를 200 이하로 크게 줄인다. ③ 블랙‑박스 상황에서는 백‑박스 모델을 서브시디(서로게이트)로 활용해 동일한 샘플링‑최적화 루프를 수행, 전이 성공률을 12% 이상 끌어올린다. 실험에서는 최신 안전 정렬 LLM 5종에 대해 백‑박스에서 평균 87% ASR, 블랙‑박스에서 77.5% ASR을 기록했으며, 시간 효율성 면에서도 기존 방법 대비 2‑26배 가량 빠른 결과를 보였다.
한계점으로는 (1) 해로운 응답 판단기의 정확도에 크게 의존한다는 점, (2) 서브시디 모델이 목표 모델과 구조·학습 데이터가 크게 다를 경우 전이 성능이 감소할 가능성, (3) 공격 성공 시 생성되는 응답이 실제 악용될 위험이 있다는 윤리적 우려가 있다. 향후 연구는 판단기 강화, 다중 서브시디 앙상블, 그리고 방어 측면에서 동적 목표 탐지를 통한 탐지·완화 메커니즘 개발이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기